00:00:03.179
Hello everyone, I am Vladimir Makarov. I'm glad to participate in RubyKaigi again.
00:00:06.180
I'd like to thank my company, Red Hat, for permission to spend half of my work time on Ruby projects.
00:00:11.940
In this presentation, I'll talk about my attempts to implement a faster CRuby interpreter. The approach I primarily use for this project is dynamically specialized internal representation.
00:00:20.580
I believe this presentation will be interesting for any developers working on improving the performance of interpreters for dynamic programming languages.
00:00:44.760
Here's my presentation plan. First of all, I'll discuss my motivation to start this project and my initial expectations for the project's outcome.
00:00:50.820
I will cover the general approach to performance improvement through specialization, along with the specialization techniques used in my project to implement the fastest CRuby interpreter. I'll discuss the current state of the project and present some performance results in comparison with the base interpreter, MJIT, and MIR-based JIT, which is still in the early stages of development. Finally, I'll talk about my future plans for this project.
00:01:41.700
As you probably know, about four years ago, I started a project called MIR to address shortcomings in the current Ruby MJIT. I initiated this project as a lightweight universal JIT compiler to facilitate implementations not only for Ruby but for other programming languages as well.
00:01:59.340
MIR is already being employed for JITs of several programming languages. I found that it can be easily and successfully used for JITs of statically typed programming languages. However, I realized that MIR in its current state cannot be easily utilized for implementing efficient JITs of dynamic programming languages. Therefore, I've been working on new features for MIR, which you can see on the slide. For more details, you can read about these features in my blog post.
00:02:50.400
The implementation of these features requires multi-year efforts. A recent success with the MIR JIT made me rethink my strategy. In order to implement a decent MIR-based CRuby interpreter faster, I decided to develop some of these features in a CRuby-specific way.
00:03:03.720
I utilize dynamically specialized virtual machine instructions and generate machine code from them using the MIR compiler. Currently, implementing dynamically specialized internal representation and its interpretation is very useful, even on its own. It allows for the implementation of a faster CRuby interpreter without the complexity of objects and portability issues.
00:03:35.400
What kind of performance improvement could I expect for the CRuby interpreter with the specialized internal representation? The MJIT generates the best machine code for single stack virtual machine instructions. This is because the generated code is manually written in assembly. Even GCC or LLVM generates worse machine code for executing those virtual machine instructions in the interpreter.
00:04:02.099
MJIT also removes the instruction dispatch code in the interpreter, but it does not optimize combined code for several virtual machine instructions. Using register transfer instructions can be seen as an optimization for codes comprised of multiple stack virtual machine instructions. I anticipated that if I implemented RTL and MJIT basic block versions in the interpreter for certain benchmarks, I could achieve performance comparable to MJIT. We will see what I actually achieved in reality later.
00:04:50.400
I've already mentioned code specialization several times, but what is actually called specialization? According to Merriam-Webster Dictionary, one definition of specialization suitable for us is 'designed, trained, or fit for one particular purpose.' If we generate code suitable for a particular purpose, and that purpose is the most frequent use case, we can create code that performs faster in most cases.
00:05:19.620
Specialization is one common approach for faster code generation. Even static compilers produce specialized code, like matrix multiplication optimized for particular sizes of processor cache. Specialized instructions already exist in CRuby; for example, the Ruby virtual machine has instructions to call methods with specific names, such as the instruction 'opt_plus' to call the method 'plus' that works on the most frequently used data types, like numbers.
00:06:00.000
Code specialization can be done either statically or dynamically during program execution. When done dynamically, you have more data to determine specific cases for specialization. This is why JITs usually perform more specialization compared to static compilers. You can execute specializations speculatively when you cannot guarantee that the specific conditions for specialization will always hold true.
00:06:30.000
For speculative specialization, you need guards to check that the initial conditions for specialization are valid. If they are not, you switch to code that does not require those conditions for correct operation. This switching of code execution is often referred to as optimization in the context of JITs. The more dynamic a programming language is, the more specialization and speculative specialization is needed to achieve performance close to that of statically typed programming languages.
00:07:10.000
All specialization implemented for CRuby is done dynamically, in a lazy manner, and only on the basic block level. As a result, a multitude of versions of the original basic block exists when the basic block is executed frequently. There are specialized hybrid stack RTL instructions that could be created for all basic blocks at compile time; however, I do this lazily as part of a common technique for generating different specialized versions of basic blocks.
00:07:40.000
Laziness helps to save memory and time spent on RTL generation. Later, I will explain why I use hybrid stack RTL instructions instead of purely RTL. I also generate type specialized instructions, which can be done through lazy basic block versioning as developed by Maxim Chevrolet and used in MJIT. This specialization contains no associated costs and does not require special guards to check the input instruction value types.
00:08:20.000
Additionally, app specialization is performed based on profiling. In this case, guards are indeed required to check the types of input instruction values. This type specialization further enhances the cost-free type specialization. There are various other specializations based on profile information; perhaps the most interesting one is iterator specialization, which I will discuss later.
00:08:55.000
Ruby uses stack instructions in its virtual machine. These virtual machine instructions address values quite implicitly. For example, we can use the addition instruction explicitly. Sometimes, a set of such instructions is referred to as RTL (register transfer language). Here’s an example of how the addition of two values is implemented using both stack and RTL instructions.
00:09:15.000
As a rule, RTL code contains fewer instructions and therefore spends less time in the instruction dispatch code of the interpreter. However, it may require more time for operand decoding. More importantly, RTL code results in less memory traffic, as local variables and stack values are addressed directly by RTL instructions, eliminating the need for pushes and pops of local variables.
00:09:32.000
In many cases, CRuby operates on recent values in a stack manner, such as when pushing values for method calls. Hence, pure RTL has its own disadvantages in these scenarios, potentially leading to larger code sizes and slower operand decoding.
00:10:05.000
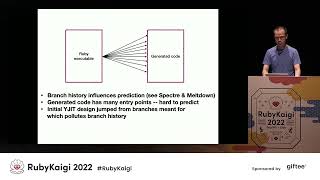
Another specific issue with pure RTL is its less effective handling of local variables and stack values. The left picture illustrates a typical Ruby method frame where addressing values is rather straightforward; you can simply use offsets relative to the environment pointer with negative offsets for local variables and positive ones for stack values.
00:10:40.000
Unfortunately, a method frame can look quite different, as shown in the second picture. In this case, the environment pointer is used for negative offsets while the stack pointer is used for positive offsets, creating many branches for addressing instruction values.
00:11:20.000
I used this approach about four years ago, and it yielded approximately a 10% performance improvement on the benchmarks I employed. Based on my past experiences, I adapted my previous approach to using RTL in this project by introducing hybrid stack RTL instructions, where some operands can be addressed implicitly and others explicitly.
00:11:40.000
Certain instructions I added use suffixes; 'S' indicates a value on the stack, 'V' indicates a value in a local variable, and 'I' indicates an immediate operand. Some combinations of suffixes are not utilized.
00:12:30.000
Many of the new instructions can potentially lead to worse locality in the interpreter, but in practice, the benefits of reduced dispatching and stack memory traffic outweigh this potential drawback. In general, code locality is less critical than data locality in modern processors.
00:13:00.000
The generation of RTL instructions is performed only on the level of virtual machine instruction basic blocks and done lazily during the first execution of any basic block. The mere introduction of hybrid stack RTL instructions improves performance by almost 20% on my benchmarks.
00:13:40.000
Many CRuby virtual machine instructions are designed to work on primitive types like Fixnums. They perform extensive checks before executing an operation. For instance, the 'opt_plus' instruction checks that the input data are Fixnums and that the Ruby method 'plus' has not been redefined for integers.
00:13:57.000
If these checks fail, a general method 'plus' is invoked instead. By introducing type-specialized instructions without the checks and calls, we achieve faster and leaner instructions as well as improved interpreter code locality.
00:14:30.000
To ensure that type-specialized instructions handle the expected data types correctly, lazy basic block versioning is utilized. As previously stated, this lazy basic block versioning was invented by Maxim and serves as a primary optimization mechanism for MJIT.
00:15:05.000
If an exceptional event occurs, which prevents the execution of the rest of the basic block, we can optimize the code by switching to a non-type specialized RTL version of that basic block. An example of an exceptional event could be a Fixnum overflow, which results in a multi-precision integer rather than the expected Fixnum.
00:15:35.000
If a standard Ruby operation, like integer addition, is redefined, a similar optimization occurs and all basic block versions containing specialized instructions for this operation are removed. The presence of specialized instructions does not significantly enhance the performance of the interpreter, as most execution time is devoted to boxing and unboxing for number lists.
00:16:25.000
Type specialization for floating-point operations mainly targets the future MIR-based JIT that will effectively eliminate unnecessary boxing and unboxing. When we cannot determine input data types through basic block versioning, we introduce type profiling constructs after a certain threshold of basic block execution.
00:17:10.000
Once the number of executions exceeds this threshold, we generate a version without profiling constructs but include guards for the expected data types and newly specialized instructions based on profiling information. These original call instructions can be specialized to support conventional functional calls or for accessing instance variables.
00:17:50.000
Most Ruby standard methods are implemented in C, except Ruby blocks, which are denoted by 'iseq' and behave as iterators. During each iteration, 'iseq' invokes the interpreter, a procedure that is quite costly. We can mitigate this by utilizing specialized iterative instructions.
00:18:35.000
Currently, iterators are exclusively implemented for methods like 'times', 'range', and 'each' for arrays. Creating specialized iterative instructions is straightforward; typically, it only requires three small C functions. Such specialized iterative instructions can significantly enhance the performance of the iterators.
00:19:15.000
This diagram summarizes the transition from one internal representation to another. Previously, CRuby compiled source code into a sequence of stack-based virtual machine instructions known as 'iseq'. For each 'iseq', we also create a stop instruction executed once, which serves as the starting execution point for that 'iseq'.
00:19:55.000
During the execution of a stop instruction, we generate hybrid stack RTL instructions for the first basic block of the 'iseq'. At this moment, we also produce type-specialized instructions based on known type information and profiling instructions.
00:20:45.000
Now, these type-specialized instructions will serve as the starting execution point for the 'iseq'. Following this execution, the process continues from these newly type-specialized instructions of the respective basic block, where further continuations also point to successor basic block instructions.
00:21:20.000
After a specified number of executions of a basic block version, we generate type-specialized instructions alongside those based on the collected profiling information. This represents the new starting point of that basic block. This also signifies the starting point for the MIR-based JIT compiler that I am currently working on.
00:22:00.000
The MIR-based JIT generates code for one basic block version only. In the future, it will also produce code for the entire method. All of this unfolds as a regular part of execution.
00:22:35.000
If during execution our speculative assumptions do not uphold, we revert to executing non-type specialized hybrid stack RTL instructions.
00:23:10.000
The specialized internal representation and MIR-based implementations can be found in my GitHub repository. Currently, the state is functional primarily for running benchmarks, which I will discuss shortly.
00:23:45.000
As it stands, the code for generating and executing the specialized internal representation consists of approximately three and a half thousand lines of C code. The generator for C code for MIR adds another two and a half thousand lines.
00:24:15.000
The MIR-based JIT requires a MIR library, which compiles to about 900 kilobytes of machine code. This library has the potential to be reduced to a smaller size.
00:25:00.000
To utilize the interpreter with the specialized internal representation or MIR-based JIT, options 'dash dash MIR' or 'dash dash MIR JIT' must be employed. You can use the debug options, but please note that output for even small Ruby programs will be quite large.
00:25:35.000
I've benchmarked the new interpreter against the best interpreter, MJIT, and MIR-based JIT with the following parameters. The results were gathered on a set of micro-benchmarks.
00:26:15.000
On these micro-benchmarks, the performance improvement for the new interpreter stood at 93%.
00:26:40.000
The RTL with type specialization greatly accelerates benchmark runs compared to previous versions, demonstrating significant performance gains.
00:27:15.000
Iterator specialization yields similar results for the nested times benchmark. However, for calls, the specialization does not perform well.
00:28:00.000
The MJIT generates code for calls that is two times faster than in the interpreter with the specialized internal representation. MJIT’s already specialized generated code takes into account aspects such as the number of arguments and local variables of the invoked method.
00:28:30.000
While we could add call instructions specialized for certain parameters, this would considerably increase the number of specialized instructions, so I opted not to pursue this approach, especially since it will be resolved in the MIR-based JIT.
00:29:00.000
Many simply measure overall time for benchmarks, but CPU usage is crucial as well. It reflects how much energy is consumed during benchmark execution. There is no notable difference in CPU and wall time for micro-benchmarks, except MJIT.
00:29:35.000
MJIT generates machine code using GCC or LLVM in parallel with Ruby program execution. Both GCC and LLVM apply many optimizations, consuming a substantial amount of time in the process.
00:30:05.000
The maximum resident memory used by the fast interpreter relative to the basic interpreter shows that MJIT consumes significantly more memory in several instances.
00:30:35.000
In many cases, memory is not utilized fully. I believe that this behavior of MJIT can be optimized in the future.
00:31:15.000
I have the results for Ruby's odd characters when using 3000 frames. As you can see, the specialized internal representation provides a modest 39% improvement.
00:31:50.000
In the optimized version of the 'opt_carrot' benchmark, the specialized internal representation demonstrates impressive performance during execution, ranking just behind the MIR-based JIT.
00:32:30.000
The decrease in performance regarding calls specialization in the interpreter is a significant factor contributing to these results.
00:32:55.000
I did not investigate the reasons for MJIT's low performance in this benchmark, but I suspect that the MJIT memory pool might be insufficient for optimized 'odd character' handling.
00:33:40.000
The faster CRuby interpreter is merely an early prototype, and much work remains to be done. As it stands, it currently contains many bugs, and I have several ideas for enhancing the interpreter's performance further.
00:34:30.000
The beauty of the specialized internal representation is that it's not a part of the CRuby API and can be easily modified. For instance, when object shapes are introduced, this flexibility allows for experimentation and innovation.
00:35:10.000
I aim to finalize much of the interpreter's work this year. As for the MIR-based JIT, there are potentially even greater challenges to overcome and many bugs to address to produce improved code.
00:35:40.000
Currently, I view the specialized internal representation and MIR-based JIT more as research projects than as production-ready solutions.
00:36:20.000
Due to the significant technical debt I am facing, I likely cannot guarantee the maintenance and adaptation of this code for future versions of CRuby.
00:36:50.000
Anyone is welcome to use and modify my code for any purpose, and I sincerely encourage this. I can offer some assistance, but I cannot commit to ongoing work in this area.
00:37:30.000
For the time being, I intend to focus on the work and maintenance of the MIR project itself.
00:38:00.000
I hope this presentation has been informative and useful. Thank you.