00:00:04.880
At RubyKaigi last year, one of my colleagues, Maxime, gave a talk about her work on YJIT, which was a brand new JIT at the time. She has since given another talk this year about it, but in last year's presentation, she mentioned a technique called object shapes and how it might be able to enhance the JIT even further. Additionally, at last year's RubyKaigi, another colleague at Shopify, Chris Seaton, delivered a keynote address titled 'The Future Shape of Ruby Objects.' In his talk, he also discussed object shapes, which Truffle Ruby, a project he works on, uses, and he indicated that it could be beneficial for CRuby as well.
00:00:22.640
When I joined Shopify, I was encouraged by Maxime to pursue the idea of object shapes, resulting in the topic of my talk today: implementing object shapes in CRuby. I made a few updates to this presentation after yesterday because another colleague, Coco Boone, gave a talk titled 'Towards Ruby for JIT,' where he also mentioned object shapes multiple times, reinforcing how beneficial they could be for JITs. Today, we will discuss this project I have been working on to implement object shapes in CRuby, which I have been developing alongside Aaron Patterson.
00:00:57.180
We will answer three main questions: First, we will explore what object shapes are; then we will look at how they are actually implemented, discussing the implementation details; and lastly, we will talk about why MRI should adopt object shapes. So, what exactly are object shapes? You might initially think of geometric shapes like diamonds, triangles, or ovals, but that's not what we are referring to here. When we mention 'object shapes,' we are discussing Ruby objects, like those created with 'Object.new.' The term 'shapes' is metaphorical, representing a technique where each Ruby object has a shape that outlines its properties.
00:01:48.960
You might wonder what an example of an object's property is. For instance, an object's frozen status indicates whether it is frozen or not, and another property could be its instance variables, specifically which instance variables the object possesses. Now, let’s provide some concrete examples of object shapes using actual code. Consider an example class: if we create an instance of this example class, the instance will possess a shape that indicates its properties. The 'circle' here has no relation to actual circles; rather, it signifies that the shape will include the names of instance variables, such as 'a' and 'b.' Additionally, the shape will have a frozen status. If we call 'e.freeze' on this object, its shape will change to a frozen shape. Lastly, each shape also has an ID for unique identification.
00:02:34.920
Now let’s consider another example. Suppose we have a class called 'CompletelyDifferentClass' and we create an instance of it. The instance variables for this shape would be 'c' and 'd,' and it would possess its own unique ID. If we furthermore define a class called 'CoincidentallySameIVars' and create an instance of that class, it will also have instance variables 'c' and 'd.' Interestingly, these two shapes have the same properties—they share the same instance variables and the same frozen status—so they are actually the same shape. This is a crucial point: although these two instances belong to different classes, their shapes are identical.
00:03:30.420
Moreover, it's important to note that an object's shape can transition to accommodate new properties. Essentially, the shape of an object changes whenever a new property is added. Each object starts at the root shape, represented by an empty shape with ID 0 and no instance variables. As we create an object of the example class with 'e = ExampleClass.new' and execute the initialize method, its shape will transition. The first time we set instance variable 'a,' the shape will transition through an edge with 'a' leading to a new shape that only contains 'a' and a newly assigned ID. Adding instance variable 'b' will cause another transition to a new shape containing both 'a' and 'b,' along with the subsequent ID.
00:04:18.300
Let’s say instead of setting both 'a' and 'b' within the initialize method, we have the initialize method only set 'a' and another descriptive method that assigns 'b.' In this case, if we have 'e' as the previously described instance and a second instance 'e2' of the same class and we call 'e2.set_b,' 'e2' will have the last shape because it possesses both instance variables 'a' and 'b,' while 'e' will have the intermediate shape, retaining only instance variable 'a.' This is another critical point: while both instances are of the same class, they have different shapes.
00:05:10.560
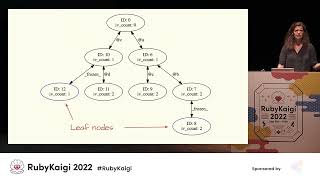
Returning to our earlier example, suppose we have a different class defined with two instance variables 'a' and 'c.' The transitions will be similar to the example class but not identical. For this instance 's,' it will initially start at the root shape. When we first set 'a,' it will transition as before, and subsequently, since there is no existing transition for 'c,' it will create a new shape for 'a' and 'c' with a new ID. You may have noticed that the shapes form a tree structure. If we were to execute all the snippets of code we've compiled so far in Ruby and generate the shape tree, it would look something like this, and we'll delve deeper into details as we progress.
00:06:03.420
We previously mentioned that an object's shape transitions with new properties and one of those properties is its frozen status. Let’s examine how it transitions with the frozen status. If we have a class where we only set 'a', the object will start at the root shape and transition to an id 1 shape that has instance variable 'a.' However, if we then call 'a.freeze,' it will create another transition, not through an instance variable, but rather through the frozen status, resulting in a new shape where 'a' is maintained, but 'frozen' is true. We can also transition with other properties, which we will discuss further, but currently, we’ll focus on instance variables and the frozen property.
00:07:20.460
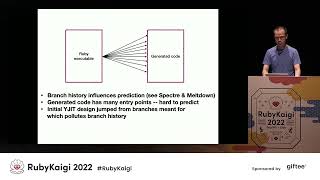
Now that we have clarified what object shapes are, let’s discuss our implementation. At its core, we have the 'RB shape' struct that occupies 40 bytes, which fits perfectly into an R value—a crucial detail we’ll revisit shortly. Within this RB shape struct, we maintain flags, which include the shape's ID. Referring back to our shape tree, we see various shape IDs, with shape ID 0 for the root and shape ID 10 for others. On 64-bit machines, we utilize 32 flag bits for shape IDs, allowing for 4.2 billion potential shapes, while on 32-bit machines, we use 16 flag bits, accommodating 65,000 potential shapes. Just to put these figures into context, on Rails Bench, we max at about 10,000 shapes, and during Shopify's monolith test suite, we observed around 40,000 shapes—occasionally even 32 bits will suffice for plenty of shapes.
00:08:39.240
We also encode the frozen status within the flags. The shapes that are highlighted in blue throughout our shape tree represent frozen shapes. As we know, these signify that they have undergone frozen transitions. It's notable that all frozen shapes are leaf nodes because once a shape becomes frozen, it cannot have additional instance variables added—resulting in no further transitions. Moreover, we maintain a pointer to the parent shape, establishing a link upwards in the tree, which is important for traversing the shapes. Along with this, we have an ID table from instance variables to the next shapes, allowing us to see, as previously mentioned, whether a transition already has an associated shape provisioned.
00:09:42.300
Moreover, the edge name facilitates the transition from a parent shape to its offspring, with, for example, edge 'B' transitioning from a shape with ID 6 to one with ID 7. Lastly, we have the IV count, denoting the number of instance variables present in a shape. Here, you can observe the IV count being 1 for this frozen shape and 2 for the other. We allocate our shape list within the VM, creating shapes, and as they are generated, we populate them in the VM. The average memory increase from this practice is around 500 kilobytes, which is less than 1% memory increase for an empty Ruby script. In larger Ruby applications, this translates to even less than 1% increase.
00:10:37.320
Also, we perform garbage collection on shapes to conserve memory; any shapes not actively in use will be collected, thus allowing us to reuse shape IDs. When shapes are collected, they mark their parents to signify their presence during the marking phase of garbage collection. Now, let us move on to a crucial aspect of our discussion: why should MRI adopt object shapes? There are four main areas we will cover: first, increased cache hits; second, decreased code complexity; third, the benefits to JITs, highlighted by both Coco Boone and Maxime; and finally, performance advantages that shapes can offer.
00:11:19.589
To begin with increased cache hits, we have altered how caching operates on instance variable reads and writes with shapes. However, to understand this change, we first need to review how caching functions today. Taking our example class and instantiating an object, the instance variables are stored in an array. You may wonder which indexes these values reside in. Currently, Ruby maintains a map of instance variable names to their array indexes per class. When we need to set an instance variable, we look for its corresponding entry in this map; if it's absent, we insert it at the next available index and assign the appropriate value to that index.
00:12:02.520
However, hash lookups are not particularly efficient and can become costly. Therefore, Ruby caches the instance variable index lookup using the class as the cache key. When setting an instance variable, we cache the index for that instance variable within the corresponding class. While this mechanism works well under many circumstances, it fails when dealing with subclassing. For instance, if we create an 'Inherited' class that merely inherits from the example class without any altering content, it will lead to a cache miss, resulting in unnecessary computation again to establish the new index, despite running identical initialization methods.
00:13:05.460
With the introduction of object shapes, this caching mechanism changes. Firstly, we eliminate the existence of an instance variable names map for the example class or any other class, aside from one index at 0. Instead, we compute the index as the IV count minus one. Furthermore, instead of utilizing the class as the cache key, we make use of the shape ID. To illustrate this, when setting an instance variable, if we begin with shape 0—our root shape—transitioning yields a new shape from a through shape ID 6, leading to an IV count of 1 and determining that index will therefore be 0. When we move to 'B,' we begin at shape ID 6, transitioning through the instance variable 'b' towards shape ID 7, turning our IV count to 2, hence making it index 1.
00:13:54.240
If we then refer to the inherited class, it will have the same shape transitions since the cache is no longer dependent on the class, which ensures cache hits in this case. Moving on, we can discuss how object shapes lead to decreased code complexity. An example here is removing the entire instance variable index name map. Chris Seaton highlighted the essential questions that Ruby masters must contend with when setting instance variables. These include: Is the object frozen? What is its type and class? Does the class match? Among others. Notably, object shapes necessitate fewer checks compared to this schema. We can illustrate this by focusing on the question of whether the object is frozen and how it changes on the fast path with object shapes.
00:15:50.760
Before we had object shapes, the process for setting an instance variable would include raising a frozen error if the object is found to be frozen, which is mandatory since an instance variable cannot be assigned to a frozen object. Following this, we would check the cache, determining if it was a cache hit or miss, which could involve an expensive computation if it turned out to be a miss, as previously outlined. After establishing the new index, we would conveniently set the instance variable.
00:16:15.999
With object shapes, however, the cache check has been optimized significantly; instead of relying on the class, we utilize the shape IDs which allows us to reduce the complexity of these lookups while examining the shape tree. Consequently, we can ascertain the index efficiently by simply traversing and checking the IV count minus one. Notably, the frozen status encoding within the shape ID means we only need to check the frozen state during the slower path because if an object with the same shape has already set an instance variable, we can determine it isn’t frozen.
00:17:23.059
The benefit to JITs regarding object shapes leads to decreased checks within the code; specifically, this eliminates the necessity for three separate checks. With object shapes, we also see that accessing memory becomes more efficient. In contrast to the previous requirements for additional checks for embedded and type distinctions, object shapes allow for their assessment in one streamlined comparison in compiled JIT code—enhancing performance metrics overall. Now let’s examine the assembly code generated by YJIT.
00:18:08.569
First, looking at instance variable retrieval without object shapes, we notice more extensive instructions with more checks necessary to verify types and embeddings. However, with object shapes incorporated, we witness fewer total instructions, specifically two less. Additionally, previously, we would have required three distinct checks, which are inherently costly. We can mitigate this with our new approach where we detect shape, embedding, and type all at once, reducing the number of expensive memory reads—significantly enhancing efficiency in both instructions and comparisons. This concept rests on the premise that memory reads are noticeably more expensive than register accesses, being approximately two orders of magnitude costlier.
00:19:53.340
Thus, with object shapes, we reduce the assembly code-generating overhead, yielding fewer instructions, comparisons, and memory reads. Addressing performance metrics, we can delve into micro benchmarks reflecting object shapes in contrast to the master branch. Here, any value greater than one signifies that shapes perform faster. Within the tests, there's minimal variance as observed; specifically, the benchmarks indicate that shapes performed either similarly or faster in three scenarios, with notable cases demonstrating more than twice the speed performance improvement in specific sub-benchmarks, resulting from enhanced cache hits rather than misses.
00:21:03.569
In addition, exploring the Rails bench results, we can see how higher figures indicate better requests per second. The analysis over ten rounds revealed that the shapes branch operates about two percent faster, indicating tangible performance gains attributable to shapes. Moving forward, what is the current status and next steps for the project? A few months back, we raised an issue when we commenced work on this pivotal project, and I am pleased to mention that we now feel the implementation is robust enough to merge. I will provide an update upon my return from this trip with the latest statistics and insights discussed.
00:22:02.590
If you wish to continue following the development of this topic, you can refer to the linked Redmine issue for more detailed tracking of our progress. Thank you so much for having me at RubyKaigi and for your attention during this presentation.