00:00:00.320
Hello and welcome to our talk on Just-in-Time Compiling Ruby Regexs on TruffleRuby. I'm Benoit Daloze, and I'm leading the TruffleRuby implementation. We also have Josef Haider, the Truffle Regex creator and maintainer. We're both part of the GraalVM team at Oracle Labs.
00:00:06.000
If you don't know TruffleRuby yet, it's a high-performance Ruby implementation. It utilizes the GraalVM JIT compiler, which significantly enhances performance. TruffleRuby targets full compatibility with Ruby 2.7, including extensions, meaning you can run your applications on TruffleRuby without any changes. It's open-source and available on GitHub, and I also have a Twitter account, along with a newly launched website.
00:00:31.439
Today, we're discussing regular expressions. Regular expressions are executed by a regex engine—in our case, TruffleRuby uses Onigmo, which is a fork of Oniguruma. These engines are backtracking regular expression engines. What makes Onigmo unique is its support for 30 encodings, which is quite impressive, considering most regex engines only support one or two. TruffleRuby initially used Joni, which is essentially a Java port of Onigmo created by the JRuby developers.
00:01:00.239
While Joni provides similar performance to Onigmo, the convenience of Onigmo in terms of compatibility is a distinct advantage. Our goal is to enhance the performance of regular expressions in TruffleRuby, as we've made optimizations across various areas in Ruby, including language features as well as smaller language particulars like Array#pack or string formatting. We can apply just-in-time compilation and special handling for these specific cases, avoiding generic routines to significantly increase the speed of execution. Although we've implemented a few such optimizations for some languages, we had yet to improve on regular expressions.
00:02:05.600
We cannot use Joni for better performance because it is fundamentally a backtracking engine that supports all regular expressions, rather than specializing in any particular case. It interprets each part of the regex sequentially, whereas we aim to develop something vastly superior. To accomplish this, we've created a new regular expression engine called T-regex, developed by Josef Haider and his team. I’ll now pass the presentation over to him.
00:02:28.240
Thank you. As already mentioned, T-regex is a distinct regex engine designed to work with the Truffle framework. It's based on finite state machines, particularly deterministic finite automata. For anyone who may not remember, state machines are mathematical constructs that consist of states connected by transitions, with each transition possessing a set of accepted symbols or characters. In the illustration, we visualize an automaton consisting of two states—state one serves as the initial state, while state two is the final state, identified by the double circle. The transition between these states accepts a single character.
00:03:08.560
Regular expressions were historically easy to map onto finite state machines when they had fewer features. However, with the introduction of additional features by languages like Perl, that is no longer the case. Fortunately, simpler concepts still exist and can be easily mapped to finite state machines. We can start with the simplest case, which is concatenation; to have a state machine match a sequence of terms, we could chain their states together. The next aspect, disjunction, is slightly more complex; the state machine model reflects a simple two-branch disjunction by adding separate transitions for each branch leading from the initial state.
00:03:54.960
In this non-deterministic automaton, the multiple transitions from one state can match the same character, which complicates how the actual regex is matched. Therefore, T-regex must transform such non-deterministic finite automata into deterministic automata by employing powerset construction. In the illustration, we see the transformation process where the number of states can decrease but can also introduce an exponential number of new states. If the conversion generates too many states, T-regex will revert to utilizing Onigmo for matching in Ruby’s case.
00:05:07.520
Next, we’ll address additional features supported by T-regex, including infinite or unbounded quantifiers, which can be easily mapped to automata since they simply add back edges or transitions that loop back to a single state or a common subcomponent. The first feature that necessitates an addition to the classical state machine model is capture group tracking. T-regex models this aspect by enhancing every transition with annotations to indicate whether it enters or exits a capture group.
00:06:00.320
For a more complex expression, traversing the automaton allows us to record the current character index at each transition entering or exiting a capture group. While this approach can incur overhead, particularly in complex cases, it retains a performance advantage over backtracking engines, as it does not scale proportionally to the input string length. Since we cannot cover all the implementation details of the regex here, we'll simply list the supported features: we have already discussed concatenation, disjunction, infinite quantifiers, and capture groups; character classes translate easily to the accepted symbol set of a single transition.
00:06:31.680
Counted quantifiers are partially supported in T-regex. We unroll the counted loop—if you have a counted quantifier requiring one to four iterations, for example, four additional states are generated in the state machine for each possible iteration. Currently, this functionality works effectively for low iteration counts. Although support for arbitrary counts is planned, it is not yet implemented. Anchors are also supported, as they simply translate to the backslash-a and backslash-c anchors, effectively adding new initial or final states without introducing overhead to the regex matcher.
00:07:51.840
Expressions like caret and dollar, as well as backslash-b and capital-b, are substituted with equivalent expressions that employ lookaround assertions. Both lookahead and lookbehind assertions are supported, but the latter are limited to single sequences of character classes or literal characters. Unsupported features, however, include backreferences, recursive sub-expression calls, and negative lookaround assertions, as backreferences are difficult to map to an automaton—though it may be possible, we have yet to explore this fully.
00:08:34.880
Capturing group references in replacement strings, such as in gsub, are supported because they are not directly tied to the regex engine. As for negative lookaround assertions, support might be introduced in the future but is currently absent. Sub-expression calls likely will not be integrated into the engine due to their complexity and the difficulty of mapping them to an automaton. Support for possessive quantifiers and atomic groups is limited but may be addressed in future releases. At this time, we can ignore atomic groups and possessive quantifiers without impacting performance.
00:09:41.920
Now, let's address how we can just-in-time compile a regular expression matcher. Normally, executing a state machine-based regex matcher involves a loop similar to the one depicted earlier. In each iteration, you'd load the current state from a list and the current character from the input string, followed by an optional bounds check. With the current character, the transitions of the state are matched, advancing the state if a transition is successful, until all transitions are exhausted.
00:10:21.360
This standard approach can prove inefficient for T-regex. Instead, we instruct the Graal compiler to compile a distinct loop body for each state. Thus, you have a separate loop body for state 0, a different one for state 1, and so forth, enabling the compiler to generate compiled matches tailored to each transition in the state machine. The result is a substantial performance gain, as shown in the subsequent slides with various regex matchers.
00:11:07.520
In this particular example, we match the expression 'a+' followed by either 'b' or 'c'. The entire state machine constructed is straightforward, consisting of three states. For state 0, the compiled loop initializes by loading the current character and incrementing the index. Each loop iteration is solely responsible for processing one character sequentially, meaning we do not backtrack but continue linearly through the input. Following the loading, we execute an if-else cascade matching every transition of the current state, eventually leading us to a return statement upon reaching the final state, which includes no further transitions.
00:12:20.560
This code is effectively compilable to actual assembly and can even be inlined into any function that calls T-regex. I will now hand it back over to Benoit for some performance results.
00:13:01.760
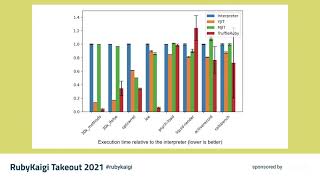
Thanks! Next, we're going to present some performance results. We’ll use the Benchmark IPS gem to measure peak performance, specifically focusing on time taken after just-in-time compilation. We'll compare three implementations: TruffleRuby, JRuby, and CRuby 2.7. We begin with some basic microbenchmarks to observe regex matching speed across different regex patterns matching the string 'abc'. The first and last patterns do not match, while the middle ones do. The results indicate that TruffleRuby provides a speedup of 25 to 40 times relative to CRuby—an exceptional enhancement in performance.
00:14:58.560
This speedup is attributed to multiple factors. The first is that T-regex employs a finite state machine architecture rather than a backtracking engine, enabling it to process input strings in linear time without excessive repetitive checks. The second key factor is that T-regex compiles the state machine to machine code, which considerably boosts matching operations as opposed to traditional backtracking that evaluates every part of a pattern. T-regex generates optimized compiled versions tailored for specific regular expressions, enhancing efficiency significantly.
00:16:22.720
Lastly, since both T-regex and TruffleRuby are Truffle languages operating in the same process, the Graal compiler can optimize both languages together, facilitating powerful inlining across the two. The Ruby logic surrounding regex operations, such as match scoring and related checks, is compiled alongside the regular expression logic in T-regex, yielding extraordinary speed improvements across the board.
00:17:37.760
We've also tested performance on larger regex benchmarks, demonstrating remarkable speed increases ranging from 2.3x to 9x faster than existing implementations like JRuby. For instance, we evaluated the Liquid gem, used commonly by Shopify for templating, and observed that regex parsing is executed more rapidly than traditional Ruby regex engines.
00:18:01.920
The Browser Sniffer gem, which detects browser types and versions using user-agent strings, also benefited from T-regex optimizations. The Regex Redux benchmark illustrates a performance gain from 2x to 3x when utilizing the T-regex implementation over JRuby, emphasizing that while Joni offers some improvements, T-regex outperforms it considerably regarding regex-heavy workloads, highlighting T-regex’s advantages in real-world scenarios.
00:19:35.920
Moving on, let's discuss security vulnerabilities. A common security issue associated with regex engines is ReDoS (Regular Expression Denial of Service). Backtracking engines, like Onigmo or Joni, may evaluate the same input character multiple times, leading to scenarios of catastrophic backtracking. The regex can take an exorbitant amount of time to match certain inputs, resulting in denial of service for applications facing such regexes. T-regex rectifies this issue by guaranteeing linear matching for regex operations, advancing through input without backtracking.
00:21:11.760
Since its 2021 release, T-regex has faced three identified ReDoS vulnerabilities, with a significant number of reported issues from Rails security reports involving regex problems. T-regex is immune to ReDoS, achieving linear-time complexity in regex matching. If a regex expression is not supported by T-regex because of its features, the engine can fall back to Joni, ensuring that you are warned if a regex requires backtracking.
00:21:57.920
I also want to touch on atomic groups. Although atomic groups cannot be easily supported by a finite state machine like T-regex, they are often utilized as a safeguard against excessive backtracking. The primary design of T-regex negates the necessity for atomic groups, as it resolves the very backtracking problems they are meant to address. However, their usage in applications for semantics might still warrant consideration; we will explore this topic with examples further during open-source gem validations to identify any improper usages of atomic groups.
00:23:42.560
In conclusion, we have established that finite state machines for regex matching provide substantial performance benefits over traditional backtracking engines like Onigmo or Joni. T-regex and TruffleRuby allow for the compilation of Ruby regular expressions into machine code, which is a groundbreaking contribution to Ruby's ecosystem. Moreover, we can inline Ruby logic alongside regex logic, yielding speedups of up to 41 times in microbenchmarks. Even across larger benchmarks, performance improvements of 2.3x to 9x have been observed. The advancements these optimizations offer not only enhance Ruby's capabilities but also facilitate a safety net against ReDoS vulnerabilities.
00:24:51.040
I would like to take a moment to acknowledge some individuals who significantly contributed to this work, including Kiera from the T-regex team, who integrated the Ruby flavor of regular expressions directly into T-regex, ensuring compatibility with multiple encodings. I also want to thank Duncan from the TruffleRuby team, who made numerous optimizations related to regex matching, and Kevin Minner at Shopify for enabling further splitting and inlining of regexes in TruffleRuby, contributing to our performance gains.
00:25:46.720
With that, I sincerely thank you for your attention, and if you have any questions, please feel free to reach out to us on the TruffleRuby GitHub discussions, Slack, Twitter, or any platform that suits you. We are more than happy to answer your queries and engage in discussions surrounding this exciting advancement. Thank you!