00:00:11.280
So.
00:00:13.280
Welcome.
00:00:15.360
Uh, as a forward, I'm going to try to save a bit of time at the end for questions.
00:00:17.680
Um, but if we don't have any time, there is a Discord channel for this talk. Feel free to put any questions that you have there; I'll definitely be active and responsive there.
00:00:23.119
I am really honored to be here today and to talk with you all—those of you here in person, those of you on the live stream, and anyone who might be watching in the future about how we might be able to achieve what I call ''job bliss.''
00:00:34.160
My name is Stephen, and you can find me on Twitter at fractalmine, though fair warning, I am more of a voyeur there than an author.
00:00:38.719
I somehow find myself these days working across three different projects. I am, first and foremost, the head of engineering at Test IO, a company that provides crowd-driven quality assurance testing as a service. I'm also a consulting engineer for Record Shop, which is a Web3 company in the music NFT space. Additionally, I'm building Smokestack QA on the side, which is an application to help integrate manual QA into teams' GitHub pull request flow.
00:01:08.479
But enough about my jobs; let's get to the topic at hand, which would be our jobs.
00:01:10.600
I think that in every company, with every application, jobs are essential because they are a key aspect of what your app does, expressed as a distinct unit. And they're powerful, right? You can run them, you can call them from anywhere; they can run asynchronously or synchronously, and most job back-ends have a retry mechanism built in.
00:01:52.399
But what is a job in this context? It is not an instance of Active Job; that's not what I'm talking about today. A job is a more generic idea; it’s fundamentally a verb in the same way that a model is a noun. More specifically, it is a verb that represents the change of state in your system. Jobs are state mutations that produce side effects.
00:02:12.080
Since jobs are typically run asynchronously, they can't return a value to their caller, so return values are not particularly meaningful. I think we can say that a job is a Ruby class object that represents some state mutation action that takes as input a representation of initial state and produces side effects that represent a next state.
00:02:44.000
This definition of a job encompasses a wide variety of patterns that have emerged in the Ruby ecosystem. Now, for the rest of this talk, I'm going to use the language of jobs and the interface of Active Job, but these principles we will be exploring are applicable to all of these various ways of expressing a state mutation as a Ruby object.
00:03:13.599
So, how do we build jobs? Well, my Purim in the Sidekiq documentation reminds us of this key truth: jobs must be transactional and idempotent. These are the two key characteristics of a well-built job.
00:03:37.040
But what exactly do they mean? A transaction is just a collection of operations, typically with ACID guarantees, and the ACID guarantees are the foundational characteristics for correct and precise state mutations. Atomicity guarantees that either everything succeeds or fails together; consistency guarantees that the data always ends up in a valid state; isolation guarantees that concurrent transactions don't conflict with each other; and durability guarantees that once those state changes are committed, they are always committed.
00:04:02.720
Now, because SQL databases give us ACID transactions essentially for free, we can—and I think should—lean on the power and resilience of SQL databases to help make our jobs ACIDic. As for idempotency, for something to be idempotent, it just needs to be safely repeatable. Most often, idempotency is defined in terms of pure functions, which, while mathematically interesting, is not particularly helpful to us because jobs don't have return values.
00:04:51.679
What we need is a more practical definition focused on side effects. So I think of idempotency as guaranteeing that the side effects will happen once and only once, no matter how many times the job runs. Since most job back-ends have retries built in for free, if we can make our jobs idempotent, we can lean on the power of this retry mechanism to ensure eventual completion and eventual correctness of our systems.
00:05:41.199
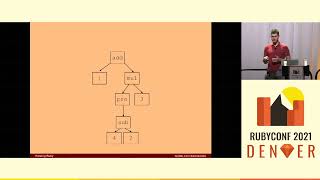
So, the core idea I want to explore with you all is how a class like this—a job run model—can be used to provide flexible ways to create jobs of various levels of complexity with these characteristics of transactionality and idempotency.
00:05:48.000
Nathan Griffith provides an excellent overview of how to write transactional and idempotent jobs in his RailsConf talk from earlier this year. I highly recommend that you check it out, and I will be summarizing his key points here, and he is also here, and that's exciting for me.
00:06:03.440
His examples are save methods of synthetic models, but the principles are the same. Based on our definition of a job, his save methods are jobs in the making. He hones in on five core characteristics of resilient jobs: they use a transaction to guarantee atomic execution; they use locks to prevent concurrent data access; they use idempotency and the retry mechanism to ensure eventual completion; they ensure that enqueuing other jobs is always co-transactional; and they split complex operations into steps.
00:06:39.360
Now, I wholeheartedly agree with this assessment, but what I want to explore today is how we can build more generalized tools and patterns to help us more easily ensure that our jobs conform to these principles. So let's consider Nathan's list and work our way through it, exploring how we can build a toolset for writing truly ACIDic jobs.
00:07:05.040
Let's start briefly with the first two: how can we build transactional jobs generically and flexibly? By using a database record representing this particular job run, we have a mechanism for a database transaction that can be used in any job, and we can mitigate concurrency issues by locking the database row for this particular job run.
00:07:30.720
This is important because even Sidekiq, the titan in the Ruby job back-end world, makes only an at-least-once guarantee of doing that job. But this first step to making resilient and robust jobs that are transactional allows us to ensure that every job can wrap the core operation in a database transaction and use database locks to mitigate concurrency issues.
00:08:01.760
This provides the foundation for our ACIDic jobs as we move forward. The next consideration, though, is how we take transactional jobs and make them idempotent. For a job to be idempotent, it requires being able to uniquely identify the unit of work being done.
00:08:21.360
Therefore, the unit of work that might be repeated. If we consider an example of running a balanced transfer job with the same arguments, the core question for building idempotency is: what is the correct resulting state?
00:08:34.239
How do we tell when the system is executing a job multiple times invalidly versus when the system is executing a job multiple times validly? We have to remember that most job back-ends give us only an at least once guarantee of jobs being run, which means they can be run multiple times.
00:09:01.360
There is such a thing as invalid multiple execution. I think there are basically two different ways to make your jobs have a sense of uniqueness: you can either treat each run of the job as a unique entity or each execution of the job as a unique entity.
00:09:45.440
What do I mean? So, let's imagine our job run model has a uniqueness constraint on the union of job class and job ID, keeping track of when job runs are completed. With just a bit of boilerplate, we have a job that, once enqueued, will only ever execute the operation once, no matter if Sidekiq picks that job off the queue multiple times.
00:10:01.120
This approach treats each separate enqueuing as a valid enqueuing, even with duplicate arguments. So, when using this strategy for job uniqueness, we trust each enqueuing, but we are wary of dequeuing. However, we could imagine not even trusting enqueuing, and this would be the second strategy.
00:10:40.320
Consider instead that our job run model has a uniqueness constraint on the union of job class and job args. In this situation, it wouldn't matter how many times a job is enqueued or dequeued; it will only execute that operation once. This strategy is essentially the idempotent job version of memoization. This memoization strategy would treat any enqueuing of the same job with duplicate arguments as an invalid enqueuing.
00:11:40.239
Now, this strategy is more cautious than the first, but that doesn't make it necessarily better. There are certainly units of work that rightfully should do the same thing multiple times. In our balanced transfer example, it's perfectly reasonable to expect that John might give Jane $10 now and then later, $10 five minutes later, and then $10 five months later.
00:12:09.440
But with a bit of work, we could build a job concern that allows each job to declare how it should be uniquely identified, all while still relying on our job run model. Such an approach would allow us to make our transfer balance job behave in whichever way was correct for our system, whether that is allowing the system to enqueue multiple jobs with the same arguments or, if the job was uniquely identified by its arguments, to constrain the system to execute the operation only once even if enqueued multiple times.
00:12:53.679
Thus, we could use our job run class as the foundation for building transactionality and idempotency into our jobs. Now, thus far, we have only considered jobs whose operations are simple database writes. However, often, our jobs obviously need to do more. One of the most common additional tasks required of jobs is enqueuing other jobs.
00:13:25.680
We could imagine that after transferring ballots, we need to send out email notifications to both parties. Now, as it stands, this code is susceptible to some problems. The first problem is that Sidekiq could simply be too fast. It could enqueue the job, dequeue the job, and execute the job before the original job's transaction has committed.
00:14:01.040
And because our outer job is ACIDic, that second job won't be able to see the state of the database inside of that transaction until the transaction commits. This problem is annoying, but at least it naturally resolves; the retry mechanism will retry that job, and at some point, that transaction will come in. When the job retries, it will successfully complete.
00:14:54.720
The second problem is related in that it's due to enqueuing a job within a transaction, but it's more pernicious. If that transaction in the outer job rolls back, all of the state mutations will be discarded, and the job inserted into the queue will be related to a state that does not and will not exist in your system. So no matter how many times that job is retried, it will fail.
00:15:46.560
Now, one solution to these problems is to simply use a database-backed job queue for all your jobs, ensuring that job enqueuing is always co-transactional, respecting the transactional boundary. This is Nathan's suggestion that he walks through in his talk, but this does mean no Sidekiq, and for reasons we'll get into a bit later, that is a non-starter.
00:16:12.960
The second option is a pattern I first learned of from a blog post by Brander Leach, which is truly excellent—well worth your time to read. In fact, his entire blog is excellent and well worth your time. He lays out the basic idea very clearly: we make job enqueuing co-transactional by staging jobs in the database first, and then, once the transaction commits, enqueue them into our standard job backend.
00:16:50.560
So, what if we could make it as easy to stage a job as it is to enqueue a job? I was surprised at how little code was needed to achieve this. For our example, we can extend ActionMailer message delivery to add a method to stage the job in a database record.
00:17:23.040
Our custom delivery method does a bit of work to handle the details of the different kinds of ActionMailer deliveries, but at its heart, all it essentially does is create a new database record which will respect the transactional boundary of the outer job. This database record can then enqueue the job via a simple Active Record callback.
00:18:01.679
Interestingly, Nathan and Brander both presume that this pattern requires an independent process to stage jobs and then to enqueue them. But with a little bit of Active Record magic and a little bit of safety that is not in these code samples, I think we can have our cake and eat it too.
00:18:42.560
I think we can use transactionally staged jobs to keep the ACIDic guarantees provided by our database transactions. We can keep using Sidekiq, but we don't need to add a new independent staging process that's persistently running alongside our web and job backends.
00:19:21.679
Now Nathan's last recommendation is to split complex operations into steps. We can take a standard example of fulfilling an order in Shopify: you receive the webhook for the order, you process that order, do whatever you need to do in the database, and then you tell Shopify that the order has been fulfilled.
00:19:43.680
Once we've created that Shopify fulfillment record, we can send out email notifications. But what happens if, for some reason—like our email service provider is experiencing downtime—we can't send out the email notification? When the job retries, will we fulfill this order a second time as if the user had purchased the same item twice?
00:20:26.039
Another Brander Leach article will help us navigate out of this tricky situation, showing us how we can break our complex workflow down into transactional steps. We need to move from job-wise to step-wise idempotency.
00:21:02.240
I won't even go into all it would take to make your jobs penny-wise and idempotent. We will stay focused on the simpler task of stepwise idempotent workflows. We can imagine leveraging the power of our job run record by simply adding a recovery point column to the record.
00:21:45.040
This recovery point allows us to track which steps in the workflow have successfully been completed. If we presume that our job record is created with the value initially set to 'start,' all we need to do is, inside of a transaction, do whatever work we need to do, update the recovery point to the next step, and guard the execution of this block with the recovery point representing that unit of work for the next step.
00:22:37.919
The same guarding mechanism applies; we just set the recovery point to 'finish' at the end. Now, this works, but it requires us to come up with consistent names for our recovery points and to wrap each of our steps in this boilerplate. Imagine if instead we could have one workflow job that provides a clear overview of all the steps and how they flow and is stepwise in potency but doesn't repeat the boilerplate of the job block transaction and the recovery key updates.
00:23:21.920
We could imagine a relatively simple DSL in another job concern that provides this capability, where the essence is simply to call the step method to update the job record, the recovery point within that transaction, and do all of that with a guard at the top.
00:24:12.560
Here again, our job run class and our locked database transactions allow us to increase the power and flexibility of building resilient and robust jobs.
00:24:35.120
We have been able, I think, to move the ACID guarantees provided by our database transactions down into each individual step of the workflow, but we've also allowed the workflow to be stepwise idempotent.
00:25:10.560
Now, the problem with stepwise idempotency like this is that all work is done sequentially in the same worker, in the same queue. For a lot of problems, that's sufficient, but for some problems it isn't. What if we have work that can and should be done in parallel, or we have work that is better done on a different queue? For example, what if instead of blocking our workflow queue that’s handling this primary workflow job with external API calls to Shopify, what if we could simply call a job that runs on a separate queue with a lower priority?
00:25:53.440
Can we do this? Well, we can. Sidekiq Pro, and there is an open source alternative as well, offers an amazing feature of batching, which provides a callback for when a specified collection of jobs are all successfully finished. This would provide us with a mechanism for adding a wonderful new layer of power to our jobs.
00:26:26.560
It would allow us to define steps that have parallel executing jobs, but the step is still blocking the flow of the workflow without the job actually blocking IO. We could have a three-step workflow that executes the second job on a separate queue, allowing our primary workflow job in our primary queue to start another job in parallel.
00:27:07.679
But we can also ensure that that first workflow doesn't move to step three until step two is completed. I actually discovered this about a week and a half ago, and it blew my mind. I had to restructure the entire talk because this is awesome.
00:27:50.239
By leveraging the power of Sidekiq batches, we can have parallel, separately queued jobs still used within a multi-step workflow that stays serially dependent, allowing for what we might call parallelization.
00:28:13.689
I am working to gather these techniques and tools for building increasingly complex jobs, all while maintaining transactionality and idempotency in a new gem I'm calling, well, you might have guessed it—ACIDic Jobs.
00:28:37.440
It's still in a pre-1.0 state, but we are using it in production in all of my projects successfully. I have no doubt that the community—you all—can help me immensely to bring this to 1.0 and to provide the Ruby ecosystem with a powerful and flexible toolset for building resilient, robust, and ACIDic jobs.
00:28:58.279
Thank you.
00:29:06.640
So, I was able to save some time for questions.
00:29:10.640
Yeah, so the question is: why break it down into steps instead of creating multiple jobs? I have a slate of about ten slides that I excised answering that question.
00:29:30.720
The core problem is that if you break them down into separate jobs in the naive version at the end of each job, you have to enqueue the next job, which means if I ever need to do that unit of work separately, I can't.
00:30:22.560
To give myself the ability to sort of have these Lego blocks of execution, I might want to run from the command line to do some hot-fixing in production. I need to separate out the operation job, and I also need to have this step job that does the operation, calls it synchronously, and then queues the next job.
00:31:05.920
So, for every step in my workflow, I need to have two jobs, and I don't get to have the overview of what this workflow is like; I have to trace through—in our example, it would be six files—to see what the workflow is, and I don't have a single source of truth that says we're doing this unit of work, which requires doing this thing, then that thing, then that thing, with clear names.
00:31:43.480
It can certainly work, and I think it makes sense to do it in certain situations, but for me personally, I have found that having that map of the workflow provides immense clarity, which has a lot of knock-on positive effects.
00:32:07.439
Did I understand correctly that you want a database table backing some of these jobs to take advantage of SQL ACIDity?
00:32:34.000
Yes.
00:32:44.240
Okay, quick follow-up question on that. I'm just concerned about enterprise scaling—millions of database records. Do you have any suggestions about how to mitigate that?
00:33:12.560
Yeah, there are two things. One, we can look at database records for just job runs. What I'm currently doing is I have a periodic job that just cleans up finished jobs. I know that they have succeeded and can pick a window—over one month old or three months old.
00:34:29.879
For staged jobs, I actually keep two different tables; I’m thinking about whether or not we can merge them. But for staged jobs, there’s a bit of extra magic to ensure that we only delete them once they have definitely been executed, and not just I think I've been queued; I’ve told it to be enqueued, and now I’ll delete the record and can’t come back. I have them immediately deleted once they have been enqueued, so that database record only lives for however long it needs to exist. That table I've never seen at more than a thousand rows.
00:35:58.240
If you have any other questions, as I said you can come to the Discord channel. There is also a Birds of a Feather Discord channel that Nathan created for talking about resiliency in Active Job.
00:36:07.440
Yeah, you can come up and chat with me. I'd be happy to talk more about this. Thank you.