Ruby
Achieving Fast Method Metaprogramming: Lessons from MemoWise


Summarized using AI
Achieving Fast Method Metaprogramming: Lessons from MemoWise
by Jemma Issroff and Jacob EvelynIn the RubyConf 2021 talk titled "Achieving Fast Method Metaprogramming: Lessons from MemoWise," speakers Jemma Issroff and Jacob Evelyn delve into the performance optimization journey of MemoWise, a high-performance memoization gem for Ruby. They begin by addressing the common perception that dynamically generated methods can be slow, sharing insights from their own experiences and benchmarks performed during development.
Key Points Discussed:
- Introduction and Acknowledgments:
- Speakers acknowledge the indigenous communities whose land the event is held on and pay tribute to a late community member, Mike Rogers.
- Speakers acknowledge the indigenous communities whose land the event is held on and pay tribute to a late community member, Mike Rogers.
- The Need for Memoization:
- The speakers explain their initial motivation stemming from performance issues encountered in a data processing pipeline at Panorama Education, a company utilizing Ruby. They highlight how memoization can effectively cache results to reduce computation time.
- The speakers explain their initial motivation stemming from performance issues encountered in a data processing pipeline at Panorama Education, a company utilizing Ruby. They highlight how memoization can effectively cache results to reduce computation time.
- Limitations of Default Memoization:
- They describe the limits of Ruby’s built-in memoization method, such as its inability to cache falsy values and potential namespace pollution from additional method variables. They illustrate a more streamlined approach by redefining methods to automatically cache results without modifying original implementations.
- They describe the limits of Ruby’s built-in memoization method, such as its inability to cache falsy values and potential namespace pollution from additional method variables. They illustrate a more streamlined approach by redefining methods to automatically cache results without modifying original implementations.
- Benchmarking and Performance Optimization:
- Emphasizing a scientific approach, they highlight using benchmarks (specifically using the ‘benchmark-ips’ gem) to analyze performance metrics. Key optimizations include:
- Reducing unnecessary object allocations, particularly in method calls.
- Leveraging
module evalfor method redefinition to avoid performance penalties associated with blocks. - Simplifying cache key structures to minimize computational complexity.
- Emphasizing a scientific approach, they highlight using benchmarks (specifically using the ‘benchmark-ips’ gem) to analyze performance metrics. Key optimizations include:
- Conclusion and Results:
- Ultimately, their optimizations yielded significant performance gains, especially with methods that had fewer arguments. They decided to release their findings through the MemoWise gem, providing an easy solution for others looking to enhance performance in Ruby applications.
- Ultimately, their optimizations yielded significant performance gains, especially with methods that had fewer arguments. They decided to release their findings through the MemoWise gem, providing an easy solution for others looking to enhance performance in Ruby applications.
- Final Thoughts and Call to Action:
- Each speaker encourages audience engagement, providing personal contact information for further discussions and collaboration, and promoting community initiatives like WNB.rb for women and non-binary programmers.
- Each speaker encourages audience engagement, providing personal contact information for further discussions and collaboration, and promoting community initiatives like WNB.rb for women and non-binary programmers.
Main Takeaways:
- Performance issues in memoization can often be addressed with thoughtful optimizations focused on reducing complexity and enhancing method execution speed.
- Benchmark-driven development is crucial for identifying pain points and testing the efficacy of performance improvements.
- Community involvement and sharing knowledge through tools like MemoWise fosters growth and innovation in the Ruby ecosystem.
Jemma and Jacob demonstrate how systematic analysis and community collaboration can lead to substantial advancements in programming efficiency, encouraging others to actively engage in exploring these optimizations in their own work.
00:00:10.240
Achieving fast method metaprogramming: Lessons from MemoWise. I'm Jemma Issroff, and my pronouns are she/her.
00:00:23.039
And I'm Jacob Evelyn. My pronouns are he/him. We wanted to start by acknowledging the Arapaho, Cheyenne, and Ochetti Sakowin people whose land we are on today.
00:00:29.119
I’ve had a lot of great conversations this week at RubyConf about improving the Ruby community, making it larger and more diverse. I believe a really important piece of that is elevating the voices of Indigenous Rubyists and examining our own community for ways that we might be promoting systemic racism and oppression.
00:00:48.880
Thank you.
00:01:05.600
We also wanted to take a moment to remember Mike Rogers, a beloved member of the Ruby community whom we tragically lost this past weekend. His kindness and inclusivity were an inspiration for many, myself included, and I will continue to remember him as a role model.
00:01:27.119
We will continue this presentation by first discussing why we started down this path, our interest in memoization, and the eventual building of a gem. We will then talk about performance, specifically the need to optimize the performance of this gem using benchmarks.
00:01:40.400
Next, we will walk through specific optimizations we made to our code to enhance its performance. Lastly, we will spend some time trying to convince you each to come work with us.
00:02:02.799
I used to work with Jake at Panorama Education, which is an educational technology company with a large data processing pipeline. It is event-sourced with mostly pure methods and runs each night with a hard stop time; the data must be ready by morning when anyone affiliated with a school might need it.
00:02:19.280
There are many methods in this processing pipeline; some are very slow, and others are called millions of times. We have many files, some containing millions of rows, and we can imagine scenarios where we have a complicated date stamp that must be parsed repeatedly to ingest that data.
00:02:30.000
As I mentioned, we have a real-time crunch. The question becomes: what if the process data method gets called millions of times for the same start date and date pair?
00:02:54.239
One answer is to use built-in Ruby memoization, which we might all be familiar with. It looks a little something like this: we have our hash, and based on the arguments that our method takes, we store the method's return value so that when it's called again, we can retrieve the value without recomputing it.
00:03:12.560
This approach works for some cases, but there are a few problems for our use case. Specifically, it doesn't remember falsy values. As we know, if the value is nil, then the next time it's computed, we will still call our un-memoized method, and it will take as long as it did before.
00:03:36.959
Additionally, it can become cumbersome. In this snippet, we only have two parameters, but there may be cases with many more, complicating the hash and the key. Lastly, this method can pollute our namespace since the method name and an instance variable would have the same name, causing confusion.
00:04:03.680
Ideally, we want something that doesn't require changing our initial method at all; we would like to use an annotation to specify optimization, allowing the method to execute the first time and subsequently just retrieve the already computed value.
00:04:30.960
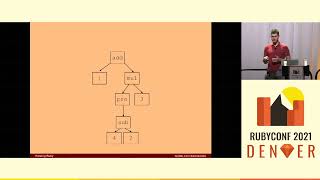
So how does this memoization snippet work? Typically, it looks something like this: we take in the method name we want to memoize, come up with a new method name for the original un-memoized method, and alias that name to the other name.
00:04:39.679
This allows us to call the original method while dynamically redefining it. The rest of this follows a similar pattern, where we define an instance variable cache, create a unique key for the method and its arguments, and look it up in our hash.
00:05:02.960
If the key is present, we return the value; if not, we call the original method, place it into our cache, and return it. We found that implementing this made our data pipeline much faster, which was great; however, we had hundreds of these methods being called millions of times, and it still wasn't as fast as we wanted it.
00:05:41.199
Since we were executing this code repeatedly, we thought this might be a good place to look for optimizations. We were critically concerned with optimizing our performance as much as possible.
00:05:56.640
Like any good scientists, we followed the scientific method: observation, hypothesis, experiment, and analysis. Benchmarks are one of the best ways to measure performance and to create an experiment that we can use repeatedly.
00:06:45.760
We used a popular benchmark gem called Benchmark-IPS to measure this. The first thing we wanted to do was disable the garbage collector; we didn't want it interfering with our measurements and giving us inaccurate results. We also called our method ahead of time to memoize the result without affecting our benchmarks, focusing instead on the speed of subsequent calls.
00:07:39.680
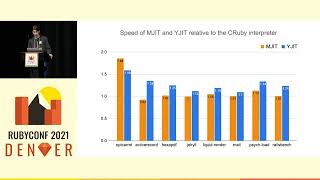
We had a hypothesis that methods with different types of arguments would take drastically different amounts of time to run. This was indeed the case. For instance, the performance of memoized method calls per second with no arguments was quite different compared to situations with both positional and keyword arguments.
00:08:27.760
For the rest of this presentation, we will normalize each row to one because what we are mostly concerned with is optimizing compared to previous iterations of the same method.
00:09:05.280
Going back to our baseline implementation and putting on our science hats, we came up with a hypothesis for ways we might improve speed. The first observation was that the line initializing our cache was only needed once, the first time any of these memoized methods are called. We proposed removing it from the method to prevent it from being a wasted operation.
00:09:53.440
We made this change and ran our benchmarks again. We did see performance improvements, but not as significant as we had hoped, so we looked at the code again. Next, we noticed that our define method, where we dynamically redefine this method, uses a block.
00:10:27.440
Blocks incur a small performance penalty, so we researched ways to dynamically define methods in Ruby without using a block. We discovered module_eval, which can evaluate a string as if it were raw Ruby code, allowing us to put a 'def' call in it with appropriate string substitutions.
00:11:04.640
We made these changes and ran our benchmarks again, but we still did not achieve the performance gains we were hoping for. We took another look at our code to see where else we might optimize.
00:11:44.159
This time, we focused on the method itself, specifically at the key and the fetch call. The key consisted of the method name, positional arguments, which were themselves in an array, and keyword arguments in a hash. The complexity of the key was causing some performance hits, especially since calls to hash are not inherently free.
00:12:39.120
We looked at how our keys formed in the case of many positional and keyword arguments. The complexity was unnecessary and performance heavy, particularly as we were calling 'hash' on that complexity with each memoized value lookup. In contrast, when we only had positional arguments, we could simplify our key structure by avoiding unnecessary hash allocations. By flattening the array, we could simplify our lookups and improve efficiency.
00:13:41.760
In cases with no arguments, we could remove both the array and the hash altogether and use just the method name. This led to significant performance improvements across the board, especially in methods without arguments. Removing excess structure allowed for quicker lookups.
00:14:22.640
This made us wonder if we could apply the same principle to methods with just one argument. Instead of using a standard cache that involved creating a complex key, we developed a nested hash. The benefit of simpler objects meant faster access for our cache lookups, leading to improved performance, particularly in those scenarios.
00:15:13.440
Continuing with our exploration, we rewrote code for methods with a single argument, minimizing the overhead of constructing keys entirely. By using the method name directly as the key for returning stored values, we noticed that the performance saw improvement due to the reduced overhead when looking up cached values.
00:16:32.480
After making adjustments to our caching approach, we delved deeper into switching our method name references from symbols to numbers. This allowed us to use arrays instead of hashes for lookup, resulting in even faster access times during execution.
00:17:24.960
However, we faced challenges with methods that accepted no arguments, as they didn't come with nested hashes. To tackle this, we introduced a ‘sentinel array’ to track whether a value was set at a given index, alleviating ambiguity when checking for nil values.
00:18:20.480
We implemented this change, re-ran our benchmarks, and observed further performance improvements. Interestingly, we noticed that methods with fewer arguments saw the most significant speed ups, not due to any magical property of array lookups, but simply because they had less happening overall which amplified the changes.
00:19:46.560
By focusing on optimization across these various cases, we grew curious to see if there were further enhancements possible. We revisited the fetch block from earlier, recognizing that it was also concealing complexity leading to some performance penalties.
00:20:39.360
So, we unraveled this into an if-else statement, aiming to replace the block and possibly save execution time. However, upon benchmarking, we found that this adjustment performed poorly compared to our fetch method due to redundant checks occurring.
00:21:52.720
After some reflection about the nuances of fetch and its underlying operations, it became clear that we had inadvertently increased the complexity of our checks. By reintroducing the fetch and combining it into a method, we ensured a structured approach that maintained performance while being cleaner stylistically.
00:22:59.679
Ultimately, we landed on a solution that offered consistent performance metrics. We took the time to evaluate when falsy values might factor into performance. Our final benchmarks yielded impressive improvements overall, especially for methods with fewer parameters, enabling better efficiency in our data pipeline.
00:24:38.000
As we prepared to share this keen insight, we decided to extract our work into a gem called MemoWise. Our hope is that developers find it easy to integrate into their own codebases, just as we did, to enjoy the benefits of fast memoization.
00:25:55.680
Once again, I'm Jacob Evelyn; this is my personal website and email. Please reach out and get in touch with me. I would love to engage with you about anything related to this talk or my work at Panorama Education, where I have been for nearly a decade.
00:26:24.120
And I'm Jemma Issroff. You can also contact me as I recently released an ebook on Ruby garbage collection. I'm also a co-organizer of WNB.rb, a community for women and non-binary Rubyists. If you identify as such, please connect with me.
00:26:55.520
Lastly, we want to extend our gratitude to Josh, James, and Lou, our tech crew, for their efforts behind the scenes. Thank you for your attention. We have about two minutes left for questions.
00:27:40.320
If you have many parameters coming in, you run the risk of memoizing too many things and possibly running out of memory. Did you take that into consideration? We acknowledge that risk, especially when invoking methods with numerous parameters.






















































































Explore all talks recorded at RubyConf 2021












+91