00:00:11.040
Hello and welcome to our talk on Just-in-Time Compiling Ruby Regexps on TruffleRuby. I'm Benoit Daloze, and I'm leading the Truffle project. Here is Josef Haider, who is the T-Rex creator and maintainer. We are both part of the GraalVM team at Oracle Labs.
00:00:22.880
If you do not know TruffleRuby yet, it's a high-performance Ruby implementation that utilizes the GraalVM JIT compiler, which gives it great performance. It targets full compatibility with Ruby 2.7 for the current release and Ruby 3.0 for the next one. It also includes support for C extensions, so the idea is that it would be a drop-in replacement for CRuby but faster. You can find more information on GitHub, Twitter, and our website.
00:00:54.480
Let's start with some background on regex engines. Initially, Ruby used an array extension called Onigmo, which is a fork of Oniguruma. These two regex engines are backtracking regex engines, and what is special about them is they support many encodings—about 30—while most regex engines only support one or two encodings. This means that almost all of the Ruby encodings are directly supported, so there is no need to transcode the regular expression or the string when matching.
00:01:38.560
TruffleRuby initially used Joni, which is a port of Oniguruma to Java by JRuby developers. It essentially has the same performance, meaning it uses basically the same code, just translated from C to Java. However, TruffleRuby wants to optimize all aspects of Ruby, including small languages such as array pack and string formatting, which TruffleRuby already compiles and handles very well.
00:01:46.479
However, for regular expressions, we have not yet achieved that optimization because we were still using Joni. You cannot just-in-time compile Joni in a meaningful way. It operates with very generic logic, utilizing backtracking—a solution that does not naturally align well with JIT compilation.
00:02:10.880
Thus, what we needed was a new regular expression engine for TruffleRuby that can efficiently compile regex patterns and optimize them effectively. This need led us to adopt T-Rex, an engine designed specifically for this task. With that, I will hand it over to Josef to present T-Rex.
00:02:26.239
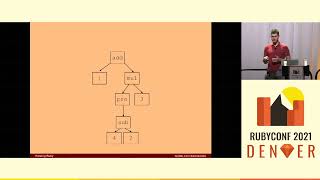
Thank you, Benoit. T-Rex is a regular expression engine implemented as a Truffle language and is based on deterministic finite automata, also known as finite state machines. For anyone who is not familiar with state machines, they are essentially a mathematical construct designed to match a set of strings.
00:02:46.720
Such a finite state machine consists of a set of states connected by transitions. Each transition has a set of accepted symbols, and to match a string, one must traverse the finite state machine from the initial state to a final state. In the exemplary state machine on the slide, we have two states: State One, which is the initial state indicated by the start arrow, and State Two, indicated by the double circle as the final state. They are connected by a single transition accepting a single symbol.
00:03:24.000
Regular expressions have evolved significantly and now include features that were previously not present in finite state machines. Therefore, modern regex dialects cannot easily map the complete feature set to finite state machines anymore. Fortunately, the core features still exist and can be efficiently mapped.
00:03:57.760
I will quickly go through the essential features of regular expressions and how they can be mapped to finite state machines. The simplest and most basic are concatenations of successive terms, which translate to chaining states corresponding to separate terms together using transitions. Disjunctions of multiple terms can be mapped to a finite state machine by introducing additional transitions from the preceding state to each beginning state of every branch of the disjunction.
00:04:46.240
In the example on this slide, you can see a direct mapping of the regular expression 'ab' or 'ac' to a state machine. This state machine is non-deterministic because the first state has two transitions accepting the same symbol 'a'. This can't be reasonably executed by the regex matcher, so we must transform the non-deterministic state machine into a deterministic one. T-Rex performs this transformation through a power set construction applicable to any non-deterministic finite automaton, but it can sometimes introduce an exponential number of additional states.
00:05:57.760
Thus, if the number of states exceeds the compiler’s capability to manage, T-Rex will bail out from this power set construction and revert to an indirect matching mode, which creates deterministic states on the fly. While this slower method still maintains linear runtime complexity, it's advisable for performance reasons to leverage the direct method whenever possible. Infinite quantifiers can create infinite loops in regular expressions, and these can simply be represented by adding transitions that form loops in the state machine.
00:07:01.600
Interestingly, for all finite state machine-based regex engines, it is often better to use infinite loops than bounded loops because they can be mapped to a state machine much more easily. The first feature that requires extending the finite state machine model is capture group tracking. T-Rex tracks capture groups through an annotation process that marks all transitions with the capture group boundaries traversed during the matching process.
00:08:03.120
This method incurs overhead proportional to the number of states in the state machine, but it is still less than the exponential overhead found in backtracking engines. Since we cannot delve into all the implementation details of T-Rex, let's quickly discuss a list of supported and unsupported features to provide an idea of T-Rex's capabilities. We have already covered concatenation, disjunction, infinite quantifiers, and capture groups.
00:09:35.520
Character classes are directly supported since they simply map to the accepted symbol sets of individual transitions. Counted quantifiers are partially supported—these represent a counted loop, and T-Rex handles them by unrolling the loop, which results in a number of states proportional to the maximum count specified in the quantifier.
00:09:42.640
We plan to support arbitrary counted quantifiers with actual counting variables in the background in the future, though this feature is currently not implemented. Anchors, including backslash 'a' and 'c', are supported without overhead as they simply add initial and final states. Word boundaries are replaced with equivalent expressions utilizing look-around assertions.
00:09:50.560
Similarly, caret and dollar look-around assertions are fully supported—as are look-ahead assertions, which get merged into the parent expression's automata. Look-behind assertions are partially supported too; T-Rex currently supports look-behind expressions that consist of a single sequence of either literal characters or character classes.
00:11:02.720
Currently, back-references remain unsupported due to their complexity in matching with an automaton. Though we may develop a solution for this in the future, we are not overly optimistic. However, it’s important to note that this does not hinder TruffleRuby's implementation. For example, negative look-arounds are currently also unsupported, and we may add support for that in the future as the implementation is more complex than positive look-arounds.
00:11:13.040
Recursive sub-expression calls will probably never be supported in T-Rex, simply because it is nearly impossible to perfectly mimic backtracking behavior. Other unsupported features include possessive quantifiers, and although we may be able to replicate their semantics in the future, it is likely not worthwhile since possessive quantifiers are usually only used to address catastrophic backtracking behavior in backtracking engines.
00:11:32.720
Conditionals and absent expressions have also not yet been addressed. Now, moving on to the crucial part—how do we just-in-time compile actual regular expressions represented as deterministic finite automata? Typically, when you want to match a regular expression using a deterministic automaton, you would have a loop that always loads the current state and the current character.
00:12:27.840
Next, you would go through the current state’s transitions and check if any transition matches the current character. Upon finding a matching transition, you would then load that transition's target state and continue the loop. To avoid this indirection, we instruct the Graal compiler to compile a separate copy of the loop body for each state in the state machine.
00:12:46.560
On the next slide, you can see an example where we compile a state machine for the regular expression 'a+' followed by either 'b' or 'c'. This state machine is quite simple, consisting only of three states. Following each state label, you can observe the copied loop body that will be included in the compiled code for this particular regular expression.
00:13:29.680
For State 0, the compiler will emit a boundary check for the input string, then a character load or byte load depending on the encoding used. Subsequently, it emits an if-else cascade for every transition, meaning that if the first condition is met, we simply jump to the target state. This process repeats for State 1.
00:13:47.840
Since State 2 has no outgoing transitions, the if-else cascade is removed, leading us only to the return statement. This pseudocode can effectively be compiled by Graal to nearly one-to-one real assembly code, allowing it to be inlined wherever this regular expression matcher is called.
00:14:01.200
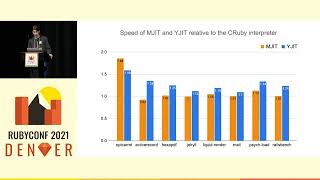
Now let's take a look at performance. We utilize the benchmark IPS gem to measure peak performance after warm-up, meaning we measure performance once the relevant methods have been JIT compiled. We compare three implementations: TruffleRuby with T-Rex, TruffleRuby with Joni, and CRuby 2.7 as a baseline.
00:14:48.320
We begin with some microbenchmarks, which are very simple. Here we match the string 'abc' against several regular expressions, which you can see below the graph. We have five regex patterns, two of which do not match the string, while the three in the middle do. Notably, CRuby 2.7 is the baseline, with Joni showing similar performance.
00:15:15.760
However, T-Rex achieves a performance enhancement of 25 times to 40 times faster, representing a significant speedup due to three main reasons: firstly, T-Rex uses a state machine regex engine rather than backtracking; secondly, T-Rex just-in-time compiles the regex; and thirdly, it also compiles the Ruby code, optimizing them together.
00:16:03.680
This compilation process starts with the matching goal, then integrates with the Ruby methods involved—all of which are inlined and optimized by the Graal compiler into machine code. In the case of a backtracking engine, the logic is more generic, but here we are comparing it specifically to the given regex, yielding faster results.
00:17:00.800
In our larger regex benchmarks, we begin with the Liquid parser, a component of the Liquid template language that heavily utilizes regex. Performance is critical when parsing Liquid templates due to the volume of templates available, as caching isn't always feasible. Notably, the Liquid template is parsed to an AST instead of directly transforming into Ruby code for safety.
00:18:49.760
The second benchmark tests a Browser Sniffer gem used to detect browser types, operating systems, and versions based on user agent strings. For the third benchmark, we use Regex Redux, a classic benchmark analyzing 50 megabytes of DNA and RNA sequences through regular expressions without IO operations.
00:19:01.120
Finally, we have the Syslog benchmark, which tests a log line in accordance with the BSD Syslog protocol and RFC standards. The results indicate great success: we see that T-Rex is 2.3 times faster on the Browser Sniffer, 9 times faster on Syslog, and even better performance on Liquid parsing when integrating both Ruby logic and regex.
00:20:18.480
Transitioning to a different subject, let’s discuss Redos—regular expression denial of service attacks—which have surfaced in Rails security reports this year. It's not an uncommon issue, with half of the recent issues found being Redos related, illustrating its frequent occurrence.
00:20:36.600
The advantage of T-Rex is that it is not susceptible to Redos. The reason is that T-Rex always matches in linear time, eliminating the potential for catastrophic backtracking that leads to severe slowdowns.
00:20:59.040
The problem arises when there’s a malicious input string and the regex pattern is poorly designed, leading to excessive backtracking. In backtracking engines, this can deteriorate to an exponential run time, but that concern does not exist in T-Rex.
00:21:53.200
On the flip side, not all features of Ruby regex can be supported by T-Rex. For regex patterns incompatible with it, TruffleRuby falls back to using Joni or traditional backtracking. This fallback mechanism also issues warnings to developers so that they are aware of potential performance issues.
00:22:52.160
Additionally, I want to discuss atomic groups, commonly added to address Redos. Their primary use is to reduce excessive backtracking, but they can present challenges. Expressing these in finite state machines is not straightforward.
00:23:10.640
Atomic groups do not cause excessive backtracking in T-Rex, which handles matching linearly; therefore, we can generally ignore them. However, if they are used for semantics, this might be more problematic.
00:23:35.680
In conclusion, we have demonstrated that using finite state machines for regex matching is substantially faster and safer than backtracking. TruffleRuby and T-Rex can effectively just-in-time compile Ruby regex patterns to machine code, optimizing both Ruby logic and the specific state machine for those regex patterns.
00:23:59.680
We have witnessed performance boosts ranging from 24 to 41 times on microbenchmarks and 2.3 to 9 times on larger regex benchmarks. Finally, we confirmed that TruffleRuby mitigates the risk of catastrophic backtracking, enhancing developer safety.
00:24:04.400
I would like to thank Jerko, who supported the integration of many Ruby regex features into T-Rex; Duncan, for his optimizations related to regex matching; and Kevin Maynard, for enhancing the regex logic in TruffleRuby.
00:24:20.560
Thank you for listening to our talk. If you have any questions, feel free to ask us on GitHub discussions, Slack, Twitter, or wherever you prefer. We are happy to answer them.