00:00:11.750
Thank you for coming. My name is Braulio, and I work for ActBlue's technical services. I would like to start with a question: how many of you have used ActBlue to make a donation?
00:00:17.430
Wow, quite a few! How many of you tipped? Not so many. But for the ones who did, thank you! I stole the title for this presentation from Bernie Sanders.
00:00:28.529
He was saying that we need a political revolution. Sanders made small dollar donations popular, but he is only one of more than 17,000 organizations that have been using the service for the last 13 years. It's not only political; we also provide the service for nonprofits. In fact, ActBlue is a nonprofit itself.
00:00:50.180
In the first quarter of this year alone, we had 3,000 organizations using the platform. Our Rails application is 12 years old. So, how does it work? Let's say Jason in the back, who works here, wants to run for City Council. I’m sure he would be a good City Council member, but he needs money to promote his campaign, and he would like to get donations.
00:01:24.540
Of course, he cannot process credit cards by himself. What he will do is go to ActBlue and set up a page. From that point, we will process credit cards using that page. Once a week, he will get a check. We also take care of the legal part, which is quite complicated, and we handle compliance. There are multiple reports that must be sent when conducting political fundraising or for nonprofits.
00:01:54.810
We provide additional tools for campaigns, such as statistics. A donor can save their credit card information on our website, so the next time they donate to the same organization or a different one, they won’t have to enter anything. It will just be a single-click donation. So far, we have 3.8 million users and we have raised $1.6 billion in 31 million contributions over the last 13 years. We like to see ourselves as empowering small dollar donors.
00:02:50.639
How many of you don’t know what Citizens United is? All of you know? Okay, just in case someone doesn’t know: Citizens United is a ruling by the Supreme Court that allows an unlimited amount of money to promote a political candidate. This means a few people with lots of money can have a lot of power in the political process. While we do nonprofit work, we started on the political side and we like to have lots of small dollar donations, which gives many people with little money the same power.
00:03:31.739
This is how the contribution page looks. If Joseph, a person here, has never visited the website before, it will be a multi-step process: first, he enters the amount, then on the next step, he enters his name, address, credit card, etc. This is a nonprofit, by the way. In this case, it is an Express user donor which recognizes me; it says, 'Hi, Braulio.' So, if I click any of those buttons, the donation will process right away, and I don’t have to enter a card number. That's what we call a single-click donation.
00:04:00.150
During the year in February of last year, Bernie won the primaries in New Hampshire, the second state with primary elections. He won big after Iowa, and he gave his victory speech that night. I'm going to show a little clip from there right here: 'Right now, across America, my request is please go to berniesanders.com and contribute right away. We felt the Bern.'
00:05:03.190
The first spike in requests per minute was about 330,000. The second one, contributions by credit card payment, was 27,000 per minute, or about 40 per second. That's a lot, considering a credit card payment is expensive to process. The reason I chose this graph is to stress the importance of continuous performance improvement; it's not something that happens overnight. We were able to handle this spike pretty well; some donors didn’t see the Thank You page, they only saw the spinner. After donating, they never went to the next page, but we never stopped receiving contributions.
00:05:46.590
There was no gap, indicating that the service was never down. Over these 13 years, every time we experience high traffic for any reason, we analyze the situation. We ask ourselves, 'Is there a bottleneck? Can we improve it?' This presentation is about all the experience we’ve gathered during the years.
00:06:18.310
The first thing we have to do is define what we are going to optimize, which will depend on the business. In every case, it will be different. For example, in an e-commerce website, it’s likely that the response time on browsing the catalog will be crucial. In our case, it’s quite simple: we need to optimize the contribution form and how we process the contributions. Processing requires more effort than simply loading the form.
00:06:54.060
In the center, we have our servers that handle the web service calls necessary to execute a payment. We have a vault for the credit card numbers, and all these sensitive numbers are stored securely—which is essential. The first step is to obtain a token to process the credit card. Once we have that, we also need to obtain a fraud score from an external service. After that, we work with the bank. The first step for processing credit card transactions is to make what is called an authorization request. This request tells us whether the payment is approved, and at that point, no money has been transferred. If approved, we receive an authorization number; if declined, we move on.
00:08:01.590
After receiving the authorization, we have to make a second request to capture the payment; this also requires a post to the bank. If this second step is successful, the bank will confirm the transaction. Additionally, we want to send an email receipt, as most organizations want to be informed as soon as they receive a contribution. An important aspect to note is that even with multiple transactions happening simultaneously, it is crucial to understand how much load our systems can handle.
00:09:19.920
We have a high-volume task; processing many donations introduces a scaling challenge, which we have to address quickly and efficiently. I am going to present one approach and will show several solutions for each one, explaining how it works, how it is implemented, and discussing relevant code. However, there will be costs associated with these solutions.
00:09:57.440
This metric shows contributions per minute; on the X-axis, we have time, while the Y-axis displays the number of contributions. Something happened here: there was a spike in contributions when Bernie won in Indiana, which we called one of the 'Bernie moments.' I have another graph that correlates traffic and contributions. With metrics, just having numbers is insufficient; we must visualize them in graphs to make correlations easier.
00:10:27.830
Through correlating our metrics, we can determine the number of contributions processed against the pending contributions. In a well-functioning system, there should be no correlation between these two; if pending contributions are increasing while contributions are also increasing, this means the service is saturated and unable to process transactions at the required rate. In this case, we had the ideal situation.
00:11:00.000
Latency is another important metric, which refers to the time interval from when the contribution is created to when we receive an authorization from the bank. In our case, this takes about 2 to 3 seconds.
00:11:51.699
Regarding metrics, we utilize a Ruby gem called StatsD. I create a new object for the host name, as I need to be able to track multiple calls. The second instruction involves drawing the signal and generating data points. We also measure timing methods, including time intervals from the creation of the contribution to when it is approved.
00:12:53.640
You can visualize metrics using tools like Graphite, and it is important to monitor CPU, memory, and disk use. I mentioned logs; while they are not metrics, they are vital for diagnosing issues.
00:13:26.970
The architecture must support multiple servers. It doesn’t matter how fast one server is; when you start handling increased load, you will need to add more. The diagram illustrates multiple machines running, with each machine housing threaded web servers. A load balancer acts as a crucial middleware that distributes incoming requests to these several hosts.
00:14:47.430
You can implement load balancing through software or hardware solutions. In this case, I have provided examples of utilizing Nginx as a poor man’s load balancer, which is free and effective. I define IP addresses of multiple hosts and configure which requests to pass to the backend block, using options like random, round-robin, or sequential algorithms for request distribution.
00:15:47.590
However, there are issues to consider. For example, in platforms like Heroku, one surprise is the lack of a shared file system, meaning files uploaded in a browser are stored only on one host. If the subsequent request comes from another host, that file won’t be available. To address this, one option is to utilize Amazon Web Services S3.
00:16:14.300
Another solution involves sticky sessions, where the load balancer consistently routes requests from the same user to one specific host. Furthermore, Rails applications have built-in session management, allowing you to share application state efficiently across servers.
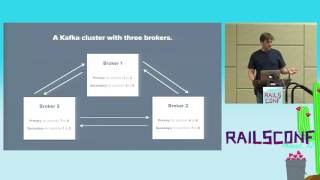
00:17:07.090
Given that multiple servers connect to the same database, connection limits become an issue. To alleviate this, we can utilize Postgres replication, creating read-only copies of the database that allow us to distribute read requests without overloading the main database.
00:17:47.660
Besides connectivity, if the load balancer goes down, it doesn’t matter how many servers are operational. In our case, we have a CDN, which works alongside the load balancer to provide failover security.
00:18:35.260
Caching is an immensely popular strategy in performance optimization. Caching means storing copies of data to reduce loading time. It can occur at different layers: in browsers, on web servers, and even inside networks between them. I recommend using caching services like Fastly, which function as a CDN, effectively handling requests and easing the load on main servers.
00:19:16.240
When a browser requests a document for the first time, it reaches our origin server. However, with CDNs, when users in different geographic locations make similar requests, their browsers will instead interact with the nearest point of presence (POP), which significantly improves loading times and saves server resources.
00:20:16.320
With a high cache hit rate, we can minimize the load on our servers, since only 3% of requests need to reach the origin server. To control caching, two main factors are important: how long data is retained in the cache and how to purge outdated data when necessary.
00:21:00.120
The 'Cache-Control' header is one mechanism that governs this, specifying how long data remains valid in caches. Another mechanism is called 'Surrogate-Control,' which works specifically with CDNs. Implementing tags for documents allows for easy data purge if necessary, without having to individually identify and refresh every piece.
00:22:01.720
One complex aspect is using Varnish Configuration Language (VCL) to customize these caching behaviors. It grants significant control over how requests and responses are managed at the network edge.
00:23:06.130
As we have discussed, caching normally improves performance, but situations do arise where we need personalized experience. In our application, we must dynamically update certain data depending on the user’s context. Here, JavaScript plays a vital role to present varying information based on the data input.
00:24:01.250
Separation of concerns is also essential. We have distinct applications that handle different aspects of our operations, such as a tokenizer and a vault application. This separation allows us more compliance because if we don’t have access to sensitive information, we’re not liable for the security of that data.
00:25:22.220
While the general trend in system design is to facilitate ease of testing and iteration, maintaining simpler architectures is vital for scalability and operational efficiency. Each layer should perform distinct functions without being tightly coupled.
00:26:07.080
In our tasks, we need to delegate long-running activities to job queues to avoid blocking web server threads. Processing bank transactions might take a considerable amount of time, so it’s essential to save those jobs for later execution.
00:26:57.870
If there is any failure in the queue such as authorization issues or the bank being down, we can still handle donations and inform customers. Moreover, we can retry processing any failed tasks later to ensure no contributions are lost.
00:27:39.160
In our system, we use Sidekiq as our job processing solution, which enables us to asynchronously handle tasks such as sending confirmation emails or processing settlements while avoiding delays on our web servers.
00:29:04.640
When implementing these systems, we also bear in mind that different operational hurdles can arise. The jobs in the queue might fail due to various conditions, from system downtime to network disruptions.
00:29:56.500
However, maintaining thorough logging practices is essential; logs help us debug and monitor operations to ensure processes go smoothly.
00:30:58.430
As I bring all this to a close, I’d like to emphasize the importance of scalable architecture. When designing software, it's crucial to incorporate considerations for scaling from day one, so as to prevent issues as the system grows. System design must remain flexible and consider future growth opportunities.
00:32:30.411
If you're ever interested in what we do, feel free to reach out to us. We have stickers as well! Thank you for your attention. Now we have time for questions.
00:34:09.033
When you have multiple servers, how do you handle the logs, which are generated by many computers? We use PaperTrail, which effectively consolidates logs into a single interface for easy access, filtering, and monitoring.
00:34:42.900
We also don’t intentionally simulate load on our platform. However, we manage recurring contributions that are scheduled daily. Each day at 4:00 AM, we handle multiple contributions simultaneously, which provides an opportunity to gauge our system's handling capabilities.
00:35:55.490
The sheer volume at this set time mirrors real-life scenarios both in scale and traffic intensity. Thank you very much!