00:00:16.400
I’ve already tweeted out a link to the slides if you want to follow along at home or you're on your laptop in the back. That's my Twitter handle. My name is John, and we're here to talk about DevOps for the Rubyist soul.
00:00:23.519
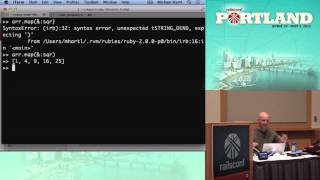
So I want to start with a joke and some audience participation. Raise your hand if you have seen this before and you think you know what it means. All right, now keep your hand up if you verified the fingerprint.
00:00:35.120
As I said, my name is John. I work for Braintree, a company that helps businesses accept payments online. I'm a security engineer there, although in the past, I’ve worked in infrastructure and many different roles. If you are a Braintree customer, I would love to talk to you and get your feedback. Please come find me after this.
00:00:50.079
Every startup has a business plan, and at Braintree, we help these startups with phase three, which is supposedly where they will make their money. However, one of the things we struggle with the most is availability. We have very strict controls surrounding our service availability. Since we provide infrastructure for other businesses, they rely on us to be operational 100% of the time, and we take that very seriously. We strive for no planned downtime.
00:01:11.600
One of the things that aids us in maintaining this uptime is our practice of DevOps. For those of you who are unfamiliar, DevOps is the idea that we can apply the rigorous standards of agile development to the complexities of operations and server management. Some of the methods we use, which may sound familiar if you've been practicing agile for some time, are automation, repeatability, and verifiability. This often resembles testing in methodology.
00:02:01.200
Another goal of DevOps is to facilitate a better relationship between developers and operations teams. Development and operations have a symbiotic relationship, and this is a core principle of DevOps: we are all on the same team, sharing ideas to get our work done without blaming each other. In this presentation, I want to tell two stories. The first is about Braintree's journey toward adopting DevOps and how we developed a DevOps team.
00:02:53.920
At Braintree, we really love Git, as I imagine many of you do as well. Additionally, we have a strong affinity for Ruby, which I presume most of you appreciate as well. Our team comprises individuals from various backgrounds, but the common thread connecting us is our passion for Ruby. This shared interest has significantly influenced the decisions we made as a team.
00:03:40.159
As is common practice, we implement agile methodologies. Initially, we had a physical card wall to track our work, but now, due to multiple locations, we utilize a virtual card wall. Yet, the fun continues. Another practice we embrace is pairing on development work. We pair on nearly all development tasks and, importantly, on all production infrastructure tasks. Having a second set of eyes and hands is crucial when things don't go as planned.
00:04:52.559
To provide a bit of history regarding our agile approach, each card in our physical card wall had colored dots. These dots indicated different types of work: green for new projects and features, yellow for maintenance and support tasks, and blue for infrastructure work. The blue category is where our DevOps work began. As our team expanded and tasks increased, a sub-team naturally formed around the blue work, which we eventually dubbed 'the blue team.' This team was a group of developers trying to define what DevOps meant for our server operations.
00:05:37.919
Ultimately, we were just trying to figure it all out together. The second story I'd like to share is about my personal path to DevOps. I don’t just like Linux; I really love Linux. If Linux and I had gone to school together, I would have aced it and maybe even gone to prom with Linux.
00:06:30.079
When I joined Braintree, we were at the early stages of splitting into focused teams. Because of my passion for Linux, I was assigned to the blue team, although at that time, I didn't know much about DevOps. Fortunately, I had a fantastic group of colleagues who helped me learn the ins and outs of DevOps. If you’re a fan, the scenes in the movie and book may be in a different order, but I assure you I’m getting to the tools we use.
00:07:37.520
Next, I want to go over a couple of the tools we use at Braintree for DevOps, starting with Puppet. For those unfamiliar, Puppet is similar to Chef, which is a competitive tool. If you’re not acquainted with either, they are both ways to manage server configurations in an automated, repeatable, and verifiable manner, echoing the principles we discussed earlier.
00:07:55.280
Puppet operates through a concept called Puppet Master, where you have a Puppet node that controls multiple compute nodes, each running a Puppet agent. We don't use Puppet in this typical way, but it's important to mention as it is commonly presented online. Puppet helps maintain the synchronicity of your servers: once you update Puppet code on the Puppet Master node, it ensures that every node adheres to that code.
00:09:09.839
Let’s take a quick dive into Puppet for those unfamiliar. A simple Puppet code snippet typically begins in a file called site.pp located in the manifest folder. A node refers to a specific server in your infrastructure. For example, we have a server named apple1.qa. In our case, we want to install the Ruby package using the operating system's package provider. On Debian or Ubuntu, it uses apt; on Red Hat or CentOS, it uses rpm or yum.
00:10:12.560
We're ensuring that this package is installed, setting a variable called 'blah' to 'test,' and using that variable within a managed file. Puppet manages file contents in a way that they must always reflect the defined template, and we utilize ERB templates similar to those here.
00:11:16.800
Puppet allows us to organize classes; each .pp file represents a manifest, which can either be a collection of classes or nodes. We're extracting Ruby management into its own manifest file, allowing other users to simply include it without needing to know the inner workings of the code.
00:12:05.840
Another essential component of Puppet is Facter, which gathers information or 'facts' about the system it is running on. You can use gem install facter, as Facter comes with Puppet. When you run the command, it returns various key/value pairs about the system in a system-agnostic way, which simplifies matching nodes. It is particularly useful in a non-homogeneous server environment, allowing matching of Puppet rules to different server types.
00:13:04.959
Puppet also introduces modules, comparable to Ruby gems, which help in organizing your Puppet code around specific idioms, making it user-friendly later on. The typical folder layout for a Puppet module includes files directed at managing specific server needs, packages to install, and services to control. Thus, modules delineate tasks, making intricate configurations simpler.
00:14:32.399
A valuable resource for Puppet users is Puppet Forge, a repository where community-contributed modules can be found to manage various services like Nginx, MySQL, and Apache. Before creating your own module, it's advisable to check there for existing, robust solutions to avoid duplicating efforts.
00:15:47.760
Puppet comes with Hiera, which manages configurations hierarchically, typically using YAML files. At Braintree, we organized our data into a folder called 'data.' In that structure, 'common.yaml' contains settings applicable to all servers, while additional files can be created based on specific criteria, overwriting the common configurations as necessary.
00:17:24.960
Using Hiera, we manage Zen, a virtualization platform for managing virtual boxes, in a YAML file that interpolates other Puppet variables. This configuration demonstrates how we organize our Puppet code, ensuring the process remains orderly and accessible. One insightful saying from a colleague is that Puppet doesn’t manage 'truth' — it maps 'truth' to complexity. We've encountered challenges with having configurations scattered across multiple files.
00:18:34.960
Now, instead of having truth diluted across various manifest files, our data directory serves as the definitive resource. This method allows us to build a model of our desired infrastructure, which Puppet then maps onto our servers. As mentioned earlier, we don’t use Puppet Master and have adopted a different approach: using 'supply drop.'
00:19:28.880
Supply drop integrates Capistrano with Puppet and rsync, developed by a couple of engineers at our company. With Capistrano orchestrating our servers, we determine where to run our Puppet applications. A simple installation of supply drop prepares us for a structured use of Capistrano, where we set up tasks to manage our infrastructure effectively.
00:20:25.919
Our Capistrano configuration involves defining tasks for the entire data center and for individual servers. For instance, in the QA data center, we have two servers: apple1.qa and dbqa. A significant aspect of our Puppet setup is using a custom file named puppet.pp for configurations, deviating from the conventional site.pp designation.
00:21:21.040
The workflow begins by targeting a specific server using a command called puppet noop, which provides a diff of what would change. If conditions permit, we will then execute the commands to install the necessary configurations.
00:22:10.640
Once confident that the changes won’t adversely affect the system, we proceed with further operations, conduct a git commit to maintain alignment among team members about the server configuration.
00:23:26.160
We also run such commands across multiple servers in a range, such as db01 through db12, or even across entire data centers. This gives us a broader view of changes and helps ensure consistency across similar environments.
00:24:42.320
Using Git enables shared changes amongst team members, and we operate with a branch structure tailored for each environment. This methodology supports merging changes, refining configurations tested on QA before applying them to staging and, subsequently, production environments.
00:25:45.760
During our operational adjustments, we take care to reinforce communication within our team, informing others about any significant updates in configurations we have made.
00:26:22.320
From a lesson learned, we strive to operate optimally by avoiding configurations that lead to large, drastic changes. We aim to check in with each other regularly, ensuring that production is always up and making sure we have a partner present during critical updates.
00:27:34.480
Among the key lessons we’ve learned include adhering to the Puppet style guide, using modules early on, enabling Puppet backup, and committing changes frequently to prevent a disorganized system.
00:28:50.720
Lastly, let me speak about Vagrant and its uses. Vagrant assists in constructing virtual machines on local machines, easing the development process. It can be installed through gem, although downloading it directly from their website is recommended for a more stable version.
00:29:54.559
By utilizing Vagrant, we can efficiently prototype software and allow new developers to quickly set up their environment. They merely download the base box and have it provisioned with the necessary configurations via Puppet.
00:31:00.480
In conclusion, I would like to share some humor from the DevOps community. There’s a great Tumblr called DevOps Reactions I highly encourage you to check out. One of my favorites features a humorous take on the struggles of engineers in complicated situations.
00:32:41.440
My name is John Downey, and I work for Braintree. I believe we have around eight minutes for questions, so if you have any, feel free to ask. I'll make sure to repeat the questions for everyone.
00:33:54.240
I will be around after this session, so if you think of anything later, I'm happy to answer any questions you may have.