00:00:13.200
My name is Simon, and I work on the infrastructure team at Shopify. Today, I’m going to talk about the past five years of scaling Rails at Shopify. I've only been with Shopify for four years, so the first year was a bit of digging into the past. However, I want to discuss all the lessons we've learned, and I hope people in the audience can place themselves on this timeline and learn from the experiences we've had over the past five years. This talk is inspired by Jeff Dean from Google, who is a genius. He gave a talk about how they scaled Google in its early years, showing how they moved away from using MySQL databases to NoSQL paradigms and eventually to new SQL paradigms. I found it fascinating to see why they made the decisions they did at that point in time.
00:00:44.480
I have always been curious about how companies like Facebook decided to create their virtual machines for PHP to improve performance. This talk will be an overview of the decisions we've made at Shopify, rather than delving into the very technical aspects of each decision. I aim to give you an understanding and a mental model of how we evolved our platform. There is extensive documentation available on everything I'm going to cover today, including talks by coworkers, blog posts, and Readme files.
00:01:10.159
Shopify allows merchants to sell products to consumers, which is crucial for this discussion. We have hundreds of thousands of merchants relying on Shopify for their livelihood, managing nearly 100,000 requests per second at peak times. During the largest sales events, our Rails servers face almost 100,000 requests per second, while our steady state operates around 20,000 to 40,000 requests per second. We run this on tens of thousands of workers distributed across two data centers. It's important to note that around $30 billion in sales have passed through our platform, so any downtime is costly.
00:01:59.880
Keep in mind that these metrics roughly double each year. If you look back five years, you would divide those figures by two, five times. I would like to introduce some specific vocabulary related to Shopify since I will be using these terms loosely in this talk to help you better understand how Shopify works. Shopify has at least four sections: the storefront, which is where people browse collections and products, adding items to their cart. This section accounts for the majority of traffic, roughly between 80% to 90%. Then there's the checkout section, where the process becomes more complex. We can't cache it as heavily as the storefront because it involves actions like inventory decrements and payment captures.
00:02:57.200
The admin panel is even more complex as it entails managing actions for hundreds of thousands of orders simultaneously. For example, users might be updating details for these orders in real-time. The API allows actions to be taken in the admin section; in this case, computers interact with the API at high speeds. Recently, I discovered an app that generates one million orders and then deletes them, showcasing how some developers use this API in extreme ways. Consequently, our API is our second-largest source of traffic after the storefront.
00:03:33.200
I want to discuss a philosophy that has shaped our platform over the past five years: flash sales. Flash sales have significantly influenced Shopify's development. When a prominent artist like Kanye West wants to release an album on Shopify, my team is quite apprehensive. Five years ago, we established a critical moment when we began to notice certain customers who could generate more traffic during their sales than our platform could handle overall. These sales would see spikes up to 5,000 requests per second within mere seconds when they launched at 2 p.m.
00:04:34.240
At that moment, we faced a decision: should we become a platform that supports these intense sales, or should we throttle them and say, 'This isn't the right place for you'? While it would have been reasonable to adopt the latter approach, as 99.9% of our stores don't experience this traffic pattern, we chose to support these flash sales. We formed a specialized team to address the challenges posed by customers capable of directing significant traffic in a short span. This became a pivotal decision, serving as a canary in the coal mine for flash sales.
00:05:07.080
We started observing how our infrastructure held up and it helped us see where we were headed. For instance, we've handled up to 80,000 requests per second during these sales. Preparing for these sales allows us to anticipate our traffic demands for the following year, enabling us to maintain a proactive stance in managing growth.
00:06:21.560
In the core of this talk, I’ll detail the key infrastructure projects we executed over the last five years. While many other projects and initiatives were undertaken, this session focuses on the most significant efforts in scaling our Rails application.
00:06:36.599
In 2012, we determined to pursue an antifragile strategy for handling flash sales. Our goal was to establish Shopify as the premier platform for flash sales. Consequently, a dedicated team was formed whose primary objective was to ensure that the Shopify application remained operational and responsive under these demanding situations. The first step in optimizing an application is to identify the low-hanging fruit, which can vary significantly depending on the application. From an infrastructure standpoint, lower hanging fruit is typically found and addressed with load balancers and operating systems.
00:07:32.840
However, our responsibility was to truly understand our problems, which involved knowing where our biggest opportunities for improvement were. Our initial focus targeted high-impact areas like backgrounded checkouts. Some might wonder how backgrounded jobs weren't already in use, but the application had existed since 2004 and the practice of backgrounding jobs in Ruby or Rails was not commonplace at that time. Consequently, we faced a significant amount of technical debt.
00:08:41.480
In 2012, a specialized team set out to move the checkout process to background jobs so that payment captures could occur asynchronously rather than during long-running requests. This dramatically improved our application's speed and efficiency. Another challenge we faced was managing inventory during high-traffic situations. The common perception might be that inventory management is merely about decrementing a number quickly for thousands of users. However, MySQL is not engineered to handle multiple queries trying to decrement the same number simultaneously due to lock contention.
00:09:58.720
These were just two of the many problems we encountered and solved. In general, we printed out the debug logs of every single query affecting key paths like the storefront, checkout, and other essential routes, and then we methodically checked them off. I remember seeing a photo from a presentation three years back depicting the board where our debug logs were tracked, capturing the progress our team made in identifying and reducing bottlenecks.
00:10:52.520
We understood that we needed a tighter feedback loop; we couldn't afford to wait for each flash sale to discover if our optimizations were effective. Thus, we created a load-testing tool designed to simulate a user’s checkout experience. This tool would navigate the storefront, browse products, add items to the cart, and perform a complete checkout process, all while thousands of these simulations ran concurrently to gauge performance improvements.
00:12:40.480
Integrating this load testing tool into our infrastructure became standard practice. Now, whenever someone implemented a performance change, their colleagues would ask about the results of load testing. This became crucial to our approach because simple requests directed at the storefront were no longer deemed representative of realistic performance testing.
00:13:24.920
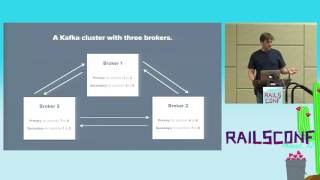
We also developed a library called Identity Cache to help address another significant challenge. At that time, one MySQL database supported tens of thousands of stores, making us very protective of it. Given the substantial traffic influx to our databases during sales events, we needed an efficient way to reduce load. Typically, one would route queries to read slaves to distribute the load, but we faced numerous challenges with this back then.
00:14:16.889
We had implemented several measures to manage read slaves without facing data corruption issues or mismanagement. Consequently, our development team, all Rails developers, had to adopt an infrastructure development mindset, learning about SQL intricacies on the job. Fortunately, an established idea within Shopify was the Identity Cache, a means of managing cached data out of the database line, allowing us to read directly from the cache as long as we respected certain guidelines.
00:15:40.240
With the advent of Identity Cache, we developed a strategy that allowed findings to be read from our managed cache when data was available and to retrieve it from the database only when necessary. While implementing it, we recognized drawbacks, especially concerning aged or stale cache data. This implementation’s challenge lies in ensuring the integrity of the cache while managing expired or old data.
00:16:43.360
Moving into the end of 2012, we faced what could have been the worst Black Friday-Cyber Monday ever. Our team was working tirelessly during that time, leading to one of our more infamous moments: our CTO face-planting in exhaustion. However, the deployment of identity cache and proactive load testing ultimately yielded success through our optimization efforts, allowing us to survive those peak sales without significant issues.
00:17:40.480
After decompressing from that high-stress period, we questioned how we could avoid a similar situation in the future. Despite spending considerable time optimizing checkout and storefront functionalities, we recognized that sustainable practices were necessary. Continuous optimization can result in inflexibility, where adding features leads to additional complex queries impacting overall performance negatively.
00:18:34.640
Once you optimize for speed, you often sacrifice flexibility—similar to how changing an algorithm can impact its adaptability. Thus, we realized we needed to re-architect certain aspects of our infrastructure. As a result, we explored sharding to regain flexibility after realizing we needed to manage the large volumes of writes due to traffic from sales effectively.
00:19:37.960
With sharding, we isolated each shop's data, ensuring that one shop's operations wouldn't interfere with another's. The sharding API we built prevents a query from reaching across shards, making it impossible for one shop's actions to affect another. Importantly, developers only rarely need to consider sharding in practice, as the infrastructure automatically routes requests accordingly.
00:20:31.560
While this architectural change introduced challenges, such as restricted actions like cross-shop joins, we found workarounds and alternative methods to accomplish what we needed. However, we maintained a clear principle that shops should operate independently. Shopify’s architecture can be demanding, but we learned through trial and error how to adapt effectively.
00:21:52.720
Our focus on resilient systems became increasingly paramount in 2014 due to the rise in failures, arising from the greater complexity. As our components multiplied, outages became frequent. A failure in one shard adversely affected requests routed to other shards. It didn’t seem logical that a single Redis crash could bring down all of Shopify, akin to a chemistry reaction where exposure relates to surface area indicates failure probability.
00:23:40.320
We discovered that when one component failed, it could lead to failures across numerous parts of the system. As a result, we conceptualized the need for high availability and examined our resiliency matrix thoroughly. Mapping out vital dependencies and modeling out failures and their impact resulted in clearer insights necessary for creating a robust infrastructure.
00:24:50.640
Realizing how rapidly certain components could derail overall performance prompted us to adopt effective incident response practices aimed at alleviating disruption within our services. The matrix offered an ongoing learning experience, revealing critical relationships we needed to address to build better reliability into our systems. As performance tests became part of our routine, we gained important insights contributing towards improved operation efficiency.
00:25:53.920
With substantial groundwork laid out across prior years, we continuous sought refinement. By the end of 2015, fluency in managing data traffic across sites led to launching multi data center support. Our design integrated two operational data centers capable of hosting functions autonomously, resulting in a more effective infrastructure strategy that enables seamless failovers between centers.
00:27:00.920
Now, when one data center experiences outages, services reroute seamlessly to the others with processes scripted to facilitate swift transition. Our dual data center platform design empowered us to load-balance traffic efficiently across both locations. The architecture grew robust against failures while ensuring users faced minimal impact throughout high-volume operations as we integrated feedback and continual improvement efforts into system design.
00:28:22.080
As a result, requests hitting the nearest data center now can be automatically routed to whichever center is active. Introducing the concept of ‘Pods,’ we ensured that each site could execute independently ensuring they hosted all components necessary for comprehensive operation, solving many single points of failure we previously faced. This approach allowed us to flexibly manage overwhelming traffic spikes without adversely impacting service quality.
00:29:34.960
Ensuring independence between these pods further prevented over-utilization, creating a more balanced distribution of workload during high-demand periods. With proper traffic routing through a centralized ‘Sorting Hat’ system, we expertly controlled volume flows ensuring proper load management across all services under our infrastructure.
00:30:48.180
The guiding principles of our architecture indicate that each request must be annotated with proper assignments while preventing disproportionate access between shared pools. Our collaboration resulted in several coding revisions preventing destructive violations of our intended operations while ensuring we could maintain manageable workloads under peak traffic conditions.
00:32:53.560
With all these adjustments, we culminated this journey by generating 880,000 requests per second effectively from multiple data centers, demonstrating not only the scalability of our infrastructure but also our capacity to adapt proactively. Thank you for accommodating my discussion today.
00:34:06.520
Do you have any global data that doesn’t fit into a shard? Yes, we do have a central 'master' database to handle global information pertaining to our shelves, such as merchant model data, essential for load balancing.
00:34:16.040
Furthermore, complex billing data spans multiple pots affecting revenue critical to our partnerships. From my experience, I dedicated a time addressing this issue, alongside my team, and ensured we created a durable master database that can operate across several data environments which ultimately were partitioned and ensured high-efficiency among our service components.
00:35:21.600
To summarize how we address high-volume operations, we maintain capacity across diverse data resources through carefully structured frameworks that isolate units across distributions of processing which ultimately drives reliability in deployments. Ensuring manageable loads enables our tacking with customer systems meaning downtime is minimized.