00:00:16.100
Hi everyone, my name is David Padilla. You can find me on the internet with my nickname 'dabit,' which is my Twitter handle and GitHub account. I run a company called Crowd Interactive, based in Mexico, and we are probably the largest Ruby team down there. Unlike many of the companies at RailsConf, we're not hiring; instead, you can hire us to do your work. We also prioritize training over poaching engineers from other companies. I don't quite understand why so many companies are spending money on hiring annoying recruiters when they could invest in sponsoring events like this, local user groups, or scholarships to bring in college students and raise awareness of our work. We're trying to do our part—our little grain of sand—through an initiative called Mágma Conf. We run the only Ruby conference in Mexico, and it's going to be awesome this year. You should probably come; we'll have Santiago Pastorino, great Pollock, and Brian Lyles in an exciting showdown. It takes place in the beautiful town of Antonio, Mexico, from June 5 to 7. You can find more information on our website or just ask anyone sporting a conference T-shirt, and they would be glad to provide you details.
00:00:49.610
My talk today is titled 'From Rails to the Web Server to the Browser.' Let's discuss the life of an HTTP request, especially in the context of a Rails application. The first thing that happens is a user types a URL into their browser, which then sends an HTTP request to the web server. The web server processes this request and forwards it to the web framework. The framework, with its complex code, processes the request and generates a beautiful HTML document that gets sent back to the browser, where it gets rendered. In simpler terms, this interaction involves three primary entities: the browser, the server, and the framework. My talk will focus on the various components that facilitate this interaction and the Ruby code that makes it all possible.
00:01:58.789
Let's begin by examining the right side of the diagram, specifically the communication between the web server and framework. This interaction is made possible by a library called Rack. Rack serves as an interface between web servers and frameworks in Ruby, establishing a common agreement on how they communicate with each other. This standard allows various servers and frameworks, such as Unicorn with Rails, Puma with Sinatra, or Thin with Padrino, to work seamlessly together. The only requirement for this interaction is a single point of entry: a class that responds to the 'call' method. This class receives the request headers and returns an array containing three elements: the response code, the headers, and the response body. The HTTP response code must be an integer, while the headers are returned in a hash, and the body must respond to each.
00:03:42.980
Previously, in Ruby 1.8, the body responding to each was quite straightforward. However, starting from Ruby 1.9, strings no longer respond to 'each,' necessitating certain workarounds. Throughout the code of web servers like Thin, Puma, or Unicorn, there is a piece of code that sends headers to the application object and invokes its 'call' method. Conversely, on the application side, this method must be implemented to return the three-element array discussed earlier. Another essential component for a Rack application to function is the 'config.ru' file. This file includes the required information to start the server and run the application. You can technically place all your Ruby code in this file, but that would be messy. Instead, we typically require additional files and specify the instance that Rack will utilize to handle requests.
00:04:48.090
Let’s create a quick example of a Rack application. As mentioned, all you need is a class that responds to the 'call' method and returns an array of three elements. You will also need the 'config.ru' file to specify the load path and require the necessary files. To start a Rack application, simply use the 'rackup' command in a directory containing the 'config.ru' file, which will automatically launch your server on port 9292 by default. Now, let’s explore Rails. You're likely familiar with the 'rails new' command, which creates the basic skeleton for your app. If you look closely at the files generated, you will find a 'config.ru' file, because all Rails applications essentially function as Rack applications. This means you can also use the 'rackup' command on any Rails application to start it, and again, it will listen on the default port 9292.
00:06:45.110
Now, let’s make our Rails application perform an action. We’ll add a controller with a simple action that returns the text 'Hello, World.' All we need to do is route to that controller’s action. After starting the server, we can use Curl to check if everything is working as expected, and we should receive 'Hello World' as the output. Now that we’re following Test-Driven Development (TDD), let's create a quick test using the Net::HTTP library to verify that our server is returning the correct response. When we run our tests, we find that they pass, confirming our code is functioning correctly. Next, I’ll introduce you to the Pry gem, which enhances the Rails console experience. If you haven’t tried it yet, I highly recommend it. Simply add it to your Gemfile, specifically including 'pry-rails,' and when you start a Rails console, you'll get a Pry console instead of the standard IRB console.
00:08:41.070
Pry offers numerous advantages; for example, it allows you to change directories into objects. When I navigate into the Rails application object, the context automatically adjusts. You can list all the methods available for that object using the 'ls' command. Among them will be the 'call' method, which is crucial as it serves as the entry point for any Rails application. Another useful trick in Pry is using the 'show-method' command, which reveals the specific piece of code that executes when you call a method, along with relevant details like file name and line number. Now that we've identified the 'call' method, let's explore the three headers that are necessary for making a Rack application work.
00:10:45.300
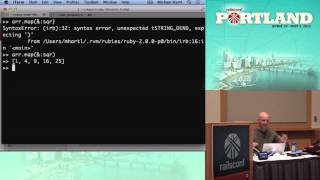
For a Rack request, you need to specify the request method (e.g., GET), the path, and pass a Rack input object, which represents the request stream. In this case, we can just use an empty string, and that suffices. If I forward these parameters to the 'call' method of the Rails application object, it should return an array containing the three predetermined elements because that's the expectation when using Rack. Transitioning back to our console, I’m going to assign whatever the 'call' method returns to a variable. The output looks like a substantial amount of code, but ultimately, it's just an array. Let's inspect the first element of the array, which indicates the status code of the response. It's an integer, which is satisfactory. The second element provides a hash containing the response headers, while the final element represents the application's body, allowing us to see the response that matches the expected output.
00:12:27.450
This demonstrates the standard behavior of a Rails application; the Rails application object responds to the 'call' method, and web servers send the request to that object, allowing Rails to handle it. Now, let’s revisit the small Rack application I created earlier and get it to produce a similar response. We expect it to return a status code of 200 and the necessary headers, particularly the content length. If we don’t specify the content length, the server will throw an error. We’re packaging the content in an array since, as mentioned, strings in Ruby 1.9 and above do not respond to 'each.' Although this is okay for demonstration purposes, the preferred approach is using a StringIO object, as it's more suitable for production. Running our earlier tests confirms that this Rack application parallels the functionality of the Rails application using fewer lines of code.
00:14:10.339
Now let's discuss the other side of the HTTP request lifecycle: the communication between the browser and the web server. Be forewarned; this code can become complex. We're primarily interested in locating code within the web server that facilitates passing the request to the application object and invoking its 'call' method. For this example, we’ll look at the code for Thin, as it's relatively straightforward and written in Ruby. When you initiate a Thin server using the 'thin start' command, it triggers a method defined in the thinserver.rb file that invokes the 'start' method on the server class. This method receives the binding IP address, port number, and the application instance that will handle incoming requests.
00:15:51.690
Upon inspecting the code within the start method, it raises an argument error if no application is provided. If the binding address and port details print out for the user's reference, the method subsequently calls 'start' on a backend object. If we explore the server class code deeper, we will find the select_backend method, which selects among various server options: Thin, Puma, or TCP. The TCP server class implementation is essential, particularly the 'connect' method, which activates the actual TCP server. It works through event machine—an efficient library used to manage connections. This allows you to handle incoming data with various methods for different events like accepting connections, receiving data, or handling disconnections from the TCP socket.
00:17:42.730
The only requirement to start a server using event machine is to define the IP address and port with an associated class that will respond to events. After reviewing the Thin code, we see that it initiates a server and specifies the host, port, and connection object. This brings us to the Thin connection class, specifically the 'received_data' method. This method processes the incoming request; once parsed successfully, it introduces a new Thin Request object, which is responsible for reading and converting the request into a format that Rack recognizes. The parser used is a wrapper written in C, called the Mongrel parser, which has been highly regarded in the community for years.
00:19:53.500
When we parse an HTTP request with the Thin parser, we can initiate a console to create a new request object and invoke its parse method. Once parsed, the process yields a hash containing headers relevant to the request like method, path, and other attributes. This parsing mechanism is crucial as it translates the request into a format usable by Rack. Next, we can examine the process method in the connection class for further context. This method processes any preconditions or modifications needed, such as adding the client's IP address and additional headers required for the request. Ultimately, this layer ensures that the request object is properly formatted before sending it to the application object.
00:21:13.092
As defined earlier, once the request object is parsed, we call the application object while passing the parsed request, which returns a response. This response should again be in the same array format containing a status code, headers, and body. Following that, the Thin server uses the post-process method to format the response into HTTP format that the browser can correctly interpret. In contrast, Unicorn does not utilize event machine for its server processes. Instead, it adopts a Ruby IO library implementation called KGI. While I chose not to include code for Unicorn due to its complexity, I can assure you that Unicorn delegates the responsibility of invoking the call method, similar to Thin. In both cases, the Mongrel parser plays a critical role in parsing requests.
00:23:09.759
In summary, we understand that a web server like Thin actively listens for connections on a designated port. When the browser sends an HTTP request, Thin transforms this request into a format Rack understands before forwarding it to the web framework, which handles its own tasks and returns a structured array with the essential elements. This array is then restructured into an HTTP request, which ultimately gets sent back to the browser for rendering. Now, using the knowledge we've gained, let’s develop a basic web server. We will create a new file and include the necessary event machine requires, defining a class that implements the 'received_data' method to handle incoming requests. The code at the bottom will start the server, listening on port 9292.
00:25:03.240
After launching our server, we can execute our tests to confirm functionality. The server should print out the raw HTTP request data it receives. Next, we can enhance this by integrating the Thin parser, turning the raw request into a usable hash. Once the request is in hash format, passing it to the Rack application allows us to expect a response containing the status, headers, and body. Running our code alongside the previous tests should yield results closely mirroring the expected structure including content length and response body with 'Hello, World.' Finally, we wrap this successful response in a format suitable for HTTP, iterating through the headers and contents precisely as required.
00:27:10.784
Once we've structured our complete HTTP response incorporating the necessary headers, we run our tests yet again. If they pass successfully, it confirms that our newly created web server is capable of handling requests and responding as expected. In theory, we can connect this setup with the Rails application by updating our files to require the Rails application configuration, effectively using this server to handle Rails requests. After making those modifications, starting the server and executing tests should verify if everything is operating correctly. Just to reiterate, remember that production web servers and frameworks exist for a reason; they are built to efficiently handle traffic and requests. This exploration is more of an academic query into the underlying processes to fully grasp how components work in sync. I'll share the code I utilized on GitHub later, and I’ll also tweet about it, so you can check it out if you’re interested. That concludes my talk. Thank you for your attention!