00:00:00.480
Hello everyone, my name is Maxime Chevalier Boisvert, and today I'll be telling you about the lightweight intermediate representation and backend that we've been building for YJIT. First, I'll give you a little bit of background on YJIT and how it works. Then I'll talk about the motivation for building a new backend, followed by the design of the new backend, current performance results, and finally, I'll discuss some next steps to unlock even higher performance.
00:00:26.519
This project started two years ago at Shopify to build a new JIT compiler inside CRuby. From the beginning, we made it a priority to open source YJIT, as we hoped to eventually upstream it into CRuby. Our goal has been to achieve double-digit speedups on real-world Ruby software, particularly focusing on web workloads since Shopify has extensive infrastructure running on CRuby and Rails.
00:00:51.059
The YJIT team takes a data-driven approach to optimize performance. We have a large, diverse set of benchmarks that we run frequently, gathering detailed metrics along the way. Speaking of the YJIT team, I want to extend a big thanks to everyone who has contributed to the YJIT project, including my talented teammates at Shopify, those at GitHub, and various open-source contributors. This project would not have been possible without their help.
00:01:12.000
In the previous year, I gave a talk at RubyKaigi 2021 titled 'YJIT: Building a New JIT Compiler Inside of CRuby.' Following that presentation, Ruby core contributors invited us to submit a proposal to upstream YJIT as part of Ruby 3.1. Thankfully, our proposal was accepted, and YJIT has now been merged and is officially part of Ruby 3.1.
00:01:56.220
Some features of YJIT include lazy code generation, which means we only compile the pieces of code that actually get executed at runtime. YJIT can compile only parts of methods that are executed. It linearizes the machine code it generates, aiming to produce straight-line sequences of machine code to minimize branching. YJIT also performs runtime value promotion, allowing for specialized code based on values present at runtime, and it can specialize machine code based on types observed during execution.
00:02:50.519
Furthermore, it employs speculative optimizations. For example, it can speculate that certain methods will not be invalidated. In Ruby, you can redefine methods on integers, but YJIT can assume that this will not happen, thereby avoiding constant checks on these operations. YJIT implements polymorphic inline caches that apply to both call sites and instance variable settings.
00:03:22.140
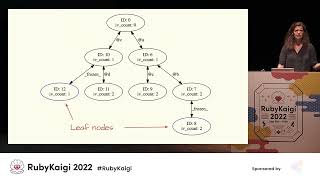
Lazy basic block versioning is a key aspect of YJIT’s design. Traditional just-in-time (JIT) compilers compile entire methods at once, but basic block versioning operates at a lower level of granularity, compiling only the parts of methods that get executed. This lightweight technique interleaves execution and code generation, allowing for rapid machine code generation.
00:04:03.959
This approach developed from research I conducted during my PhD at the University of Montreal, where I built Higs, an optimizing JIT compiler for JavaScript. The focus of my PhD work was to optimize dynamic languages, particularly by eliminating unnecessary dynamic type checks. Lazy block versioning enables type specialization without resorting to traditional whole program analysis, which can be very costly.
00:04:39.959
We rely on the program to reveal types at runtime instead. There are two key components to lazy basic block versioning. The first is versioning basic blocks, allowing us to accumulate and propagate type information and specialize machine code based on context. The second component is laziness—generating code only when it's absolutely necessary.
00:05:02.880
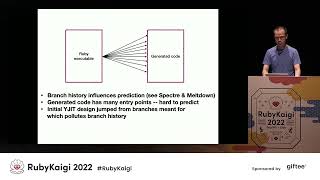
If there’s an if-else branch, for instance, we compile only the branch that gets executed. By employing lazy tail duplication, we can capture type information late in the game, mirroring the concept of lazy evaluation for code. Compared to interpreters, JIT compilers seem like advanced, sophisticated technology.
00:05:39.300
However, simply integrating a JIT compiler into Ruby isn't a panacea. While performance improvements are evident, integration can sometimes be less fluid than desired. This year, our focus has shifted towards building a more robust solution.
00:06:14.600
We've been diligently laying the groundwork for numerous enhancements to YJIT, which requires a fair amount of engineering work. Nevertheless, all this effort is essential for creating a truly capable and powerful JIT compiler.
00:06:46.199
The YJIT team is currently working on significant improvements for Ruby 3.2, including porting YJIT to Rust, final granularity constantation validation, optimizing the rendering of ERB templates, integrating object shapes into CRuby, and designing a garbage collection system for the machine code generated by YJIT. And of course, the primary focus of this talk is the new backend for YJIT.
00:07:11.460
One of our main objectives with the new backend is to introduce ARM64 support, particularly focusing on enabling support for Apple M1 and M2 laptops. Since most developers at Shopify are on Apple hardware, this has become a pressing concern for us. We want developers to seamlessly run Ruby with YJIT enabled, even in local environments, without having to remember to toggle YJIT on or off during deployment. With nearly all Apple hardware transitioning to ARM64, lacking this support would result in losing access to a significant portion of the developer base.
00:08:00.660
Support for ARM64 also means support for AWS Graviton instances, Raspberry Pi devices, and there’s a strong expectation that ARM64 hardware will increasingly penetrate the server space over time. Moreover, future-proofing is a consideration; we may want to introduce support for RISC-V and other architectures in the future.
00:08:28.260
Right now, however, while the initial version of the new backend will offer some speed improvement, it won't be highly optimized. We anticipate that enhancements can occur iteratively. Some design constraints we’ve focused on include simplicity, limiting our scope to 64-bit little-endian platforms for now, and keeping memory usage low.
00:09:04.860
The new backend functions as a sort of platform-agnostic assembler, designed to work more easily than traditional platform-specific assembly and machine code. Its design leverages linear sequences of instructions, creating an intermediate representation that is flat and linear, while minimizing memory overhead since generated IR is not stored in memory after the machine code is compiled.
00:09:37.020
Our compilation process involves several passes over the IR, without resorting to expensive fixed-point analysis. We utilize simple register allocation, specifically linear scan, which performs efficiently. So how does YJIT work? Initially, when code runs in CRuby, it executes within the interpreter, and when a method is called frequently enough, we hit a compilation threshold.
00:10:11.220
When this threshold is reached, YJIT installs a stub and begins generating code for that method. Importantly, it doesn’t compile the entire method at once. If there are branches, it installs stubs that call back into YJIT upon execution, enabling us to compile code lazily.
00:10:40.740
In terms of architecture, the old backend works in conjunction with the CRuby interpreter, where Ruby source code is parsed into an abstract syntax tree (AST). The AST gets compiled into YARV instruction sequences, which are transformed into machine code once a specific calling threshold is reached. That process is more intricate, with several behind-the-scenes operations driving the overall compilation flow.
00:11:32.500
Our goal with the new backend is not to compile YARV instructions directly into x86-64 machine code. Instead, we convert YARV into YJIT intermediate representation, which we will optimize before translating it either into x86-64 or ARM64 machine code. This design permits us to support multiple platforms.
00:12:04.019
In our new design, we separate YJIT into a front end and a backend. The front end translates YARV into our intermediate representation, managing the type specialization of code and constant specializations. This enables us to implement lazy basic block versioning effectively.
00:12:40.680
The backend is responsible for converting our intermediate representation into machine code and integrates some simple, platform-specific optimizations. This modular approach allows us to organize transforms or passes, keeping parts of the backend in a shared structure while also allowing for specific optimizations tailored to the x86 or ARM64 platforms.
00:13:14.760
Both x86 and ARM64 platforms have similarities; they are little-endian architectures that use 64-bit registers and pointers. Many instructions from one architecture, such as move, comparison, and arithmetic operations, have equivalent forms in the other. For our backend's design, we seek common ground between x86-64 and ARM64.
00:13:41.880
To facilitate this integration, we opted for a three-address instruction format. This provides a common framework where instructions have input and output operands. We employ a platform-neutral assembler called 'ASM,' which functions similarly to the IR Builder object in LLVM, thus streamlining our code generation processes.
00:14:18.040
The new backend is a usability improvement over the old one because it alleviates the need to manage scratch registers manually. We've transformed instructions into a cleaner format, making use of named operands for temporaries, streamlining how outputs from one instruction can easily feed as inputs to the next.
00:14:58.680
Instructions we've implemented include numerous basic operations such as addition and logical tests, all functioning similarly across platforms. While designing our intermediate representation instructions brings great improvements, it's not always straightforward due to intrinsic differences between ARM64 and x86 architectures.
00:15:30.600
ARM64 adds complexity in code generation: most of its instructions can only access registers and not memory. In contrast, x86 allows for both types of access. Also, instructions have limited jump offsets on ARM, which complicates branching, notably when many crucial instructions do not directly correspond to their x86 counterparts.
00:16:22.680
ARM instructional sets have sizeable limitations and require manual management of the instruction cache upon code generation, which presents an additional slowdown. As we refine YJIT, we'll pay close attention to building a robust architecture that abstracts away these complexities while still delivering reliable code generation.
00:17:10.680
A challenge we face is ensuring that the instruction format between ARM and x86 aligns well. The splitting pass we’ve developed will streamline this by breaking down complex instructions into simpler ones, making subsequent code generation easier. We account for ARM's restrictions, where immediates or constants in instructions are limited and can require creative handling.
00:17:53.700
Let's illustrate with a simple example. Assume we have a function 'foo' that sums two values. When we analyze its bytecode, we can see specific get local instructions obtaining values from the stack before performing addition. The old implementation required guards to ensure values were fixed numbers while managing temporary registers manually.
00:18:49.320
With the new backend, this same operation becomes cleaner and more efficient. We leverage named operands and do away with much of the manual management, allowing for much easier translations and continuity from one instruction to another. However, we notice that while ARM instructions are effective, they often require more bits and lines of code, leading to larger compiled outputs.
00:19:23.340
Nevertheless, the performance achieved from YJIT's new implementations has been quite promising. The generated code may not be optimized yet, but we've noticed a strong trajectory of improvement, and many opportunities exist for further optimization.
00:20:00.940
Performance results thus far have yielded interesting insights. Benchmarks demonstrate substantial speedups, especially with the ARM64 backend, often outperforming x86 in specific scenarios. While the performance of the new x86 backend trails slightly behind the old version due to some naturally occurring inefficiencies, we are confident these will improve as fine-tuning continues.
00:21:00.240
X86 benchmarks have included popular test suites using active record, hexapdf, liquid template renderer, and others. Despite the ARM64 code generation's relative inefficiencies, it has shown remarkable speedups in multiple benchmarks, which speaks volumes about its potential.
00:21:58.500
Looking ahead, we're optimistic about boosting the new backend performance. Currently, the backend performance on ARM64 is competitive with x86, and with continued efforts, we expect it to surpass older implementations. The upcoming Ruby versions will allow us to gather more feedback and further refine YJIT.
00:23:10.680
In terms of next steps, we plan on refining the backend further, optimizing generated code quality and improving compilation speed. Implementing garbage collection for machine code is also on our agenda, which will make YJIT more suitable for production use.
00:24:36.960
In conclusion, this year has seen the establishment of a robust foundation for extending YJIT’s capabilities, including numerous improvements and backend development. The new backend is key to increasing YJIT's adoption by providing native support for Apple hardware, Raspberry Pi, AWS Graviton, and more.
00:25:46.840
The new backend is still in an experimental phase, but we remain hopeful it will be ready for Ruby 2.2. The collaborative effort in identifying and reporting bugs will be invaluable as we strive to ensure smooth functionality across platforms.
00:26:45.440
As we look forward, targeting performance enhancements remains critical for Ruby’s continued growth. If you're interested in learning more about YJIT, I recommend reviewing the three published papers and various conference talks available online, including my talk from RubyKaigi 2021.
00:27:54.539
For further inquiries or discussions, feel free to reach out via email or connect with me on Twitter. There’s also a dedicated channel on the Ruby Lang Slack for continued conversations about YJIT. Thank you very much for your attention, and I hope you enjoy the rest of RubyKaigi!