00:00:19.520
Hello, my name is Josh Schairbaum, and I live in the destination city of the train that Johnny Cash keeps hearing from Folsom Prison. I live in San Antonio. I'm a graduate of the Ohio State University, where I majored in military history, but now I write software.
00:00:27.920
I just finished my third year at Rackspace. We are the service leader in cloud computing, with nine production data centers including one right here in Grapevine, as well as in London, Hong Kong, and Sydney.
00:00:39.520
Our business model is built to adjust to customer needs quickly and efficiently. Rackspace is a founding member of the Open Compute Project, which is open source for data center hardware. We're helping establish designs that hardware companies can build to provide cheap and efficient computing infrastructures.
00:00:52.320
Our goal, along with Facebook, Intel, Arista, and others, is to create data centers filled with vanity-free servers that are 38% more efficient and 24% less expensive to build and run than current state-of-the-art data centers.
00:01:07.479
Together with NASA, we open-sourced the cloud as co-founders of OpenStack, a massively scalable cloud operating system designed from the ground up to provide private and public clouds with standards to prevent vendor lock-in. This benefits both cloud providers and customers.
00:01:13.119
However, many industry marketing gurus will be surprised to know that even the cloud runs on physical hardware. There are still situations where certain pieces of physical infrastructure make the most sense. The biggest and best computing environments in the future will be a hybrid of physical and virtualized resources.
00:01:26.920
You're not here to listen to me give a 40-minute marketing pitch about Rackspace. I'm standing here today to talk about how members of Rackspace's global data center and infrastructure teams work together to automate network device provisioning in six data centers across four continents.
00:01:34.040
Specifically, I'll present a case study of one of the applications that delivers an API in this process called Firekick. I thought Brian Mart Morton did a great job yesterday explaining some of the trade-offs his team made at Yammer.
00:01:43.959
It's been interesting to me that many of the talks we've heard have described conditions in a less than ideal world. I want to continue that discussion by sharing three simple examples of design choices we made to solve three separate problems. None of these decisions were made in a vacuum, and we will discuss potential approaches and the trade-offs we've made.
00:02:05.799
It's always important to know the context of these decisions. But there's another question: why do we often find ourselves living in a less than ideal world? Interacting with things outside of your control can get messy.
00:02:18.560
Sometimes, it's accidental; other times, it feels a bit more intentional. For the purposes of this talk, when I say 'device,' I mean a hardware firewall or load balancer.
00:02:29.080
In order for these devices to work with a customer's environment, additional configurations need to be made—setting up static routes, access control lists, ports, and interfaces. We generally call these files collectively 'configs.'
00:02:39.320
Here's a diagram of a fairly common setup for many of our customers, who have compliance and regulatory requirements. They have a dedicated firewall and load balancer logically placed in front of a combination of physical hardware, a private cloud, or connections to the public cloud.
00:02:52.640
The networking devices for this type of environment are essential; they are the only way the systems can access the internet. There are many automation tools for tasks at this level, but network device automation is a bit more challenging due to variance in device operating systems and a lack of automation capabilities on the devices.
00:03:01.160
Let me tell you about how this works at Rackspace.
00:03:12.640
Rackspace started in 1998 with just three guys in a dorm room at Trinity University. Over the past 15 years, the company has experienced exponential growth; we're now over 5,000 employees. Given that our business model emphasizes providing services above and beyond customer expectations, automation has often taken a backseat to just getting things done.
00:03:30.160
As we begin to face the type of scale we anticipate the open cloud will deliver, we've prioritized automation throughout the company. In Robert Highland's novel The Rolling Stones, he has a fantastic quote about technology implementations that aligns with our experiences.
00:03:41.680
He says that every technology goes through three stages: first, a crudely simple and quite unsatisfactory gadget. In the past, when a device would be configured at Rackspace, people would pass around copies of existing configs and hand-edit them before copying and pasting them into a terminal. This was obviously crude and unsatisfactory, leading to a lack of standardization and problems in troubleshooting.
00:04:03.160
The second stage involves an enormously complicated group of gadgets designed to overcome the shortcomings of the original, achieving somewhat satisfactory performance through extremely complex compromise. A few years later, a team developed a config file generator as part of a web application; templates and variables for these config files were stored in a database and editable via the web app.
00:04:24.080
When someone wanted a config, they had to log into the web app, select a template, input some values, and have the file generated and displayed as plain text in the browser. However, they still had to copy and paste this file into a terminal on the device.
00:04:36.920
The trade-offs were that standardization improved slightly, but the opportunity to hand-edit and customize still existed. Furthermore, people still had to take time to generate these configs and copy them to the device.
00:04:50.360
Each segment within Rackspace began to want their own configurations, yet they wanted to use the base templates. These templates evolved into massive nesting of if statements and various different configurations based on device attributes, making them difficult to maintain.
00:05:09.480
As a result, some of the configs became stale, which meant that not only was the system not automated, but the things put on the devices actually had to be reworked. Automation that requires rework is probably the worst situation.
00:05:23.080
In the final part of the quote, the third stage is a final proper design. Clearly, what we had was not good enough, so several groups came together to take ownership of the problem and set the goal of automating the process once and for all.
00:05:40.560
Not only would every device be delivered to the support staff with a standard set of configurations, but it would also be customized for routing all customer traffic. Additionally, the switches and aggregators in the cabinets above these devices would also be configured correctly with the proper VLANs.
00:05:56.560
The intent was for support staff to spend their time adding additional configurations and providing extra support for customers' needs. This wasn't going to be an easy task, but multiple existing pieces were available to build from.
00:06:09.160
We called this process 'Kick in the Rack'—an existing process for servers that we modified for firewalls and load balancers. When a device is changed in the global configuration system, this triggers a series of events that generates the necessary config, places it on the device, configures the networking, and marks it as ready for support staff.
00:06:24.760
An internal orchestration engine processes these events and makes calls to various services within the company. One of these services stores all the IP information, known as Environment Manager, while another handles all communication with the devices, called the Fire Engine.
00:06:40.280
However, a crucial service that was missing was the one that could generate configurations and establish authority on how a device and its environment should be configured. The entirety of this process was automated by at least six different groups using a combination of Perl, Ruby, Scala, Python, Erlang, and C.
00:06:57.140
There was, however, something that had some of the information we needed to provide this missing service, and it had an idea about how to generate a configuration. If this functionality were exposed as part of a service, it would fill the gap.
00:07:10.800
As we tried to determine where the lines between these services would fall, a couple of questions arose: did this functionality belong on its own, or did it belong as part of an existing service?
00:07:25.680
In Eric Raymond's book, The Art of Unix Programming, he describes an abstraction used by Unix implementers when designing their systems known as the rule of separation. This principle denotes the division of mechanism and policy, which can be applied at virtually any level of software.
00:07:42.799
A mechanism is something that performs work. For example, the Fire Engine, which is our application written in Erlang that communicates with the devices, is a mechanism used to achieve results. Environment Manager provides a policy for IP environment data, and the orchestration engine is the mechanism for event processing.
00:07:58.880
A policy system describes how work should be done; Chef cookbooks are great examples of policy for Kick in the Rack. Firekick would establish the policy on what kind of configuration belonged here. Raymond's example in the Art of Unix showcased that if this rule is applied inflexibly, it can cause problems.
00:08:15.440
It’s helpful to apply this pattern when deciding where functionality belongs in services, so we began working to extract Firekick from the existing web app.
00:08:29.959
A constraint in this process was that the existing web app’s functionality had to continue working throughout. This meant that while extracting Firekick, we had to write the client software at the same time.
00:08:44.720
This experience ended up being advantageous, as it provided insights into how the service could be leveraged. However, a mistake we made was waiting too long until all the functionality was available before we launched.
00:09:05.880
We should have focused on launching the smallest viable component, whether it was the templates or the variables. Though we aimed to launch with a minimum viable product, we didn’t make a great decision about what was truly minimally viable.
00:09:19.920
While the application runs on Rails, specifically the Rails API gem, we strove to maintain as much framework agnosticism at the domain level as possible. We did manage well, and it’s not far-fetched to think we could easily split off some parts to run in Sinatra or even Erlang.
00:09:37.440
We chose not to lock into a specific framework to establish the policy for the controllers. While we largely adhered to the Rails way, we knew this came with the cost of convenience.
00:09:49.120
However, we valued the freedom this flexibility would afford us in the future. To illustrate how we faced a problem and selected one approach over another, I’d like to discuss three areas of trade-offs.
00:10:02.480
The first issue working against us was the relative inexperience our team possessed within the networking domain. Recently formed from various segments within Rackspace, we had yet to work on a sustained project.
00:10:18.640
These terms aren't interchangeable, and listening to two network security professionals can be confusing as they will use different terms for similar concepts. To address this, our solution was to focus on establishing consistency in communication internally and externally.
00:10:38.759
When we generated a config, I often copied a few lines and handed it to a netsec person to ask for the correct name. I wanted to ensure that the language we used consistently aligned with theirs.
00:10:53.200
Through this repetition, we achieved success. Automating a process involves as much organizational change as it does technical change.
00:11:09.280
A concern with our second approach to automation was that each group wanted their own special configurations for the templates. In some cases, this was expected due to different use cases and customer types.
00:11:21.640
However, we aimed to limit this as much as possible. We wanted Firekick to generate configs that represented the common denominator. In instances of differences, we encouraged collaboration between the two groups to resolve conflicts.
00:11:37.440
This effort established much-needed standards at Rackspace. When you tell someone that you are going to automate a process, it fosters a willingness for them to compromise, as they recognize that they’re getting something in return.
00:11:52.480
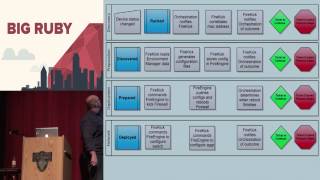
One of the most effective tools we employed to achieve this was the swim lane diagram, which represents the state of the device as it progresses through the Kick in the Rack process.
00:12:10.080
In the diagram, items in blue indicate statuses in the global configuration system, while green represents actions and red indicates errors. Each lane denotes a logical grouping of actions needed to move from one status to another.
00:12:25.920
For instance, the top lane 'Discovery' outlines everything required to change a device's status from 'racked' to 'discovered.' This clarity was vital, as it facilitated knowledge sharing and troubleshooting.
00:12:39.640
If someone pointed out that a device failed during preparation, everyone knew exactly the state of their systems at that moment.
00:12:55.440
The benefit of this thorough understanding extended into our codebase as well; we intentionally selected a specific naming approach that aligned our internal language with the terminology used throughout the swim lane.
00:13:08.160
Everyone knows the adage about naming things being one of the hardest problems in computer science. The challenge lies not only in finding the correct name but also navigating natural tendencies for inconsistency.
00:13:25.840
We focused on employing a consistent naming approach based on the swim lane document, opting for communication clarity over personal notions of correctness.
00:13:43.040
Here, I present an example of the directory holding the Firekick components, specifically organized according to each swim lane. You can see we've named them exactly as labeled in the swim lane: Discovery, Preparation, Deployment, and Network.
00:13:58.720
In our simplified swim lane example, I’ve omitted error handling, logging, construction, etc. Instead, I want to emphasize the perform method, which begins by calling device discovery and manages the logic for that swim lane.
00:14:15.960
If an error occurs, we briefly capture it before re-raising to ensure that orchestration remains informed of any changes. The crucial point is that we think of discovery in a common way, providing a single reference for troubleshooting.
00:14:28.560
The advantages of maintaining a ubiquitous language lie in learning collaboratively and facilitating easier troubleshooting. However, a potential pitfall of aligning with this domain correctly is the risk of inconsistent naming by others.
00:14:43.440
If terminology starts to diverge, the code must also be updated to address changes and mismatches. This trade-off is straightforward.
00:15:00.240
Yet, even when establishing a common language, maintaining synchronization isn't guaranteed. Sometimes, consumers of your service make their own decisions, affecting flexibility.
00:15:16.640
In this process, the orchestration engine serves as the primary driver, receiving events and notifying the next service of required actions, necessitating a highly configurable setup.
00:15:32.240
When device automation commences, and the device's status transitions to 'racked,' orchestration notifies Firekick of the event via HTTP. We aimed to follow REST practices as closely as possible while designing our URIs.
00:15:46.480
We desired to establish the same ubiquitous language in our API resource endpoints as we did in our codebase. For example, we could nest swim lanes under device resources.
00:16:01.840
However, the realization came that ensuring unique URL configurations with different events was cumbersome. The orchestration team, being a global group, lacked the resources to make adjustments quickly.
00:16:16.240
After considering our options, we decided it was more practical to shoulder the cost of change ourselves, as it was considerably lower for our team than for theirs.
00:16:32.160
Thus, we opted for a more general approach, creating a single URI for the orchestration engine that utilized a friendly name of the current event across various steps.
00:16:47.640
We named this resource 'kicks' instead of swimming lanes to represent the entirety of the process. Now, they can POST to this URL without requiring extensive changes.
00:17:02.400
The code implements a simple Rails controller create method for a POST action, allowing a new kick process to be instantiated along with the respective device and parameters for the step.
00:17:16.960
The kick process utilizes a class method facade to create a new instance before calling start on that instance, returning itself.
00:17:31.120
A notable aspect of our implementation is the ability to chain multiple steps together, allowing multiple swim lanes to progress in tandem without interruption.
00:17:46.560
The benefits of our approach maintain flexibility while adhering to our domain language, effectively isolating an inflexible customer as much as possible.
00:18:01.440
This enables us to define boundaries around our application and create a more efficient workflow. Now, to share a final example of a trade-off made to eliminate bottlenecks.
00:18:17.960
Late in the development process, we encountered a roadblock necessitating significant code development to access existing data sources. A couple of team members were working on this, but scaling rapidly would slow productivity.
00:18:34.880
Due to our newness to the domain, we weren't entirely clear on which abstractions to begin using. In the configuration, different sections required extensive data munging, which added complexity.
00:18:51.960
Considering these factors, we were past our deadline, though there was no external pressure for immediate results. However, our internal timelines motivated us to expedite the process.
00:19:07.440
To alleviate bottlenecks, we shifted focus toward creating service objects that encapsulated functions into smaller manageable pieces. These service objects assisted in generating sections of the config file.
00:19:23.920
A key benefit of this approach was the expanded surface area of our application, allowing multiple team members to work concurrently without needing to interact with one another's efforts.
00:19:43.520
This method encouraged individual discovery, as team members collaborated closely with networking professionals to obtain the data necessary for their specific goals.
00:19:59.600
Despite not being optimal, we prioritized speed of delivery to maintain the anticipated launch date for our product. Here’s one example of where we utilized service objects effectively.
00:20:16.640
In the 'device discovery' example, we maintain intuitive interaction with data captured from the API for the Fire Engine, simply iterating through it, identifying devices with their associated MAC addresses.
00:20:33.680
When powering these devices, they broadcast their MAC addresses without knowledge of their corresponding device numbers in the global configuration system.
00:20:50.960
Now, with the substituted service object concept, we encapsulate operations into dedicated classes that streamline the process of identifying MAC addresses and correlating them.
00:21:06.320
While common in programming, individuals often resort to using raw data instead of applying logic and structure. This encapsulation aids testing since we already know the type of objects we expect to work with.
00:21:22.560
This confidence allows for better troubleshooting, as we can isolate issues easily during testing rather than needing to trace through convoluted data structures.
00:21:39.680
Consequently, we enhanced our application’s surface area, enabling parallel work among team members, though acknowledging some likely duplication in efforts.
00:21:56.880
The trade-off for speed of delivery and domain understanding took precedence over development coherence at this stage.
00:22:12.640
I've shared three examples of trade-offs made during the development of Firekick. We evaluated our situations in each instance, arriving at various conclusions, emphasizing the importance of context.
00:22:29.200
Being aware of the trade-offs inherent in development is crucial—what do you give up, and what do you gain? Each circumstance will differ, and sometimes, you'll want to take a general approach.
00:22:44.320
Other times, a more specific solution aligns better with your goals.
00:22:57.840
By establishing a ubiquitous language, remaining flexible, and expanding our application surface area, we succeeded in automating a complex process.
00:23:07.160
What previously took days now takes minutes, allowing the Rackers we support more time to build new products and ensure that our customers have the necessary tools to achieve their goals.
00:23:19.680
This hopefully includes all of you someday, if it hasn’t already. Thank you.