00:00:16.400
Welcome, everybody! How's everyone doing? Good morning! I hope you’ve all been enjoying RailsConf. It’s been a great conference, in my opinion. I want to thank Ruby Central for organizing it; it has been a top-notch production. I also want to thank each one of you for coming to this presentation today. And thank you for sitting because this is the only time that I’ll be taller than any of you.
00:00:38.800
Before we dive in, let me introduce myself a bit. My name is Trevor, and I work for Amazon Web Services. I've been there for a little over two years now. I have the good fortune of working on open source for AWS. You may know me if you use the AWS SDK gem; this is the official Amazon Ruby SDK gem. I also contribute to both of these projects, working together with Lauren Siegel, who’s right here in the front row. Lauren is also the maintainer of YARD, so together we maintain the AWS SDKs for Ruby and Node.js.
00:01:12.720
Managing an open source project can be rewarding and challenging; it can be a little chaotic, much like herding cats. But this chaos is something I feel uniquely qualified for—not because I own three cats, but because I'm a father of five. These are my kids: Simon, Boston, Audrey, William, and Dean. Thank you! I will pass that applause on to their mother, who’s at home in Seattle with them right now, taking care of them by herself.
00:01:34.079
So, let’s dive in and talk about APIs. My presentation today will touch on concepts and topics mainly applicable to building web services using Ruby and Rails. That said, much of this material is quite applicable if you're building websites using Rails. We’ll be discussing specifically about API web service APIs. As you might know, AWS is a strong proponent of building everything out as a service. AWS has over 30 services today, and we just launched another one last night—the AWS Support API. This concept of building as a service is kind of ingrained.
00:02:37.760
You may have also noticed the general convergence of the Ruby and Rails community towards breaking apart that monolithic website—the monolithic Rails application—into smaller, dividable chunks. I think this is definitely the right move, and I also hope I’m not the only one who’s noticed this unstated theme of this conference: that we are using and moving towards Rails as an API platform.
00:03:04.880
There are lots of good reasons why we should build APIs. Smaller, more focused web services are easier to deploy, manage, provision, and scale when they are separated. But I'm not here to sell you on this concept. The main takeaway from this presentation is that your API should be an entity, not a side effect. What do I mean by that? Generally, when we start a new greenfield project, the first thing we do is generate a database model and run ‘rake db:migrate.’ We might even drop down to Rails scaffolding to get this up quickly so we can iterate and see things work.
00:03:49.600
This process can be very satisfying; it scratches that itch we have to see things work. But the problem is that when we do this, we’re really approaching our APIs backwards. We need to be approaching our APIs not from the data persistence layer, but from the actual API that our customers are going to be interacting with. It doesn’t really matter how good we can shape our JSON documents if they’re being driven by the database model; we’re setting ourselves up for disappointment later on.
00:04:19.280
We learn these same lessons from other angles in the community. BDD and TDD proponents teach us to think outside-in. So how do we apply this when building an API? If I were to take the MVC pattern, which is a strong pattern in Rails and apply it to a web service application, I would naively state that the models represent my database layer; views are like the JSON translation I’m doing on my data; and the controller is all that stuff that glues them together. That would mostly be correct. However, your model is doing too much.
00:05:06.720
This is a common theme: we tend to try and cram too much into the model beyond just basic business logic. I’ve been working with Rails for a long time; I started back in version 1.16, which was about seven years ago. I remember seeing Rails mature through different stages. One of the earliest problems was putting too much in our controllers, leading to a move towards fat models. The community matured beyond that and realized that our models were taking on too much responsibility.
00:06:30.360
What’s important to note is that your models should not just deal with data persistence and the security of your remote data storage; they also define the shape of your API. Remember that statement: your API should be an entity, not a side effect. It shouldn’t be a side effect of the structure you use for your backend. Does anyone here know who said this quote? Probably not! I’d love to say it originated from some clever fellow, but it was just me writing my speaker notes.
00:07:48.000
The shape of your API should be driven by your domain model, not your persistence model. Conceptually, you should look at splitting your model into two parts: the data as it comes into your application and how it flows out, but not what you do with it once you have it. So, why do you need an API model? I've danced around what it is, but why do you need one?
00:08:45.920
If your API model is not document-driven, if you don’t actually have an entity that describes it, you will duplicate a lot of effort. You’re going to code things up, and then think, okay, now I need to build API documentation, or now I need to filter incoming request parameters, or I need to convert scalar strings that come across in the JSON document to meaningful types, or I need to generate clients. Lastly, as a side effect, I might need to version my API.
00:09:30.439
All of these tasks become harder if you don’t have a physical description of what your API is. So, I’m almost eight minutes into my talk and I haven’t yet mentioned what Seahorse is. Let me give you a quick definition because a lot of you probably came here wondering, what is Seahorse? Seahorse is a model description document that describes the shape of your web service API. I want to point out that it does not dictate the protocol you use; it doesn’t describe whether you’re using XML over the wire, RESTful JSON, or just a simple RPC protocol.
00:10:42.560
It is something that we extracted from our work building clients for AWS. I work with really smart engineers and, despite all of our cleverness, it’s very difficult to handwrite a client for 30 different web services at AWS, each of which may have 30 to 100 different operations and may accept 20 or more parameters, returning very complex shapes of data. It just doesn’t scale. So, we quickly moved to the idea of having a description of these models that we could share among ourselves—PHP, Python, JavaScript, Ruby—and we’re going to consume the same common description.
00:11:31.040
We use it to generate documentation, generate clients, and do a lot of interesting introspection that you couldn’t do without that document. Interesting enough, Seahorse is actually in the wild. If you’ve used the new AWS Python CLI, it’s worth checking out as it internally uses Boto Core, which, in turn, uses Seahorse. The new PHP SDK also consumes these Seahorse model documents to produce its own Guzzle service descriptions. The new Node SDK that we launched, which has full service parity across all of AWS, also uses this, and I put Ruby down there; we don’t actually use it yet.
00:12:18.400
This was extracted from our original Ruby SDK, and we are going to rev that to version 2, which will consume Seahorse documents directly here in the near future. So, let’s actually see what a Seahorse model looks like. If you go to the GitHub repository for AWS Labs, the Seahorse tech demo I’m running today is available there. You can also install it as a gem. This is an early tech demo for the Rails half, but it has the DSL for building Seahorse model descriptions.
00:13:07.440
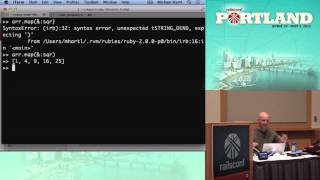
Here’s the actual code; it’s about 600 lines of code. There are lots of interesting things we can add here, but you’ll see there are basic types in there. Let’s open it up. This is a demo Rails app that we call “News Feed,” similar to a Twitter stream. Inside of it, we have app models, and we place them under API. Let’s take a look at the user code.
00:14:05.440
Can everybody see that? Is that a good size? Alright! Basically, we have concepts of types; I sometimes refer to them as shapes. Types can inherit from other types; for instance, we name a type ‘username’ so that we can reuse it in our model definition. It inherits from the type string. We also define operations, which are the input and output relationships linked to type definitions. This is really about defining what all these types look like.
00:14:52.320
The Seahorse DSL looks like this when you rake the Seahorse API. It produces a JSON document where, at the top level, you have operations, and each operation has names, inputs, outputs, and possibly other arbitrary metadata merged on top. There’s nothing magical about it; it’s very human-readable. I’ll come back to this and do more demoing, but I wanted you to see what Seahorse provides before we move on.
00:16:17.760
Seahorse fills a niche that Rails doesn’t really cover well; Rails does not provide much for building a web service API. This is unfortunate, as there are lots of third-party projects that do similar things in different ways than Seahorse does. If you’ve been building Rails for a while, you might be familiar with ‘attribute protected’ and ‘attribute accessible.’ These were introduced back in the Rails 2 era as a stopgap for security issues surrounding bulk attribute assignments.
00:17:27.760
They are inherently insecure. In Rails 3.0, they added the concept of ‘attribute accessible’ as a role, which gave you more flexibility. You could define the shape of what attributes your API might accept and assign these roles, so that in the admin section of your website you might accept more, but never accept certain attributes like ‘created_at.’
00:18:01.520
In Rails 3.1, they made a bold move to enable whitelisting attributes by default. Unfortunately, this caused lots of confusion in the community; there are over 7,000 Stack Overflow questions related to ‘attribute accessible’ today, and it’s a common problem. The issue is that whitelisted attributes don’t do enough and are not implemented well. They are tied to your data persistence layer, which isn’t really where they belong. Early versions also did not support multiple configurations, although they do now, and it’s complicated to use with other Rails conventions like nested attributes.
00:19:36.080
So Rails 4 to the rescue! I was surprised that relatively few talks have presented new technology that’s coming with Rails 4. I want to quickly introduce one that all of you should know about, which is Strong Parameters. How many people here have used Strong Parameters? Good! It has been available since Rails 3.2 as a gem plug-in you could install in your Rails application. In Rails 4, this concept merges into core.
00:20:18.240
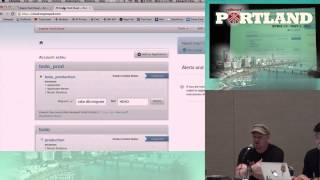
Strong Parameters is a beefed-up replacement for ‘attribute accessible.’ It looks like this: I just generated a scaffold for a widget, which will have a name and a secret. This is just a scaffold for time concerns; I’ll open up my widgets controller scaffolding. Now, at the bottom, you see ‘widget_params.’ What this does is action controller parameters can no longer be bulk assigned into your Active Record models without raising an error unless you’ve permitted them. Calling ‘require’ and ‘permit’ sets up some basic API requirements.
00:21:58.960
In this case, I don’t want people to bulk assign ‘secret,’ so I’m going to remove it from here. We can see this in practice; running the scaffold will bring up my controller. If I add a value, since ‘secret’ is filtered, it will not be bulk assigned, which is a great improvement for security. If I'm a lazy programmer and forget about this, when I run the same code, I will actually get a forbidden attributes error. We should all be glad for improved security!
00:23:40.480
This is good, but there are interesting limitations with Strong Parameters. Most notably, there is a complete absence of type information. Without type information, it’s not possible to differentiate between different scalar types because Strong Parameters allow strings, symbols, nils, numerics, booleans, dates, times, IO objects, and files. This is cumbersome—further down the line, even if I've filtered it strongly, I have to filter again to ensure I'm working on the expected type.
00:24:54.840
This lack of type information also makes it impossible to do any intelligent type coercion on your parameters, which means that you may have to replicate that filtering logic. Right now, I’m feeling that maybe Strong Parameters should be called Weak Parameters instead. It’s not fair to rag on something without suggesting alternatives. I believe the solution lies in a type-safe map or description.
00:26:25.840
The Seahorse DSL does this very simply: it introduces three different complex types: structures, maps, and lists. It adds a handful of scalar types that are user-definable so they are extensible, and then it allows you to layer metadata on top of this.
00:27:11.360
Let me show you what this looks like in practice. Structures are straightforward; in this case, I’m defining a structure with members, which are the possible maximum set of allowable keys. In my example data, if I pass in name: John, age: 40, it validates accordingly.
00:27:53.760
Lists, like structures, have members, but are differentiated in that lists only have one child type, making them homogeneous. Here’s some example data: A, B, C, M, N, O, X, Y, Z. Notably, all of the complex type members can also be complex types.
00:28:34.560
Maps, on the other hand, consist of defined keys and members. In this case, a Seahorse map has designated keys defined by the user, allowing constraints on what keys should be, such as limiting them to numbers or strings, making those user-definable maps type-safe.
00:29:29.600
The default scalar types include anything you might see defined as an integer or string, but you can also add additional types like date times, timestamps, booleans, blobs, and more. This is the basis of a very extensible description of what your parameters look like as they come into and out of your system.
00:30:18.560
Additionally, you can add metadata to assist with documentation and validation. This is where it gets powerful; if you’re building RESTful APIs, you can provide HTTP binding to denote where parameters might appear, such as in the request headers.
00:31:13.440
Revisiting why you need an API: filtering incoming parameters, performing parameter type conversions—once you have that document, you gain something you can crawl or introspect at runtime. You could even statically generate from it.
00:31:48.800
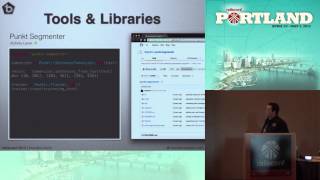
Additionally, you can generate comprehensive API documentation. One of the cool things we’ve done with this is that the documentation for the AWS SDK for Node.js is built using YARD, which allows documentation of JavaScript. For instance, let’s pick a service like DynamoDB. All of this documentation is pulled straight from the model, and we can have arbitrary amounts of documentation; we just use it to dynamically generate it.
00:32:37.280
If DynamoDB were to make a major revision to its API, we can copy this model over to a separate file, version by name, and now we can generate both old and new docs without having to duplicate code. This is an incredible time-saver, eliminating bugs from trying to keep code in lockstep; our documentation is now aligned with our service description.
00:33:28.480
In practice, if I abrir this up, you can see operation-level and input parameter-level documentation generated for the 'News Feed' API. If I go to 'create post,' you can see where the documentation appears. It tells you what’s required, and if you reuse the username type elsewhere in your documentation, that trait will follow along.
00:34:09.840
One of the best features is that once you have a strong description of your service, you can dynamically generate or drive a client with it. The Ruby SDK V2, which is still in progress and not yet released, will consume these models directly. As I mentioned, there are several other live SDKs today that already use this.
00:35:06.560
This is the first app controller to show a simple Rails controller that includes the Seahorse controller module. It's straightforward—this general controller maps operations to actions. It creates RESTful route bindings for you or allows you to go more RPC-like with method names like ‘create post.’ There's no heavy lifting required here.
00:35:50.560
When you get the parameters hash, it has already been filtered. The Seahorse controller loads your API configuration and builds the strong parameters. It also converts all types; it checks the model to ensure that the correct type is casted—for example, an integer will be cast correctly, preventing potential errors during arithmetic operations.
00:37:01.760
Now, let’s fire this up and look at the config routes. As your API changes, there’s no need to keep updating it in several places. This eliminates the need to manually duplicate tasks of updating docs, clients, and route configurations, as dynamic routes will be generated whenever your models update.
00:38:12.960
In this demo, we’re generating more than necessary just to make everything function through the browser. However, each action has a GET version alongside the RESTful verbs, allowing interactions like ‘get user username trevor.’ This shows how Seahorse parses parameters and handles responses gracefully.
00:39:09.760
Let’s look over here at the new AWS CLI, which supports a wide range of services. I have a small wrapper script that loads the service.json file generated by Seahorse and allows me to interact with my API easily—such as running ‘AWS CLI get user username trevor.’ It’s as straightforward as that.
00:40:22.160
What I’m demonstrating here is a sample script written with the Node SDK, which is the production-ready AWS SDK for Node.js. This shows how you can load the Seahorse news feed service definition and call operations like ‘get user’ and ‘get post.’ This indicates the power of using common definitions to drive client interactions.
00:41:00.000
These benefits we gain from all stem from having a document that describes our API. Without that, you would miss out on many of these advantages.
00:41:07.839
Thank you all for your attention.