00:00:31.800
Hey everyone, thank you for coming and thank you for giving me this opportunity to present to you. My name is Andrei Bondarev, and the title of my presentation is 'Catching the AI Train.' A little bit about myself: I fell in love with Ruby about 13 years ago. I’ve built software and led teams in the federal government, in the SaaS consumer product, and B2B enterprise verticals. I currently run a software development firm and play the role of either an architect or a fractional CTO, depending on the type of project we work on.
00:00:38.760
This year, I built the Langchain.rb library, which is a Ruby library for building LLM applications. We will cover it in this presentation.
00:00:41.480
So, can we ignore the AI train? I don’t think it would be controversial to say that Ruby is behind some of the other languages when it comes to AI, machine learning, and data science capabilities, libraries, and knowledge. This might be the largest ongoing revolution in software development, at least in my memory. We largely ignored the massive push to microservices, service-oriented architecture, and partially brushed off the complicated JavaScript front ends and their tooling. We skipped the whole blockchain trend. We, as the Ruby community, survived, but this time might be different.
00:01:17.400
According to the McKinsey and Company report, generative AI's impact on productivity could add the equivalent of $2.0 to $4.5 trillion in value to the global economy. Seventy-five percent of the value delivered will come from four areas: customer service, customer operations, marketing and sales, software engineering, and R&D. Generative AI will automate work activities that take up to 60 to 70 percent of employees' time today, and half of today's work activities could be automated between 2030 and 2060.
00:02:03.960
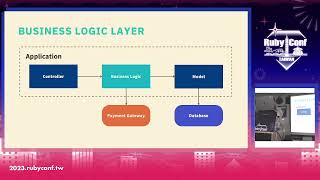
I suggest everyone reads this Private Equity's Cod2 AI report. They have a slide where they make the claim that AI models will be the centerpiece of all modern tech stacks. Essentially, we, as application developers in the application layer, will be building on top of these AI models. So why Ruby or why not Ruby? The Ruby community has so much passion for this language. I think the models are back in fashion in this environment of economic stagnation or contraction, depending on who you ask. The model lifecycles are very attractive. The leadership is evaluating all its costs, and the microservices architecture is very expensive to run. In that context, the model presents a good alternative.
00:02:43.679
The Ruby community is very pragmatic; we hate reinventing the wheel. There’s a whole notion of there being a gem for that. I find that seasoned Ruby developers have a good grasp of sound software development fundamentals, unlike some of the others coming from academic or research backgrounds. Ruby is very similar to Python; it’s another high-level language and is also built on top of C. In instances where Python libraries wrap C functions, I think we should be able to build a lot of those Ruby libraries ourselves. In fact, Andrew Kane and I have probably built a good amount of them already.
00:03:57.679
So, what is generative AI anyway? Generative AI is a type of artificial intelligence technology that can produce various types of content, including text, which is what we're going to focus on in this presentation. It can also create imagery, audio, video, etc. Large language models (LLMs) are deep learning artificial neural networks designed for general-purpose language understanding and generation. They exploded in popularity after the 2017 research paper 'Attention Is All You Need' introduced the Transformers architecture.
00:04:30.920
Unfortunately, we won't cover Transformers today, but LLMs excel at many different tasks. Some of the tasks they are particularly good at include structuring data, converting unstructured data to structured data, summarizing large bodies of text, and classifying data, such as taking blog posts and categorizing them into topics like technology, sports, or business. However, there are persistent problems with LLMs, such as hallucinations, which you've likely heard of. Hallucinations occur when models generate incorrect or nonsensical text. The models often struggle with outdated data; for example, GPT-4 was trained on data only up to April 2023, and frequently relevant knowledge specific to certain use cases may not be captured.
00:05:34.280
There may be a solution, and I would like to introduce Retrieval-Augmented Generation (RAG). This is quickly emerging as a modern technique and one of the best practices for building LLM applications. RAG enhances the accuracy and reliability of generative AI models with facts retrieved from external sources. The typical RAG pipeline follows these four steps: First, take the user question; second, generate the embedding from it; third, use the embedding to query our vector search database and retrieve relevant documents; and fourth, send those relevant documents along with the original question to the LLM to synthesize an answer.
00:06:29.440
To visualize the RAG workflow, we start with the user’s question, generate the embedding, go to a knowledge base to retrieve relevant information, and finalizing by sending that information back to the LLM to get the answer. In the next few slides, we will look at what vector embeddings are, how similarity search works, and what the RAG prompt looks like. Vector embeddings are a machine learning technique to represent data in an n-dimensional space. LLMs encode the meanings behind texts in what is known as 'embedding space,' or 'latent space.' For instance, the phrase 'the Ruby programming language is 30 years old and has stood the test of time' can be processed through an embedding function, yielding an array of floating-point numbers.
00:07:46.399
For example, OpenAI's text embedding models produce an array of 1,536 float numbers. As you generate embeddings for your data, it exists in the vector embedding space, where similar items cluster based on their meaning. A 2D visualization taken from a blog post cataloged and generated embeddings for 15,000 news titles, demonstrating that similar news titles cluster together based on their topics. This brings us to similarity search, which is synonymous with vector search or semantic search and involves searching by meaning rather than just keywords.
00:08:16.960
When conducting a similarity search, we take our query and its embedding and calculate the nearest neighbors using various distance metrics like Manhattan distance, Euclidean distance, or cosine similarity. For example, leveraging the Langchain.rb library, we can generate embeddings for three strings related to Ruby programming. We can then calculate the distances between these embeddings to determine their similarity, where a value closer to 1 means more similarity. By clustering the embeddings, we can see how data is structured based on meaning.
00:09:20.840
Taking all this data, we compile it into a RAG prompt, using Langchain once again to load prompts from a template stored locally. When we format and pass those variables, we get back a string which is our prompt for the LLM. This prompt will typically contain instructions for the LLM, the desired format and style of the response expected, the context which includes relevant documents from the similarity search, and the original question. When trying to consolidate all this information together, we refer back to the McKinsey report, which claims that generative AI technology could drive substantial value across organizations.
00:10:41.720
The primary target for this transformation is revolutionizing internal knowledge management systems. McKinsey states that knowledge workers spend about one day each workweek searching for and gathering information. If we can streamline this process, significant value can be generated. In the code sample we are using Google’s PaLM LLM along with a vector database (Chroma). We set paths to our files which may include proprietary corporate data, market analysis from our analysts, and customer transcripts. By generating embeddings and storing them in a vector search database, we can later ask queries like 'What features are we missing?' or 'What do customers think about our product?'
00:12:04.920
Behind the scenes, the system performs a similarity search, extracting relevant data from the database and using it to synthesize an answer via the LLM. Building such systems can be quite challenging and involves trial and error to create a well-functioning RAG system. The first step everyone takes typically involves human evaluations, similar to the upvote/downvote options seen in models like ChatGPT. This feedback is routed back to the OpenAI team to track quantitative data regarding the accuracy of responses.
00:12:32.160
There are multiple emerging metrics and techniques, with new research papers being published regularly. One such set of metrics is called RAGAS (Retrieval-Augmented Generation Assessment), which defines various ways to quantitatively evaluate the effectiveness of your RAG pipeline. Metrics include faithfulness, which ensures that retrieved context serves as a justification for the regenerated answer, relevance, which ensures that context remains focused and free of irrelevant information, and answer relevance, which checks that the answer directly addresses the initial question.
00:13:16.640
As demonstrated in our library, we instantiate the RAGUS tool and query the LLM with both the question and context. In a presentation from OpenAI, they showcased how they helped one of their customers optimize their RAG pipeline. Their initial iteration yielded a 45% accuracy rate, which gradually improved through various methods including hybrid retrieval, fine-tuned models, chunking experiments, and result ranking. Ultimately, they achieved a remarkable 98% accuracy through careful iterative steps.
00:14:40.160
In summary, building a well-tuned and functional RAG system is indeed a challenging task. Our library supports several different LLMs and vendors, as well as a variety of vector search databases. The field is rapidly evolving, and it's uncertain which technologies will prevail. However, when using Langchain, you'll maintain consistent APIs with reduced vendor lock-in compared to using individual technologies directly, providing you with greater flexibility.
00:15:39.400
Lastly, I would like to cover AI agents, which are autonomous or semi-autonomous programs powered by general-purpose LLMs. They can utilize tools— APIS and other systems—effectively. AI agents thrive with power foundational models, although they can be effective with less powerful setups if scoped appropriately. AI agents can be employed to automate workflows, streamline business processes, and execute multi-step tasks. Previously, when designing flowcharts, programmers would need to account for various permutations and branches; now AI allows for incorporating more ambiguity to handle edge cases and unseen inputs. I would like to share a brief demo showcasing one of our AI agents, built using Google PaLM as the LLM. We're embedding the LLM client and utilizing Google’s search API and a weather API. The agent is tasked with answering a question about where John F. Kennedy liked to spend his summers and the current weather in that location. As you watch the agent operate, it follows steps to first search for information, executes the search tool's outputs, and finally verifies the current weather for the stated location, yielding the final response.
00:25:06.320
In conclusion, we discussed how AI, by many estimates, is becoming central to every tech stack. We highlighted various generative AI use cases, such as structuring unstructured data, performing sentiment analysis, and classifying data. We also addressed some of the prevalent problems, particularly hallucinations, and advocated for RAG as an industry-accepted technique for tackling these issues. We examined what vector embeddings and similarity search entail, along with the structure and importance of the RAG prompt. It's worth noting that evaluation methods remain an area of ongoing research, indicating there will be continuous innovation. Lastly, I want to affirm that the Ruby community has an opportunity to adapt and meet the growing needs of AI, or risk missing out on the AI train. Thank you for your attention. I'm happy to answer any questions you may have.