00:00:20.400
Awesome, thank you! I'm super excited to be here. Last year was my first talk ever at our conference, so I'm definitely looking forward to this experience.
00:00:41.520
As for my role, I handle your experience when you push apps up there. If something is broken, then it’s definitely my fault. If you hate it, it’s really my fault too, so if you have any issues, please come talk to me.
00:00:53.600
Here’s my contact info: you can find me on Twitter at zero2, and my GitHub is just 'hold on.' You can also email me at [email protected]—it's with one 'r' and no 'a's. People often misspell my name, and if that happens, I won’t get your email.
00:01:06.159
I come from Austin, Texas—not the bear area—and I haven't been home in three and a half months. My stuff lives there, though, so if you're ever in town, I'd love to take you out for tacos. Just reach out and we can grab some tacos—my treat!
00:01:23.840
One of the awesome things about Austin is the great barbecue we have. There's this amazing local barbecue chain called 'Goode Co.' They now have locations all over Texas, and in Austin, they have these fantastic hand washing machines. You stick your hands in, and after 30 seconds, they come out clean after eating a bunch of greasy barbecue food. The best part is that you get stickers after using them!
00:01:41.360
When I go home this Saturday, I'm excited to collect stickers for my taco tour. It will be a great collection! If you guys know Constantine, you might be familiar with my favorite sticker that he has on his laptop.
00:01:59.680
In the community, I work on Bundler and the ButterGem project, which I’m going to talk about today, and I've received help from Steve. I’ve also done a bunch of work with Rails Girls around the world. If you haven’t participated in Rails Girls or any educational organization that teaches beginners, I highly recommend it. It’s a great experience to see the world from their perspective and realize how much knowledge you forget and how difficult it is to be a beginner.
00:02:22.000
I like to do this every so often to remind myself of the challenges beginners face. I was just in Australia last month, and Jorge Haynes gave the opening keynote. Corey is known for both being a gamer and for holding an interesting title.
00:02:35.200
One of the things he discussed was a self-mentoring process where he would take on the title of someone he aspired to be like Aaron Patterson, whom he greatly admires for his open-source contributions. So, twice a week, he commits to doing open-source work, which inspired me, but for different reasons. Aaron also has this fun thing called 'Friday Hugs' where he takes a picture of himself hiking and tweets it every Friday along with a picture of his beloved cat Corbett, who has a Twitter account @orbepuff. If you're not following it, I highly recommend you do so!
00:03:04.159
After seeing Aaron's inspiring interactions, I started going around the world and gave talks after attending the conference with Hills. I’ve been to Finland, Singapore, Amsterdam, Seattle, and more. Today is Friday, and I’m at a Ruby conference, so it makes sense to give out Friday Hugs! If everyone could stand up and pose for a picture, that would be great!
00:03:36.960
Thank you, everyone! Now, let’s move on to the talk.
00:03:44.000
Today, I’m going to talk a little bit about bundler, the client, and provide some context for those who weren’t here last year. I will explain why we actually created the API, discuss the older RubyGems support construction, and go over the incident of when it went down. I’ll also introduce the Ebola Rate Guide that the Bundler team built and maintains. Depending on how much time we have and people’s willingness to skip lunch, I’ll have a bonus round at the end, so we’ll see if we want to discuss some extra things.
00:05:50.000
So, as I was asked in the last presentation, 'Who is Jessica?' This is Jessica Lynn Suttles, who you can find on Twitter as @janelle_suttles. If you’re not following her, you should definitely do so! She was recently sponsored, and I think today is a good day to congratulate her on joining the Bundler team.
00:06:01.520
In the two years I've been working on Bundler, we haven’t had anyone else join the team, so this is the first person who will be helping us with things. I'm super excited to have another person on the team helping Andre and me, as well as Yehuda. Congratulations!
00:06:37.840
Now, what is Bundler? For those who aren't familiar, at a high level, it’s a gem dependency manager for your Ruby application.
00:06:49.919
Those who were here during the older days of Rails 2 or 3 will surely remember the headaches with dependency management. I remember starting an application for my first Ruby job at the other box in Austin, and it would take a whole day to run an app because we had to figure out which gems to install, even though they were listed in the Gemfile.
00:07:04.000
Some gems weren't even listed, leading to confusion among co-workers about which exact gems to install. I remember using Cucumber back then, and the versions were not backward compatible. If you were off by a patch release, it could break the entire integration test suite.
00:07:34.240
When I saw you and Carl present on Bundler, I thought it was the best thing since sliced bread! The interface most of you are familiar with is simply using the command 'bundle install' or 'bundle,' which defaults to the install commands. You have a Gemfile where you list your sources, using RubyGems or any private repos you have, and then you list the gems by name along with their requirements.
00:08:03.280
The sample Gemfile we’ll be using in this presentation was for a simple Sinatra project. When I did this presentation last year, the latest version at that time was Bundler 1.0.22. We ran the bundle install command over a year ago and would get this 'Fetching source index' message, resulting in a very long waiting time.
00:08:46.120
For that simple Gemfile that just included Sinatra, it took roughly 18 seconds to resolve dependencies. A lot of people joked that they would just go get a sandwich or do something else while they waited for the install command to finish. To understand why it was so slow, we need to look at how Bundler resolves dependencies.
00:09:06.000
Bundler has a class called Index that does a lot of work. Most importantly, it contains all the specification information necessary to perform the resolution, and it maintains an instance variable called specs, which lists all the gems organized by name and their associated versions.
00:09:34.000
To fill up the index, we need to fetch all the specs. Inside the index class, we have a method called remote_specs, which goes through all the sources listed in the Gemfile and calls a function to fetch all remote specs for them.
00:10:03.120
If you were to look at the main index, you’d see that it’s only about 1.2 megabytes in size, so it really shouldn’t take that long to fetch. I tested it a month ago, and even over a slow connection, it only took a moment to download.
00:10:42.400
Inside Bundler, there is a remote specification class that acts like a gem specification, tracking the name, version, and platform. However, one important detail is that there’s no dependency information included in this, which hampers the resolution process.
00:11:02.640
Without dependency information, Bundler cannot resolve dependencies, meaning it has no idea what it needs to install when you fetch a gem like Sinatra. Therefore, it has to fetch the gemspec for each of those dependencies during the resolution process.
00:11:19.200
Going back to the remote specs method, Bundler creates remote specification objects for every gem version and platform tuple that exists on RubyGems. This approach consumes a lot of memory. In the early days of Bundler 1.0, if you had a low-memory instance, like a Linode with only 256 MB of RAM, running a bundle install could exhaust the memory.
00:11:40.560
We ran into performance issues on the Bundler team and realized we needed to optimize this memory consumption, which became one of the first things I worked on after joining post 1.0.
00:12:00.800
Using versions like Bundler 1.2.3, we introduced 'fetching gem metadata' in place of 'fetching source index.' The new process allowed installations like our simple Gemfile to complete in roughly three seconds rather than eighteen! The key to this improvement was the new API endpoint provided by RubyGems.
00:12:36.560
This endpoint takes a comma-separated list of gem names and returns all necessary metadata, including names, versions, platforms, and their dependencies. This means we can use a recursive method to hit the endpoint for each gem in the list, allowing us to construct a much smaller dependency graph.
00:12:59.840
This means we can determine dependencies without including irrelevant gems like Rails that are not part of the first-level dependencies for the given gem. We can build a more optimized structure, allowing Bundler to resolve dependencies quickly and efficiently.
00:13:46.000
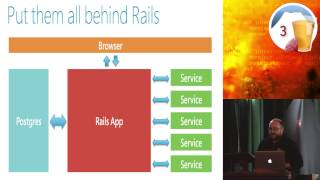
Now, let’s transition over to the server side. The old setup for RubyGems.org was a single quad-core machine that ran everything it needed to. This included the Rails application at rubygems.org, a PostgreSQL database for user account information, gem metadata, and caching counts.
00:15:00.559
On October 17th, RubyGems.org went down. In our post-mortem discussions, we noticed that the bundler API accounted for 73% of the overall traffic to the machine. It also used over 300% of the available CPU most of the time, largely due to marshalling.
00:15:32.640
Because Bundler’s gem specifications don’t contain dependencies and do not require loading additional libraries in memory, the marshalling process for every request became CPU-intensive. So, the Bundler API was disabled to restore RubyGems.org’s availability to developers.
00:16:11.920
Recognizing how much this impacted the community, I was fortunate enough to work at Roku after this happened. They allowed me to prototype a new Bundler API that could take some of the load off the current RubyGems infrastructure.
00:16:59.840
We designed the architecture to be simple; it would pass a comma-separated list of gems to an endpoint and receive a response with the necessary metadata. This way, the traffic load wouldn’t overwhelm the existing RubyGems servers.
00:17:41.840
The endpoint needed to remain up to date with real-time data. We initially considered using webhooks to be notified whenever a new gem was released to update our records, but that's a feature that came later.
00:18:10.960
The API endpoint consists of two parts: the database and the API, which was built on PostgreSQL data taken from RubyGems.org. We obtained a dump of gem versions and metadata, allowing us to bootstrap the entire process. Inside that database, we linked dependencies to specific versions.
00:19:08.800
One crucial component we kept in mind was scoping dependencies to avoid circular references. When deploying an application, you typically don’t need the development dependencies. Scoping this information to runtime was key during queries.
00:19:58.560
When setting up our queries for dependencies, we made sure users would receive an octet stream back from the endpoint. We also aimed to marshal dumps of all dependencies efficiently.
00:20:32.640
Given all that, we managed to put together a system that accurately reflects the gem ecosystem with all its dependencies. This way, when a gem is pushed to the RubyGems registry, our API would respond accordingly with the updated metadata.
00:21:18.000
Initially, we implemented a simple polling mechanism to grab updates from RubyGems.org regularly. This approach kept our local cache populated with new and yank gems whenever necessary.
00:22:09.440
At the time, rates of gem releases were around one new gem every five minutes, making it important to keep our API up-to-date without delay.
00:22:45.280
To optimize performance and resource usage, we started keeping an in-memory hash to quickly access metadata without hitting the database every time. After the first run, the system became really fast, allowing for rapid access to gem information.
00:23:13.440
As a result, it only takes one to two minutes, which is a significant improvement compared to what we had before. We also moved to a webhook system, allowing for better communication between RubyGems and our API.
00:24:02.080
Today, when a gem is pushed, it sends a request to our API, notifying our system that a new gem has been added or updated. This system includes security measures to prevent unauthorized access to the endpoint, ensuring only legitimate gems are processed.
00:24:50.080
Additionally, we implemented timeouts to prevent stalled communication if our API is ever down or experiences load. This way, the push process remains efficient, allowing developers to release gems without concern.
00:25:36.480
The application runs seamlessly on Heroku, utilizing six dynos, each spinning up three workers, with separate databases for reads and writes to optimize performance. We figured this setup made sense from an early perspective, limiting destructive writes to maintain smooth operations.
00:26:32.560
On the operations side, PagerDuty provides us with an account, and we ensure that Andre, Larry, and I are always on call. If an issue arises, we get alerts via text or email so we can address problems as soon as they happen.
00:27:23.920
We also utilize Paper Trail to manage and store logs, enabling us to analyze bugs and other issues. Additionally, we leverage Librato for performance monitoring; Larry played a significant role in implementing instrumentation throughout the application to track relevant metrics.
00:28:20.080
All our metrics are publicly available via a specific URL related to our services, as we strive for transparency around our operations and performance metrics.
00:29:05.160
To help us monitor performance and availability, we set up error alerts, allowing us to quickly react to spikes in errors or service issues that may arise during operations.
00:29:40.000
Setting up our monitoring with Librato requires using the metrics gem, making it easy to track timing and other metrics in a seamless manner. Developers can easily integrate this into their production systems.
00:30:26.000
Our commitment to building this API as a community project ensures that everything is transparent—no secrets. Our code is out there in the open, ready for collaboration.
00:30:45.760
We encourage anyone interested to reach out, as Andre and I are always happy to help you get started or answer questions. There are numerous possibilities for improvements, and we look forward to what our community can offer.
00:31:34.160
We aim to enhance visibility and monitoring and welcome any suggestions. Contributions are welcome in coding solutions, too. We hope to introduce unique tracking for each Bundler install to gather metrics on gem usage within the community.
00:32:29.280
We hope to improve integration with RubyGems data to make it easier to access specific gem information without needing to download extensive datasets every time. Our team is always open to suggestions and insights from the community.
00:33:29.000
I'd like to acknowledge the amazing contributions of Andre for his work on Bundler and his support in managing the Bundler API service alongside me. Larry was crucial for helping us monitor our application effectively, and Daniel Farina from Roku assisted with the initial setup.
00:34:10.000
Before I finish, I’d like to ask if anyone has any questions regarding the project, the API, or anything else.
00:34:43.240
Thank you, everyone.