00:00:11.120
My name is Jake, and I'm joined here by Trevor. We both work at Stripe on the Sorbet team, and we're going to be talking about compiling Ruby to native code with Sorbet and LLVM.
00:00:22.740
A couple of definitions here: Sorbet, if you're unfamiliar, is a type tracker for Ruby. It's something we're really excited about. You might have seen Matt mention it very early on in the keynote, stating that static typing in Ruby is very much happening right now.
00:00:39.360
If you've ever been curious about whether you should use static types in your Ruby code, my advice to you would be absolutely yes. I encourage you to try Sorbet; it's a lot easier to get started with than you might think. In our experience, and in the experience of several other companies that have started using it, it has a lot of compounding benefits over time.
00:00:56.340
The other definition we want to get out of the way is LLVM. LLVM is a kind of framework or toolkit for building compilers. It takes all the hard parts of building a compiler and puts them behind a nice, accessible interface. Our focus is on taking the source language we want to compile—in this case, Ruby—and converting it into native code using LLVM.
00:01:14.460
So when we combine these two components, we create the Sorbet compiler. I must apologize here, as I am a compiler writer, not a graphic designer. I tried to add wings to our Sorbet logo to make it look like a dragon, but it ended up looking like a sword bat. However, we do have stickers of this logo that you can grab from us after the talk.
00:01:36.299
Our agenda will look something like this: we'll first discuss the motivation for the whole project, starting from Stripe's motivation—why performance matters at a basic level. Then we'll transition to discuss why we believe building a compiler for Ruby is necessary to improve performance at Stripe. After that, I'll hand it off to Trevor, who will explain how the compiler works and detail all the cool things it can do.
00:01:59.040
Finally, we'll come back to talk about how we are actually adopting it in production.
00:02:11.940
So, let's dive into the first point: why Stripe cares about performance. For those who are unfamiliar, Stripe is a software company that provides an API allowing businesses to manage any money-related tasks, such as accepting payments, coordinating payouts, managing taxes, giving loans, receiving loans, and handling invoices and subscriptions.
00:02:22.620
One of the features we consider in our API is performance because if two developers are deciding which API to use to build their business, and one API is faster than the other, they are likely to choose the faster one. Therefore, we want to ensure our API serves our customers as quickly as possible.
00:02:40.680
However, this leads to the question of why we believe we need to build a compiler for Ruby to address that performance gap. To give some context, Stripe uses Ruby extensively. It powers our most critical services, including the Stripe API. Hundreds of engineers write Ruby code at Stripe daily, which amounts to millions of lines of code, all organized within a mono repo.
00:03:03.660
A key point to note is that Stripe's Ruby code is heavily typed. We developed Sorbet and have been adopting it for the past three years, meaning at this point, Stripe's codebase is likely the most typed Ruby codebase in the world. We wanted to leverage this type coverage, and we'll see how the compiler uses those type annotations later in the talk.
00:03:34.800
When we zoom in on where the API spends its time, we find two main components: the I/O component and the Ruby code component. The I/O component includes time spent waiting for the database or partner APIs to respond—for example, waiting on a bank's response. However, a substantial part of an API's request time is merely blocked by Ruby code.
00:04:10.200
Contrary to what some might say about simple card apps being mostly I/O-bound, at Stripe, we want to speed up the Ruby code itself to enhance API speed. The Ruby component of the API request is also quite fragmented. Numerous teams are responsible for maintaining various portions of the code across different API endpoints.
00:04:41.940
Instead of having one large block of code that we could optimize, it's distributed across many small parts, which can be challenging to optimize independently. This fragmented code amounts to contributions from dozens of teams.
00:05:10.320
One potential approach to improving the Ruby portion of the API request would be to identify the slowest requests—for instance, perhaps there's a specific code block that’s inefficient. We could determine which team owns this block of code, ask them to optimize it, and if they do it well, we might achieve a significant performance increase. However, even a 2x speed gain would only marginally improve the end-to-end API latency due to the various other factors involved.
00:05:46.440
If we pursued this piecemeal approach, we would have to ask nearly every team across Stripe to stop working on their prioritized features and bugs to focus on speed improvements for their API endpoints. Imagine the frustration this might cause if someone dictated that your entire roadmap should be replaced with a sole focus on performance improvement.
00:06:03.660
What we sought was a more effective solution—a kind of magic wand that could expedite all the Ruby code simultaneously. By accelerating all the components, every team in the company could return their attention to their core focus: crafting an excellent payments API. This gives us a solid justification for launching the project to enhance Ruby's performance.
00:06:44.700
There were various approaches we could have considered. A common question we get is why not use an alternative Ruby implementation that may be faster, like Truffle Ruby or JRuby.
00:07:09.900
We did explore those options but ultimately concluded that the scale and complexity of the Stripe API made it challenging to undertake some kind of incremental migration. Transitioning the entire Stripe API to run on Truffle Ruby or JRuby at once would be quite a difficult undertaking. Again, we were seeking a way to demonstrate incremental progress.
00:07:47.520
Moreover, one significant downside is that transitioning would require us to abandon the Ruby ecosystem that we had established; we'd have to adopt some JVM ecosystem or alternative Ruby implementations, which could level the operating knowledge we've built up around Ruby.
00:08:03.600
At that point, we decided to consider building our own implementation. One of the big questions was whether we would create a JIT compiler, similar to Truffle Ruby and JRuby, or an ahead-of-time compiler instead.
00:08:42.420
An important advantage of an ahead-of-time compiler, which is what the Sorbet compiler is, is that it allows us to leverage static type information. If we know that a specific variable is always of a certain type, we can optimize the code accordingly.
00:09:09.720
Additionally, ahead-of-time compilers tend to be simpler conceptually. The output of such a compiler is strictly a function of the code provided, whereas a JIT compiler generates code based on the input Ruby code and external factors, making it trickier to track down performance issues or bugs.
00:09:46.740
Importantly, we can also utilize both approaches: using the compiler for the parts that it can optimize effectively while running JIT for others. Trevor will talk more about how our chosen implementation allows the compiler to work alongside the existing Ruby VM while facilitating this incremental migration.
00:10:06.300
With that, I'll hand it off to Trevor to discuss how the compiler functions.
00:10:49.860
Thanks, Jake. As Jake mentioned earlier, the Sorbet compiler consists of two main components: the Sorbet type checker and a code generator developed using LLVM. To illustrate how Sorbet works when added to a Ruby program, let's run through a quick example.
00:11:09.720
Suppose we have a function that takes a single argument, X, which will call map on X, passing a block that increments whatever it's given. The way we add Sorbet to this function is by specifying a type signature.
00:11:25.440
This signature indicates that X must always be an array of integers, and F must always return an array of integers. After running Sorbet, we see that there are no errors, which is great.
00:11:40.020
However, if we introduce an error—for example, instead of returning the value from calling map on X, we append a string '2'—Sorbet will catch this, indicating that we're returning a string instead of an array. This type of validation demonstrates the critical type information we leverage in the compilation process.
00:12:07.920
The second component of the Sorbet compiler is the code generator, which utilizes LLVM. LLVM has its own language, essentially a target-independent assembly language, which we use. We take type-checked programs from Sorbet and produce programs in LLVM IR.
00:12:53.160
One might expect that adding a backend to a project like Sorbet would require extensive work, but in reality, it has only taken about 10,000 lines of additional C++ code to get to the point where we're generating shared objects. Additionally, there are about 5,000 lines of C code dedicated to runtime support.
00:13:40.080
LLVM comes structured with numerous optimizations built-in, allowing us to take advantage of these additional facilities for free. Many other industrial-strength compilers, like Clang for compiling C and C++ and Apple's Swift compiler, utilize LLVM.
00:14:25.320
The final part of this pipeline is generating native code, where we emit shared objects that utilize the Ruby VM's C API to efficiently interoperate with Ruby code. For instance, we have a simple Ruby program that defines a function, Foo, and we can also equivalently define this function in C.
00:15:18.300
These C extensions are initialized using a function that essentially serves as the starting point for the Ruby functionality.
00:15:47.460
Let's revisit the example we discussed while introducing Sorbet. This function calls map on an array, and I'll show how we can compile this program iteratively. The first modification required is to add a compiled sigil at the top of the file.
00:16:14.220
The goal is to allow opting in individual files to compilation instead of requiring an all-or-nothing approach to the entire codebase.
00:16:47.700
Next, the compiler will unconditionally check type signatures. We achieve this by moving type signatures into the method body and turning them into exceptions if the type test fails. This allows the Sorbet compiler to better leverage type information to produce better code.
00:17:19.200
For instance, we can raise an exception if X is not an array, and we do the same for the result of x.map to ensure it also returns an array.
00:17:49.080
Subsequently, we seek to avoid VM dispatch, which is quite expensive. By type-checking, we know that X is an array, and we can directly call the implementation in the array.c library, reducing overhead.
00:18:20.340
Once that is done, we can further optimize by inlining the implementation into the function being compiled, eliminating transitions back to the VM, thus getting a more efficient code path.
00:18:56.880
After that, we can inline function calls, iterating instead through X directly while adding one to each element. Each optimization makes the compiled code vastly more efficient than its Ruby counterpart.
00:19:38.160
The goal here is to keep refining the code to avoid unnecessary checks and calls to the VM, ensuring we finally land with compiled code that effectively performs the Ruby operations with almost no overhead.
00:20:06.180
Ultimately, all these optimizations culminate in generating C code that effectively mirrors the original Ruby function, achieving a significant performance improvement.
00:20:26.520
With that, I’ll hand it back to Jake, who will discuss how we are adopting this at Stripe.
00:20:50.760
Thanks, Trevor! I hope you all find this as exciting as I do. It is impressive that we can maintain the same Ruby syntax while achieving significant performance benefits behind the scenes—just run x.map and get an optimized C loop.
00:21:14.820
Now let's focus on what it means for this to actually work in production. Our rollout strategy has three main goals: first, to develop a robust plan for when things go wrong, as they inevitably will. Since Stripe is crucial to many businesses daily, we need to minimize disruptions.
00:21:54.700
Secondly, it's essential that we compare performance based on real traffic. It's insufficient to know our compiler speeds up some test benchmark. We want to ensure it effectively improves real-world Ruby applications.
00:22:33.420
Finally, we aim to ensure that every step in the rollout process is incremental. We want to determine the optimal areas for improvement at any point during our migration.
00:23:12.620
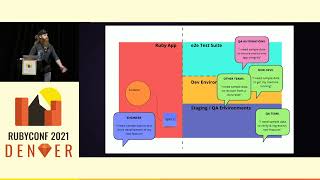
Our strategy for addressing potential issues encompasses multiple layers of defense. The first defense is straightforward: we write test cases for any compiler changes to catch bugs early.
00:23:52.140
We have amassed a strong suite of tests over Stripe's ten-year history, allowing us to run the entire suite against the new compiler. If a test fails, this raises a red flag that signals a potential compiler bug.
00:24:33.600
Additionally, we have a staging environment that mimics production as closely as possible without receiving live API traffic. This gives us one more opportunity to detect any potential compiler issues before they affect customers.
00:25:15.420
Next, we utilize blue-green deploys, which means deploying the new code to a separate set of servers (the green servers) and gradually shifting traffic over to those servers. If any issues arise during this migration, we can quickly revert traffic back to the previous blue servers.
00:25:59.520
Finally, if somehow a bug manages to bypass all these layers, we can still kill the compiled code on a specific host with a simple switch. This allows us to iteratively work on production performance data, using real traffic to gauge the impact of our compiler enhancements.
00:26:48.300
We take care to observe the performance impacts directly by tracking execution time on hosts running compiled code versus those running standard interpreted Ruby, allowing us to visualize improvements or regressions in real time.
00:27:31.620
Next, our strategy for determining what changes to make utilizes StackProf, a stack-based sampling profiler for Ruby. Since the generated code outputs appear like normal Ruby, StackProf seamlessly profiles it just as it would any Ruby application.
00:28:08.280
By sampling requests and identifying which files consume the most time, we can prioritize optimizing those particular files, ensuring we get the most significant benefit from our efforts.
00:28:50.760
This concrete punch list helps us understand which functionalities are most impactful to compile and guides our focus in implementing features for the Ruby language.
00:29:30.300
As we move forward, one of our primary short-term goals remains to increase internal adoption of compiled files. We will be compiling more and more sections of code, and once we've locked in a substantial portion of request handling through compiled code, we'll shift our focus to profiling and optimizing the generated code.
00:30:07.100
This iterative process allows us to continuously refine the generated code and improve its performance by leveraging LLVM as effectively as possible.
00:30:51.720
That wraps up our presentation. If you have any questions, we have roughly seven minutes left. Also, don't forget that we have stickers available. If you're interested in working on large scale problems like these that involve complex solutions, Stripe is hiring! Feel free to approach Trevor or me at the end.
00:31:12.020
Thank you!
00:31:36.620
That's actually really cool! Obviously, there are aspects of this work reliant on type information supplied by Sorbet annotations. I'm curious if there are parts that you've discovered are portable outside of a typed Ruby context.
00:32:13.720
That's a great question! One thing we considered—imagine you have a while loop that runs as normal Ruby code rather than VM bytecode. Evaluating a VM bytecode instruction involves multiple function calls and data structure manipulations, which is inefficient. By optimizing control flow, we see a performance boost regardless of type information.
00:32:49.620
You may have touched on this at the end, but what performance improvements have you observed? Is there a chart you can show us?
00:33:32.960
We nearly prepared a slide showing performance numbers but chose not to, as it could be confusing. Many benchmarks commonly used for Ruby don’t type check and are therefore irrelevant to our compiler's ability.
00:34:14.100
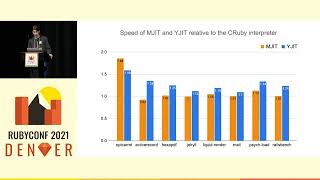
We haven't shared concrete numbers recently because doing so may inadvertently reveal sensitive information. Last I checked, we saw improvements between 2% to 170% in production traffic.
00:34:54.840
How does the compiler check that an array, in this example, only contains integers without iterating over the entire thing?
00:35:19.800
That's an excellent question. The compiler doesn't require iterating under certain conditions. Note that many optimizations won't require knowledge of the element type unless a further operation necessitates it, at which point the compiler would have added another check.
00:35:54.840
Next question: how does the compiler know to replace a method like array.each with a different construct? Is this something you have to manually specify?
00:36:16.080
The compiler has a mechanism for recognizing specific well-known functions, such as those defined by the Ruby VM, to optimize them. For instance, array.each is a common candidate for replacement with a more efficient loop.
00:36:50.920
In terms of user-defined methods, if you mark them as final in Sorbet, the compiler can optimize them similarly by compile them as C function pointers, yielding significant performance gains.
00:37:30.240
Although Stripe isn't primarily a Rails shop, have you tried the compiler on a Rails app or do you know of others using it, like Shopify?
00:38:02.760
Unfortunately, I don't believe anyone other than Stripe has tried the Sorbet compiler yet.
00:38:06.680
Lastly, concerning the type-checks you insert—does the Sorbet compiler take care of removing the final check, or do you leave that to LLVM?
00:38:33.960
We let LLVM handle that. The way we implement these checks allows LLVM to determine when they're redundant, leading to efficient compiled code without unnecessary checks.
00:39:05.320
One point that is vital: we need a minimum type level of typed true for this to work. Sorbet has varying strictness levels, which guide how the type system inspects the method bodies for useful optimizations.
00:39:30.060
With that, we conclude our session. Thank you all for your interest!