00:00:05.120
Hey everybody, my name is Austin Story, and I am a tech lead and manager at Doximity. I'm honored to be here today to share lessons that our team has learned over the last several years about how to effectively synchronize data between Rails microservices and do that at scale. I would like to start by painting you a picture of what we're going to discuss over the next half hour.
00:00:23.039
When you have a company with complex data requirements, things can get challenging. Initially, when things are simpler, it's easy to make decisions—especially when you have a Rails monolith following the Rails way. However, as your business grows, so do your data needs and applications. Eventually, you might find yourself with multiple apps, data teams, and application teams, making it harder to keep everyone in sync. Imagine being in a situation with dozens of lines of business, over 70 application developers, and more than 45 data engineers across multiple teams. That's the problem I'm going to address today—how Doximity has effectively synced data between multiple Rails microservices and enabled our data and web application teams to work together.
00:01:18.720
To begin, I'll talk a little about the background of our company, Doximity, which is an 11-year-old Rails-based application focused on being a professional medical network. Our mission is to enable physicians to save time and provide better care to their patients. We offer many modern communication tools for doctors and continuing education options. For example, our Doximity Dialer product has facilitated over 100 million Telehealth calls in the U.S. Additionally, we provide a continuing medical education system where we ingest medically relevant articles for doctors to read and earn credits from. With features like rich search capabilities and secure faxing, we've grown to have over 70% of U.S. physicians and 45% of nurse practitioners and physician assistants as verified members on our site.
00:02:39.480
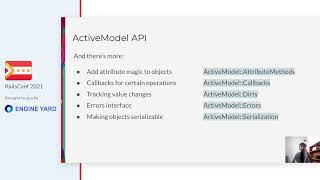
Our growth has led to the establishment of over 10 data teams with over 45 engineers and 20 application teams with more than 70 engineers dedicated to building and maintaining these features. Since April 2019, we have performed over 7.7 billion data updates. Now that we've covered some background, let's define what we mean by effective data syncing. We're talking about data integration within a Rails environment, where you have many Rails-based microservices and different data stores. The question is, how do we move data to and from these sources while respecting application business logic and avoiding disruptions?
00:03:31.680
Before diving into application growth, I want to give a preview of the solution we've settled on: a Kafka-based system. This approach allows our data teams to produce messages while our application developers can consume them independently. In the early days, before we had all these teams and microservices, we had a majestic monolith. Let's summarize how data updates worked in that monolithic application.
00:04:01.680
In a monolith, getting data updates is straightforward, and the focus is always on serving our users—physicians. They care only about accessing the information they need when they want it. Rails excels at providing a rich domain model, managing domain logic distributed across many data stores like MySQL and Redis. When a data need arises— for instance, updating all physicians' first names—it's clear that the Rails developers have a mature set of tools to handle these updates, such as Active Job or Rails Console.
00:05:05.640
Now, let’s talk about implementing improved search functionality for physicians to find peers based on various criteria like name and university. The integration of Elasticsearch can help, but it must remain in sync with user data. Fortunately, this can be efficiently managed with Rails through after_commit hooks in our user model, which can schedule background tasks to re-index users in Elasticsearch. This simplicity of Rails in managing data synchronization showcases how rich domain logic can be effectively maintained.
00:06:59.520
When a business begins to require more data or more experienced data processed, a sophisticated analytics pipeline becomes necessary to gauge product effectiveness based on user engagement. Doximity heavily relies on this pipeline for informed decision-making regarding new products and features. As an example of a complex data need, we’ve developed features that leverage physician profile data, such as first and last names, universities they attended, and their specialties. This data is enhanced by our continuing medical education system which ingests articles and allows us to extract citation information, linking physicians to their publications.
00:08:01.680
This integration allows physicians to see when their work has been cited by others. Achieving this requires careful processes, including ensuring that all physician names are correct. We need to standardize citation names from multiple journal formats, which may vary wildly—some might list names as 'first last', others 'last, first'. Handling common names introduces further complexity and necessitates a matching strategy, including the use of confidence scores based on specialty matches and previous experiences.
00:10:01.080
This complexity in matching CME articles with physician data requires a degree of expertise in data handling. Hence, the integration of data specialists, who may be accustomed to tools like Python and SQL, into our existing Rails infrastructure is essential. We asked ourselves how to make this integration smooth and effective, one possibility being direct database access, but that leads to concerns around data integrity.
00:11:27.480
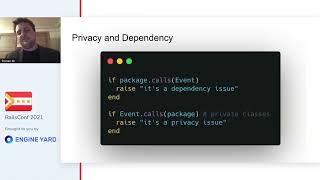
One of the major downsides of giving direct database access is not being able to enforce application logic. Even with the best intentions, processes might not adhere to the established business rules, potentially leading to inconsistent data updates and failures to trigger important tasks like caching or notifications. An alternative approach we explored was creating an admin UI with a REST interface, allowing the data specialists to submit their updates without the risks associated with direct access.
00:12:55.560
While implementing an API does bring certain advantages, such as separating concerns and allowing integration with other clients, it also limits control over client behavior. Batch processing becomes cumbersome due to the need for various tailored treatments for different processes. Thus, we gravitated towards a method we internally termed 'temp tables plus sync', a data update tool that allowed teams to populate temp tables which could, later on, sync with main Rails application tables.
00:14:31.740
The 'temp tables plus sync' approach worked well for a few years, decoupling the data writing responsibilities from the consumption side, but this solution became increasingly difficult to manage as our teams expanded. We introduced additional features and services around the same time, such as a news feed for delivering medical news and another service for facilitating colleague connections.
00:15:37.080
To manage these complexities and support various teams across the organization, we needed a solution that would not only support growth but also continue respecting the Rails architecture. The goal was to achieve effective data syncing without breaking existing business logic when transferring data across services.
00:17:48.660
This led us to implement a Kafka-based architecture, providing a scalable and efficient way to separate data producers from consumers. Kafka became the intermediary that allowed data teams to push messages that application teams could consume without making them dependent on each other. Each application has its own topic in Kafka, giving teams the autonomy to manage their workloads independently.
00:20:56.040
In essence, the data team produces messages to their designated Kafka topics, while the Rails application team consumes these messages at their own pace. The use of a dispatcher in the application ensures that messages are processed correctly based on their type, handling the complexities of data processing through a well-defined importer structure. This allows us to maintain clean separations of responsibilities, and everyone can work independently, increasing efficiency across both teams.
00:23:01.920
We have created abstractions for operations that are self-contained, allowing the data teams to produce messages that include the necessary data and context for the application team to process. This modular approach means that regardless of how the data is modified, the system remains resilient and can handle changes without affecting the overall application.
00:25:50.160
As we continue to refine this system, we’ve learned that placing restrictions on what can be updated and maintaining proper documentation on attributes is crucial. Each message produced through Kafka includes details on the batch, operation, and context necessary for the operation to succeed, providing an efficient pipeline for updates.
00:27:56.760
Moving forward, it’s critical for our application teams to use these operations effectively. The importers that we’ve created ensure that any updates adhere to the established framework. This flexibility allows the system to stay current without compromising integrity, thus facilitating a robust infrastructure that handles both simple and complex data operations.
00:30:00.660
To sum up our journey, this talk about effective data synchronization between Rails microservices has explored how Doximity as a physician-first network has evolved to meet its growing data demands. By utilizing a Kafka architecture, we've been able to manage operations efficiently while allowing our data teams to work independently from the application teams.
00:32:06.720
I want to express my gratitude for your attention, and I look forward to any questions you may have. If you're attending RailsConf, I'll be in the Effective Data Syncing between Rails Microservices Discord Channel. Otherwise, feel free to reach out to me on Twitter at @austinstory36. Lastly, a special thanks to Hannah from our design team for her help with the slides. Thank you again for joining me today!