00:00:10.480
A couple of years ago, I joined GitHub as an engineer, and one of my strongest memories of onboarding at the company was when I first cloned our codebase and saw a pretty typical monorepo. However, there was one very unusual aspect: there were over a thousand custom linters inside the codebase.
00:00:23.519
This was unlike anything I'd seen before in my career. There seemed to be a linter for everything you could think of. Honestly, there were linters for things I never thought could be linted.
00:00:37.040
As someone who really liked linters, this was like walking into an alternative universe where all of my dreams had come true. Or so I thought.
00:00:44.239
So, my goal today, first and foremost, is to share that sense of wonder and awe with all of you regarding how GitHub uses linters. A quick introduction: my name is Joel. I live just outside of Boulder, which is actually very close to where we are right now. As a Colorado resident, I'm required to show you a picture of me and my dog on top of a mountain. So here is my lovely golden retriever, Captain, and me on top of the Grand Mesa out on the western slope of Colorado.
00:01:00.239
If you have a little more time while you're in Colorado, I highly recommend taking a trip out there; it's absolutely beautiful. At GitHub, I am an engineer on the Design Infrastructure team. We are a group of designers and engineers that build and maintain Primer, which is our design system, but I won't talk about that today.
00:01:31.680
Instead, let's talk about linters. Today I will discuss how we use linters at GitHub, why we use them, and I’ll provide a significant portion of the talk by giving a plethora of examples of the different kinds of linters we use. I will also share some lessons we've learned along the way.
00:01:51.439
However, let me emphasize a big disclaimer: this is not meant to be a guide on what to do or not to do. What we do at GitHub might not make sense for many other codebases. Think of this presentation as a window into the reality of where we've ended up after many years of building our codebase, and feel free to take from it what you will.
00:02:08.959
With that in mind, let’s start with some context. Our monorepo is now well over 14 years old; in fact, I think it’s actually over 15 years old at this point. We recently crossed our millionth commit in our monorepo, and it is a substantial amount of Ruby. I found a really cool tool called Clock, which you can use to measure the number of lines in our codebase, and we clocked in at two and a half million lines, excluding comments and blank lines.
00:02:32.400
This is a ton of code, and perhaps most importantly, we have over a thousand unique people contributing to that codebase every year. That's massive scale. So this provides a bit of context about my work environment, which should help you understand where I’m coming from when I share some of these examples.
00:02:58.720
Before we get too far along, let’s make sure we’re on the same page about what a linter is. I’m going to start with the Wikipedia definition: a static code analysis tool used to flag programming errors, bugs, stylistic errors, and suspicious constructs. I want to know who authored the last two words; I think they’re a bit cheeky.
00:03:16.319
More simply, the definition I prefer is that a linter is just something that gives you automatic feedback on your code. So, why do we use linters? Our scale, which I just discussed, is a significant factor in why we use linters so extensively. When we have over a thousand engineers pushing so much code, linters enable us to ensure our codebase is upheld to the consistent standards and practices that we care about.
00:03:39.920
However, the primary reason we write linters is to provide high-quality feedback. When I think about feedback, there are many different ways to judge whether it’s good or not, but for the sake of our discussion today, I want to focus on three specific attributes. The first is that good feedback is specific; it’s easy to understand and narrow in its focus. Second, it is timely—feedback is most valuable when it’s given at the right time. Lastly, it is actionable; good feedback allows you to take concrete steps to improve.
00:04:22.560
Let’s dig into some examples from our codebase and evaluate how well they align with these criteria. One way we write linters is what we call 'nudges.' These are essentially precursors to what you would consider a traditional linter, but we use them to provide automatic feedback all the same. We write our nudges using a tool called Sentinel, which we originally built to provide effective automated code reviews on pull requests.
00:04:41.919
You can think of it as a set of regular expressions that, when matched, return a certain message left on a line of code in a pull request. We currently have about 100 of these in our setup. Here’s an example from my colleague, Kate Travers. The rule she added was aimed at preventing the leakage of information in templates.
00:05:06.080
We encountered an issue where people would write HTML comments that disclosed information about a database record we didn’t want sent to customers. Often, people wouldn’t make the connection that the HTML comment would actually be visible to the customer. Thus, we encouraged people to use ERB comments, which are not exposed to customers.
00:05:30.080
The linter is configured using a giant YAML file that resides under version control, where we define a name and title for each of our rules. In this case, we have the HTML comment title, along with a pattern that matches the beginning of an HTML comment. The primary aspect of this rule is really just the comment it leaves on pull requests.
00:05:54.160
This is what it looks like in action—it’s a GitHub bot called Sentinel Reviewer that examines a pull request and posts a comment on the offending line. The interesting thing about these nudges is that we use them in cases where we don’t want to fail the build because we’re not completely confident in them.
00:06:11.120
For example, in the line we’re looking at, this is not a security issue—it's not great that someone looking at our source code will see this line—it’s not particularly clean in my opinion, but it doesn’t expose sensitive information.
00:06:45.120
Another way we use this tool is to trigger pull request reviews. In my team, we own the Stylint linter at GitHub, and we utilize this tool to flag changes that disable that linter on a pull request. Essentially, instead of leaving a message, we can add a request review flag, which selects the GitHub team that should be requested for review on the pull request.
00:07:11.520
What’s really cool is that it functions like a regular expression code owner—rather than having ownership of an entire file, you can specify that your team cares about a particular syntax.
00:07:30.960
So, those are some examples of how we write our nudge-type linters. If we reflect on the criteria for good feedback, how do these stack up? They are specific and target particular problems, but they aren’t necessarily entirely confident—that’s why we’re not blocking the build on them. They also are not especially timely, as they only run once you open a pull request.
00:07:59.680
These nudges are built with a GitHub app, which exists separately from our monorepo, and they depend significantly on writing good messages. If you can draft a great message that clearly states, 'I see you did this thing; here’s exactly how to correct it,' fantastic! But that can vary significantly based on what you’re looking for.
00:08:36.400
Another way we write linters, which I had never seen before coming to GitHub, is by writing tests that function as linters—literally using MiniTest. Some have told me this is something common, but I had not seen it before. These are merely tests that make assertions about the static state of our codebase.
00:09:05.760
Actually, we have hundreds of these; I think it’s well over 300 at this point. Here’s one simple example from my colleague John, who wrote a linter to encourage more inclusive language in our codebase. Like many organizations in our industry, we’ve opted to avoid terms like 'whitelist' and 'blacklist' wherever possible.
00:09:38.880
You can imagine defining a regular expression that can traverse many lines of code to discourage the use of those words. That’s precisely what we did; it’s just a test in our codebase that greps for those regular expressions we want to avoid and asserts that there are no matches.
00:10:02.640
What’s really fantastic about this system is that you essentially write five lines of code using any test framework you want, and it ensures the usage of inclusive language. We don’t have to roll out custom tooling for this. As a side note, we also have similar tools to avoid profanity in our codebase, which at one time was quite common.
00:10:17.200
A more complex example comes from Adam Robin, who discourages the use of the 'html_safe' method. In this case, we utilize the 'assert' operator method and grep the ‘html_safe’ method using a regex, ultimately asserting that the occurrence of this method is less than a defined constant in the file. If it exceeds this threshold, then we display what you might imagine is a helpful error message explaining why we want to avoid this method.
00:10:45.840
This setup functions similarly to what we see with the nudges; it allows us to ensure the correct team is notified to review exceptions to the linter. The file containing that constant has a code owner, which is the team that cares about that specific violation. So whenever a change violates this rule, the individual updates the constant’s integer value, triggering notification to the corresponding team.
00:11:16.320
However, there’s a genuine problem with this approach: these kinds of linters have led to a lot of pain for us. This is one of the real downsides we've noticed from our aggressive use of linters, particularly in high-churn situations. The specific challenges arise when the linter values change frequently, hence leading to conflicts during merges.
00:11:52.560
For example, consider a constant initially valued at 50. If a colleague and I are both collaborating to update this linter together, we may diverge: I remove five cases while my colleague removes ten. When we attempt to merge our changes, conflicts occur at that line, which Git cannot resolve because it’s a consequence of running the linter. Thus, to resolve these conflicts, one must check out a branch and re-run the linter to update the correct value.
00:12:22.720
This process can be especially painful with numerous changes deployed in quick succession—imagine this scenario being repeated with additional team members involved. In discussions with my colleague Eileen, she mentioned that the last thing we want is to complicate the cleanup of linters. The goal of a linter is to discourage poor practices and guide engineers towards acceptable practices that don't result in linter violations.
00:12:47.360
For our high-churn linters, we truly needed a different approach. My colleague Antonio introduced an alternative solution: instead of using counters, we began tracking a constant that listed the files violating the linter.
00:13:04.880
Here’s how this new system looked: we defined a constant in our test file containing a list of template paths, greping for the regular expression that flagged duplicated CSS. We stored that as a variable and simply compared it against an allowed list to identify new violations.
00:13:27.920
The beauty of this approach lies in its enhanced resilience to merge conflicts. With this code structure, adding additional lines to the constant handled merging much more smoothly than reverting to a single line being changed by everyone.
00:13:56.560
So, those are examples of how we use linters written as tests. Reflecting on our criteria again, these linters tend to be specific like nudges, targeting particular violations, but they aren't particularly timely; people generally don’t run them locally and receive feedback after several minutes since they are executed in a separate CI build.
00:14:10.800
They're somewhat actionable, similar to nudges; the effectiveness of the feedback depends on the message content. Nonetheless, we can do better.
00:14:32.640
The last type of linter I’ll discuss are those powered by abstract syntax trees (ASTs). Before we go too far, let me briefly explain what an abstract syntax tree is. It’s a tree representation of the structure of text—in our case, source code.
00:14:50.080
In fact, all of us learned about ASTs when we were in fifth or sixth grade English, diagramming sentences is an example of an AST of the English language. We call these ASTs because 'abstract syntax tree' doesn’t roll off the tongue very easily.
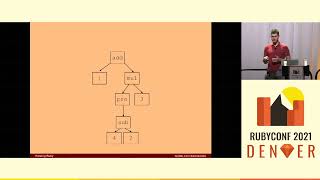
00:15:05.680
As an example, consider this line of Ruby that calls the foo variable or method; parsed as an AST, it appears as a structured tree. This hierarchy enables us to develop linters that reflect the semantics of our code far beyond what would be achievable through the use of regular expressions.
00:15:27.760
An example of an AST-powered linter we use is called ERB Lint. We have developed approximately two dozen of these and just open-sourced a few last week. The example I’m sharing now is from my colleague Kate Higa, an accessibility engineer at GitHub.
00:15:50.800
Here’s an example of an offending case for the linter. This is my first bit of audience interaction: can anyone identify what's wrong with this line of code?
00:16:07.600
The individual in the audience pointed out that it uses redundant wording. Correct! The issue here is that when a screen reader encounters an image on the page, it announces that it’s encountered an image and reads the alt text. This means that including the word 'image' or 'picture' in our image alt attribute is redundant.
00:16:35.440
So, here’s how she wrote the linter for this rule: first, we define a message to return when the linter is violated. In this case, it’s a very helpful message that states that the image alt attribute should not contain 'image' or 'picture' as screen readers already announce the element as an image. We also define a constant listing those words to avoid.
00:17:07.760
Then, in our linter, we define a run method. This run method accepts a tag object, and if the tag isn’t an image, we exit early. We then examine the tag's alt attribute, downcase it, and split it up to check for overlap with the redundant words we defined earlier. If any redundancies are found, we invoke the generate offense method to log a violation.
00:17:35.120
This method is called on every single tag node in that AST I just described. I want to emphasize the ease with which we can access this alt attribute programmatically, avoiding the need to write regular expressions to look for equals signs or quotes. It is much easier to build these linters than to apply regular expressions!
00:18:03.680
What’s great about this linter is that it provides an automatic enforcement of an accessibility rule that I was previously unaware of before encountering this linter. Moreover, because of the informative message, it helps educate developers to consider accessibility in their work, even if we can’t lint for everything that might matter in terms of accessibility.
00:18:40.080
However, our most common AST-powered linters are our custom RuboCop configurations—of which we have about 125. Here’s an example from my colleague Carl. In our codebase, we can check what environment we're running in, like so: we can call GitHub.test or GitHub.production.
00:18:54.320
This can be incredibly problematic, given that if you have code that only runs in production, how can you be certain it actually works until you ship it? That’s inherently risky! So we started by writing a message that says, 'Don’t do this. Do not branch on the GitHub constant.' Your code paths should not differ between test and production environments.
00:19:21.840
Next, we took that offending line and passed it through a Ruby parser, similar to the one we used for ERB ASTs that reveals an AST of our Ruby code. We can then write a magical incantation using node patterns. You can think of these as a hybrid of a regular expression and an SQL query; it’s a specialized syntax meant for traversing abstract syntax trees.
00:19:48.960
I’ll be honest—the technical aspects of this talk substantially increase in complexity. Although I’ve written a number of these linters, I don’t fully grasp it all; I learned that someone finally wrote an understandable guide this summer—it could have been the Evil Martians. But the good news is you don’t have to use these node patterns to write custom RuboCops!
00:20:16.320
Initially, I thought that using this syntax was a requirement; however, I learned that many of our linters do not utilize node patterns, as they can be quite off-putting. So, we’ll rewrite this linter to use plain Ruby instead of the node pattern.
00:20:34.360
We’ll begin by inserting a debugger into an on_if method, which is trigger when RuboCop encounters an if node in any of our Ruby code. This method accepts a node argument, which allows us to inspect that node.
00:20:54.560
By looking closely, you can see that it’s literally just an AST node. However, we discover the node has numerous methods, which provides insight into the types of operations available! Inspecting the condition method reveals the AST of the conditional, where it sends the test message to the GitHub constant. We can traverse even deeper to identify that the receiver’s short name is GitHub—our offending class—and observe that the conditions method name is also an offender.
00:21:29.760
This can lead us back to our linter. Previously, we used node patterns; now, let’s revise this to utilize plain Ruby instead. We will implement an early return unless the short name of the receiver is GitHub, and we will add another early return unless the node’s condition reflects test or production.
00:21:51.840
If we pass both of those checks, we’ll add an offense specifically to the node’s condition. So, this confirms that you indeed can write RuboCops without relying on node patterns. Some might argue that it's not as sophisticated, but I personally prefer code that reads naturally for humans. Node patterns seem written more for computers than for human comprehension.
00:22:15.680
Regarding how these AST linters compare to the other types we’ve covered, they are very specific. They search for particular violations using Ruby’s language parser instead of general-purpose regular expressions. But what about their timeliness? This is where AST linters truly excel.
00:22:40.320
Recalling earlier, we added offenses to the nodes’ conditions. This means that when we receive an error message in our editor, it's only highlighting the 'GitHub.production' usage rather than the whole line! Thus, we can indicate the precise portion of the violation for our linter, which ultimately provides an incredibly short feedback loop.
00:23:07.920
We don’t need to go through CI; we don’t have to wait for a GitHub app to comment on a pull request. This efficiency is what makes linters generally appreciated at the company. Unlike the previous types, where we get a lot of pushback, this integration is user-friendly—it’s hard to complain when it appears directly in your editor!
00:23:32.160
As for the actionability of these linters, the AST linters are perhaps the coolest type I’ll discuss, specifically in how auto-correction functions. For instance, consider this rule regarding writing tests. If we see 'assert_equal nil,' that isn't ideal—what they prefer is for you to define 'assert_nil' instead.
00:23:53.920
To implement auto-correction for this linter, we define an autocorrect method within our linter class. This method accepts a node object, returning a lambda that accepts a corrector object, which responds to the replace method. Let’s discover how these replacements are performed.
00:24:24.000
We’ll refer back to our previous example, where our goal is to change the first line to the latter. So we’ll add a debugger within the autocorrect method and run a test case, allowing us to examine that node closely. If we inspect the arguments of that node, we find that the final argument is 'value.' If we further inspect, we can determine the last node argument.
00:25:01.760
Finally, by calling node.source_range, we acquire a range object from parser—the gem we just explored in the source code. Now, going back to our autocorrect method, it takes in a node and returns a lambda that accepts a corrector. We then call replace on the corrector by passing in the node's source range for the range argument, along with what the new source code should be.
00:25:40.640
We can deduce the new value by referring back to our debugger and stating 'assert_nil' for those last arguments. This is quite an abbreviated implementation; it doesn’t address all edge cases—such as instances where values might be nil.
00:26:10.880
Does anyone have questions on this? Cool! Overall, AST linters can be highly actionable, nearly reaching the point of performing actions themselves via auto-correction.
00:26:29.680
If you want to learn more about them, I hate to break it to you, but the workshop on writing them started half an hour ago, led by Scott Moore. I won’t be offended if anyone leaves right now, since there are many great resources available online.
00:26:40.880
In conclusion, we employ our linters to ensure that our practices are consistently applied through feedback that is specific, timely, and actionable. Most significantly, they offer us the capacity to provide higher-value code reviews.
00:27:06.400
This kind of automation carves out the space we need to concentrate on the more nuanced aspects that humans excel at compared to machines, ultimately elevating our conversations to transcend trivial issues like tabs versus spaces or using the GitHub.production method.
00:27:34.720
The collective impact of reaching a point with a thousand custom linters enhances the quality of engineer-to-engineer discussions at our company. This extends beyond pull requests; when discussing code—even in Slack—the readily understood agreement on how we build things allows us to focus more on valuable contributions for our customers instead of implementation details.
00:28:10.480
I believe this is the real reason we write linters. Every time I leave a comment on a pull request, I now ask myself: 'Do I need to leave this comment, or could this be better enforced by a linter?' I recognize that with around a thousand contributors to our codebase, I might not be the one to review code that may have violated something I commented upon.
00:28:51.760
Even if I allude to that code again, it might happen while I’m on vacation. To be truthful, I don’t reliably believe I could detect the same bug 100% of the time; my hit rate is probably around 75%.
00:29:30.480
As I contemplated writing this talk, it compelled me to critically evaluate the role linters play in the Ruby ecosystem as a whole. I found myself questioning their value after we’d advanced so far in utilizing them at GitHub and considering when this practice comes to an end.
00:30:02.720
This brought to mind the famous saying that 'no code is better than bad code.' It led me to wonder: could the same sentiment apply to linters? Is it possible that no linter could be better than an unmarked issue?
00:30:23.680
Perhaps the most valuable feedback, even when automated, is the feedback that never needed to be provided in the first place. A specific example that drove this thinking home was a linter intended for safety purposes, tracking the 'html_safe' method, which can introduce significant security vulnerabilities if misused.
00:30:44.000
The challenge with using linters for these detections is that Ruby is dynamic; it’s generally not statically typed and not pre-compiled. Yet most of our analysis occurs statically, meaning we’ll inevitably encounter blind spots due to metaprogramming and other Ruby idiosyncrasies.
00:31:05.440
Thus, I find myself pondering how we can create systems that are correct by design rather than relying solely on our linters to confirm compliance. However, I believe that contemplation will be saved for another day. Thank you for your time.
00:31:30.960
I have a minute left for Q&A. Does anyone have questions regarding RuboCop?
00:31:37.200
The question is, for RuboCop and parser, are we using a fork? We are just using the latest version.
00:31:44.159
We extracted some of our custom rules—about a tenth of them into RuboCop GitHub, which also includes our shared configuration. We utilize it across all of our Ruby libraries.
00:32:05.440
Yes, we’re pretty up to date on them. Does anyone else have a question?
00:32:15.360
If I'm going to post my slides? Yes, I’ve sent them to the conference already. They are also available on my website’s public repository.
00:32:28.160
The entire keynote file has also been published, should you wish to view the whole thing.
00:32:43.680
Your question is, do I have a favorite linter? Gosh, I don't know! RuboCop is pretty cool!
00:32:54.720
I think RuboCop is excellent! However, if I think further, I might prefer some work we’re doing on CodeQL, which entails intelligent code analysis.
00:33:04.160
This kind of analysis attempts to project how your program will execute; it’s an area where GitHub is engaged in R&D right now. Sadly, it's early enough that I can't discuss too much about it.
00:33:30.880
It looks like I’ve now exceeded my time; I didn’t realize the blinking red light indicated I was actually two minutes over, not under!
00:33:44.160
Thank you!