00:00:00.000
It's still amazing to think about what software can do. For example, if you have a self-driving car, the visual subsystem of a self-driving car can take pictures, such as a picture of a road, and identify items of interest like other vehicles and pedestrians. It can do that in a fraction of a second. But if I were to write software that does this, I wouldn't know how to do it. It simply looks astounding, and that's why I want to talk about deep learning.
00:00:12.300
This talk is for people who don't know about deep learning. If you already know about machine learning or deep learning, then this will probably be too basic for you; in that case, I won't be offended if you leave. However, if you don't know much or anything at all about these topics, then this is probably for you. It's going to be a bit high-level; I'm not going to go into many technical details because that would take too much time. But it also means that if you don't understand a few technical details, that's intentional. You don't have to watch it the same way you watch National Geographic documentaries; you don't have to become a biologist to enjoy the animals. This is a documentary about deep learning.
00:01:03.340
Let me suggest that it's not magic—it's just technology. That's my goal today. Let's start from the basics: supervised learning, which is the foundation of deep learning. Supervised learning is about essentially matching data, matching input to some kind of output. The input and output can be many different things. For example, if the input is a picture of an animal and the output is the name of the animal, then you have a system that recognizes pictures of animals and names. How can this system ever know that we are looking at a duck? I mean, I know it is a duck, but how does the system recognize it? The idea of supervised learning is that the system knows because I provided the system with many examples.
00:01:40.680
Before I can even think about building such a system, I have to collect examples of animal pictures and their corresponding names. I need both the input and the output, and I need many examples—likely hundreds of thousands. It doesn't hurt if there are millions. I collect a lot of examples, and then I pass these examples to an algorithm that processes them over and over again until it understands the relationship between the picture of an animal and the name of the animal. This is called the training phase, which is the slow and costly phase. Then there comes a second phase where you get your 'money back'—the prediction phase. During this phase, you simply show the picture of an animal to the algorithm, and it tells you what kind of animal it is.
00:02:30.660
That's just one example, but the input and output can be many different things. Yes, it could be pictures and names of animals, but they can also be something more complex. For instance, if your input is English sentences and your output is Japanese, and you're using a system sophisticated enough to understand that, then congratulations—you've just built something like Google Translate. Or the input could be a picture of a road, and the output could be the positions of other vehicles. That's the general idea at a very abstract level. Let's explore one level deeper.
00:04:03.000
Let’s say I have a solar panel on my roof, and I want to predict how much power it generates during the day. The input would be the time of day, and the output is the power generated by the solar panel. I collect examples and plot these on a chart. I have time of day and the power generated and, say, I get this cloud of dots. Now, I pass these examples to a supervised learning algorithm. The algorithm looks at this complicated cloud of examples and approximates them with something simpler, perhaps a function that resembles this. Once you have this simpler explanation of what is happening, you can forget about the examples entirely; you can just use this function to predict the future. For example, at noon, how much power am I going to generate? It might tell me 260.
00:05:05.420
This is the core idea of supervised learning and ultimately deep learning: it finds a function that approximates the examples you give it, and it simplifies complicated real-world things, using that simpler model to predict the future. Let's go one level deeper by examining the specifics of this process using a simple case called linear regression. Let's say I collect examples for a problem where I have a restaurant. I track the reservations in the afternoon and see how many pizzas I sell at night. I want a system that forecasts how many pizzas I will likely sell based on the number of reservations I received today. This situation is straightforward because the dots I plot are roughly in a line, allowing me to approximate it with that line.
00:06:25.460
It's not perfect, but predicting pizzas doesn’t require super precision—it looks good enough. The reason I say this is lucky is that the line has a simple equation I can use to implement in software. Each country calls those parameters by different terms, but I simply refer to them as A and B. So a line is just two parameters: one for the slope (how steep the line is) and another for where the line intersects the vertical axis. The critical part is that with these two parameters A and B, I can use the line to predict the future—for instance, if I have a certain number of reservations, I can compute how many pizzas I can expect to sell.
00:07:14.960
Prediction is the easy part, but finding the line represents the challenge. How do I find the line that approximates these points? I wish I had 20 extra minutes to explain exactly how that works, but let me give you the basic idea. Any line I find will be an approximation, so if I ask the line how many pizzas I am likely to sell based on 14 reservations, it might suggest something like 28 pizzas. But if I compare it against the real-life cases, where I had 1,400 reservations, I might have seen a different number of pizzas sold. Thus, there is a distance between predicted and actual values, and that small orange snack represents an error.
00:08:52.540
The idea is that if I average the error over all examples, I get the total error of the line. The algorithm starts from any line and tries to reduce that error until it achieves the lowest possible error it can find, or until it decides to stop because it’s taking too long. So now we can be more precise: supervised learning is about approximating examples by starting with a random function and tweaking it until obtaining the lowest possible error. This is linear regression, which means approximating data using a line.
00:10:00.020
However, the more complex cases of deep learning work similarly; it’s just a more complex function at play. Let's recap, as I realize this is a lot of information. I have real-world data I want to approximate with a line, which has two parameters (A and B). To find those parameters, I use the error of the line, aiming to minimize that with an algorithm. Once I have this line, I can use it to predict outcomes.
00:11:13.340
Visually, this system can be depicted as a box with the equation of the line that takes X (the number of reservations) and outputs the number of pizzas. Here’s some Ruby code that implements this concept. Unfortunately, I don't have time to linger on the code, but I can assure you it’s not very long or complicated. I’m using this new numerical library that features a powerful array type. This prediction code and the training code—wherein I ultimately find A and B—are also concise. The training code starts with two random or zero parameters and iterates for a while until it identifies the best parameters.
00:12:25.070
I also load data, train the system for an arbitrary number of iterations to find good values for these parameters, and inquire, 'If we have 25 reservations, how many pizzas can we expect to sell?' I then draw a chart that displays the original data alongside the approximating line, allowing a visual check on whether the predictions align with expectations. When I run this model, you can observe the iterations taking place.
00:13:09.380
The number is gradually dropping, indicating the error, known as 'loss' in machine learning—just some terminology from the field—will show that after 10,000 iterations, it discovers these two parameters. It then tells us that for 25 reservations, we can expect to sell about 40 pizzas. It also outputs a small chart illustrating the examples and the approximating line.
00:13:52.510
This is a clear example, but we are still far from implementing something capable of recognizing images, for instance. We need to add a couple more complexities to this system to enhance its power. I'll go through these quickly without diving too deep into technicalities. One of the main considerations is that most real-world problems aren't this simple. My pizza sales don’t depend on a single variable; they depend on multiple aspects, such as temperature or the number of people in the area.
00:14:50.620
So, what happens when I have multiple inputs instead of just one? For a single input variable, I can create a 2D chart that approximates a cloud of examples with a line. If I have two input variables, such as reservations and temperature, then the chart becomes 3D, and I cannot use a single line anymore; I must use a plane to define my prediction. This means the equation for a plane requires three parameters instead of two. As I continue to add dimensions, the parameters increase as well, and while I may not be able to visualize them, I can still abstract the problem into a more manageable form.
00:16:00.040
If I assemble the inputs accordingly, those parameters A and B turn into multiple parameters. To simplify, let's just cluster these parameters into a single array and refer to it as W for weights—a common term in machine learning. This leads to what is called a linear combination of inputs, essentially forming a matrix multiplication, scaling with the number of parameters. At the end of this process, you still get a prediction.
00:16:45.450
Now, let’s introduce a second complexity. In many interesting problems, I’m not trying to predict merely a number; I’m predicting a set of outcomes. For instance, instead of asking how many pizzas am I going to sell, I could question whether I will reach breakeven or profit today. Here, the result is either 0 (no profit) or 1 (profit), or a figure between them to denote uncertainty, such as 0.7 indicating a high chance of profit. To achieve this, I can introduce a function that processes any output from the model and compresses it back into a range between 0 and 1.
00:18:30.810
This function could vary based on the problem at hand. For instance, in predicting animal recognition, I could deploy boolean classifiers for each potential animal. They will analyze the same image and yield values between 0 and 1. In our example, a duck classifier might show a low value, suggesting it's not a duck, while a cat classifier indicates a higher probability, reflecting its inclination to identify that image as a cat.
00:19:20.410
Now, I can merge these classifiers into a cohesive system. When I say 'classifiers,' I'm not suggesting that they operate entirely independently; I run similar code through them. I simply expand the dimensions of a matrix. Consequently, I have a more intricate system that classifies data effectively.
00:20:30.190
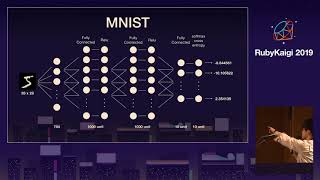
The real strength of this system lies not in the multitude of code; it’s rather that it's slightly more complex than the previous iteration. For example, I’m utilizing an established dataset called MNIST, which comprises a collection of handwritten digits from 0 to 9, containing 70,000 samples. Some of these examples depict truly challenging handwriting—far more difficult than my own.
00:21:27.080
Each digit is represented as a 28 by 28 matrix of greyscale pixels. Every pixel serves as an input variable, just like earlier examples with reservations and temperature. Thus, we encounter a problem with 784 input variables, where the system holds no awareness of these being digits; it just sees a mass of numbers.
00:22:22.790
The code checks how many predictions are valid and employs a sigmoid function to squeeze those numbers into 0 or 1. The classification process involves multiplying input variables by their respective weights and subsequently passing them to the sigmoid function. The classify method observes outputs and selects the most accurate results. This simple program, which I initiated before my presentation, is capable of accurately guessing digits over 90% of the time. This exemplifies a computer vision program effectively operating with a few lines of pure Ruby, as I’m not utilizing any machine learning libraries or similar modules.
00:23:48.010
While this methodology is surprisingly effective, it does have limitations. Even if it runs for much longer than 20 minutes, it will not significantly improve. A critical underlying issue is tied to a concept related to bias. Suppose I try to predict whether a Hollywood movie will be successful based on two input variables: the marketing budget and pre-release ratings.
00:24:54.380
If I collect examples based on past movies, let’s say I plot success as blue squares and failures as green triangles. This data is an ideal case, known as linearly separable—they can be split neatly by a straight line. Our system can efficiently categorize this data because it's fundamentally built on the premise of creating lines and planes. However, what happens when real-world data doesn’t conform to this structure? The issues arise if I try to separate blue and green points drawn around a curvilinear shape. The system can make a respectable effort, but inevitably, it will encounter limitations.
00:26:36.830
To circumvent these restrictions, we can take our initial system and connect it to a second similar system, creating a neural network. Neural networks are capable of drawing curves, thanks to their underlying mathematics. When I apply this modified system to the previously discussed data, it produces a curve, which can effectively separate those classes.
00:27:45.720
I attempted to implement this kind of neural network in Ruby, but it requires extensive resources to achieve significant outcomes. The optimization algorithm becomes considerably more intricate as we add layers to the architecture. However, I could reach nearly 99% accuracy in digit recognition while still using only pure Ruby code, without any external libraries.
00:28:24.310
This process still adheres to the principle of finding a function that approximates given examples; it begins with a random configuration and iteratively reduces error by adjusting this approximation based on the provided data. The mechanics behind deep learning, at a foundational level, continue to revolve around adding layers to amplify accuracy but complicating the training process and demands for computational power.
00:29:41.000
Deep learning has gained traction because we now possess adequate processing power, and we've devised methodologies to effectively train these complex systems. As evidence of this rising trend, organizations such as Google and Facebook are developing increasingly sophisticated neural networks, owing largely to the tremendous data they accumulate.
00:30:59.390
To illustrate a specialized architecture, let’s discuss generative adversarial networks (GANs). This innovative approach works by pairing two systems: a discriminator that identifies whether an image is genuine or generated, and a generator that creates images from random noise. The generator, initially producing just random patterns, learns to generate coherent images by attempting to deceive the discriminator.
00:31:48.340
For that, I picked a popular dataset called CIFAR-10, involving low-resolution images, some of which depict horses. Although the dataset is relatively small with about 6,000 image samples, I iterated through this GAN experiment. At the beginning, the generator creates indistinguishable noise, but within a few iterations, it learns to produce recognizable content.
00:32:52.470
After ongoing iterations within a day or so, the result comprises images that closely resemble horses, albeit with notable peculiarities. Despite having never seen a horse, this GAN effectively learns to produce images capturing the essence of what a horse looks like. If such techniques are applied with extensive racks of GPUs and optimized code, we observe astonishing products—a fascinating manifestation of this technology.
00:34:34.830
For instance, a site named 'This Person Does Not Exist' generates lifelike images of individuals who do not actually exist. These images, crafted using GANs trained on datasets of actual people, demonstrate remarkable results while raising ethical considerations. It's captivating to see how effectively the GAN can produce plausible images while serving as a stunning showcase of this innovative approach.
00:35:55.000
This technology is extensively exploited across numerous fields. Often, it provides a challenging task—trying to discern defects in generated images. Even when these systems perform well, sometimes they struggle with symmetry or specific idiosyncrasies. However, the core understanding remains that the workings behind it aren't magic; it appears intricate, but essentially it is grounded in mathematical principles and systematic training.
00:36:36.400
As I conclude, I'd like to promote my book that has just been released in beta. This book delves deeper into these concepts, providing explanations from line to line. Although the code itself is in Python, which differs from my preferred programming language, it aligns with industry standards for machine learning. Thank you for your time, and now it’s time for questions.
00:38:00.650
Thank you for getting there. What is a recurrent issue? You refer to biases in training data or the algorithms? Oh yes, I'm glad you brought this up.
00:38:39.619
As awareness grows around the ethics of AI systems, many organizations are understandably hesitant to utilize such systems in sensitive contexts. For instance, I personally would not trust a machine to autonomously determine my eligibility for a loan. A notable case in the news involved Amazon's hiring process where the AI only recruited middle-aged white males, indicative of historical biases embedded in training data.
00:39:34.729
In conclusion, the hope lies in promoting better awareness and understanding of these biases in AI systems. The conversation often lacks necessary scrutiny; at a recent event, I noted individuals advocating for technologies that actively discriminate based on historical data.
00:40:00.700
Is there an intrinsic structure in the generator of a generative adversarial network? Yes, that was a convolutional network. It comprehends the scaling around images, thus generating decent experiments with varied architectures targeting particular types of problems.
00:41:00.740
To summarize, such specialized architectures can certainly translate into generating various types of data. However, using the same method across entirely different domains, like generating text, would likely yield poor results. Overall, this specificity enhances performance in generating relevant outputs matching their intended domain.
00:41:43.600
Thank you for your questions, and if anyone else would like to ask, I’ll be here to respond.