00:00:11
Hey there!
00:00:14
I'm Micah. I write a lot of Ruby for my day job at Heroku.
00:00:19
I'm also interested in distributed systems.
00:00:24
The genesis of this talk is that some co-workers and I spent time studying Raft last year. I thought it would be fun to attempt writing a simple implementation. I've also been meaning to spend some time with Ractor, and it all sort of came together into this talk.
00:00:41
We'll start with a little background on Ractor and Raft.
00:00:47
Ractor is designed to provide parallel execution features in Ruby without thread-safety concerns. This comes from the official README. It's new and still experimental as of Ruby 3.0.0. It was developed by Koichi Sasada, who is also responsible for YARV, the Ruby VM introduced in Ruby 1.9.
00:01:00
I initially started this exercise using threads and set it aside in frustration due to Ruby's threading problems. When I picked it up again using Ractor, everything fell into place beautifully.
00:01:18
Historically, a Ruby program has one or more processes, and within those processes are one or more threads. The processes share almost nothing, while the threads share almost everything. Now, with Ractor, which is a mix between a process and a thread, they share almost nothing but are part of the same process and memory space, allowing for communication.
00:01:42
When you run your Ruby program, it runs in what's called the main Ractor. This is special in several ways; for instance, it's the only Ractor that can access global variables.
00:02:01
Ractor is beneficial for a couple of major reasons. Historically, in mainline Ruby, only one piece of Ruby code could run at once, meaning you could have other threads waiting on I/O and a few other operations, but only one bit of Ruby was executing at once, managed by the Global Interpreter Lock, which made scaling performance within a process challenging.
00:02:15
Ractor addresses this by providing one lock per Ractor, making it easier to scale. The other reason it's beneficial is that it simplifies writing multithreaded code safely.
00:02:51
In short, each Ractor has a single way to input data and a single way to output data. We strictly keep track of which Ractor has authority to access certain objects at any given time, ensuring that two Ractors will never modify the same piece of data concurrently.
00:03:06
This approach, known as the actor model, is similar to techniques used in various programming languages and frameworks, with Erlang being particularly notable. When a Ractor receives an object in its inbox, it can either be a shareable type (an immutable object like a frozen string or number), a class or module, or a reference to another Ractor.
00:03:40
If you need to pass more complex objects, it’s either a copy of the object or ownership has been transferred. Now, regarding Raft, the paper describing it outlines it as a consensus algorithm for managing a replicated log. It is designed for a group of servers that trust each other but may not always be able to communicate.
00:04:18
Raft ensures that even if half of the nodes go down, the system can still retain data and process requests by having them elect a leader that makes sure all nodes have the same data.
00:04:41
That data is stored in what is referred to as a log, which is essentially an append-only list. There's a great deal of functionality you can build on top of that. For example, if you keep track of SQL commands sent to a server, replaying those against another server would yield the same data.
00:05:08
Raft's primary goal is understandability. Crafting comprehensible systems where computers interact can be quite challenging, and Raft attempts to simplify that by having clearly defined states for each node.
00:05:43
In a Raft cluster, only the leader node can accept writes and manage an append-only log. Everything else built on top of it must be constructed by the developer.
00:06:03
The Raft paper is approximately 18 pages long, straightforward to read, and covers almost everything needed for implementation.
00:06:36
Other algorithms, such as Paxos and its derivatives, are notoriously complex, while tools like Zookeeper and Pacemaker utilize their own protocols to solve similar problems.
00:06:46
Now, onto what we are doing today: we are building a Raft cluster inside one Ruby process using Ractor. In real-world scenarios, you wouldn't do it this way; you'd typically handle distributed systems comprised of multiple computers working together.
00:07:05
For example, databases often require geographic redundancy, and load balancers must ensure that all nodes are synchronized regarding which servers can handle traffic.
00:07:26
Etcd, which uses Raft, serves as the data store backing Kubernetes, along with other tools like Patroni, which is a consensus proxy ensuring database clients connect to the appropriate database instances.
00:07:55
A few points to consider: Ractor is experimental, and its behavior may change in future Ruby versions. Also, expect various implementation issues; using Ractor right now will trigger a warning.
00:08:23
I believe Ractor represents the future of parallel processing in Ruby, although that future isn't here yet. Currently, we're still learning about the best practices and patterns.
00:08:46
I've made it clear that you should not copy any of the code presented here as the definitive approach.
00:09:06
While Raft is currently stable, this talk will not cover a full implementation. We will take some shortcuts and I will discuss these throughout and at the end.
00:09:37
Error handling is essential. The Raft paper is a simple read; you don't need this presentation as a guide for implementation.
00:09:59
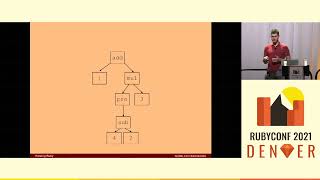
Now, let’s create a cluster with Ractors. These Ractors will communicate with each other to establish which one is the leader, add some data, ensure it replicates, and allow the cluster to elect a new leader if the original goes offline.
00:10:31
Creating a Ractor mirrors the process of making a thread. We will create five new Ractors and pass in an animal emoji as its name primarily for debugging.
00:10:47
Then, a block to run will be assigned. The block will loop to print the Ractor's ID and the animal name. Meanwhile, our main program will sleep for two seconds. When the main program sleeps, like threads, all other Ractors started will also exit.
00:11:14
Afterward, there won't be any significant surprises; each Ractor starts, printing logs declaring its identity: 'the cow says I'm the cow,' 'the cat says I'm the cat,' and so forth.
00:11:45
We need some additional setup for getting data into Ractors, anticipating data coming in with a command and a body (some data). We'll wrap it in a timeout block to manage time in case we don’t receive a message.
00:12:12
In the result, we will have a switch statement to handle the command appropriately. Here we have a command called 'configure,'
00:12:48
and we will send it the cluster. This is simply an array with a reference to each Ractor. Once we've created all of them, we will use the same block to send each a message into the incoming queue.
00:13:28
In a conventional scenario, this would reside in a configuration file on your servers, although we are displaying it this way.
00:13:50
Next, let's discuss how Raft elections operate. At any moment, a Raft cluster will have a term, which increments over time. For each term, an election takes place.
00:14:07
When everything functions smoothly, a leader will be elected. If no leader exists, nodes send out election requests to get elected as leader. Nodes may vote for the nominee, and if one gains a majority, it becomes the leader and starts disseminating messages to the cluster.
00:14:42
If we're in a situation lacking a leader and either we haven't voted in this term or our votes have been too delayed, we can start a new election. Thus, we reset our election timeout, determining that it has taken too long to succeed and initiating a new term. We vote for ourselves and send a request to each member of the cluster asking them to vote for us.
00:15:21
When a node receives a request for a vote message, it assesses a few things. Specifically, it checks if the term of the election is higher than its current term and whether it has already voted this term. You cannot vote for more than one member within a term.
00:15:53
If conditions are met, it votes for the candidate, marks that it voted, and sends the vote message, setting its random timeout. If a leader doesn't emerge by the time this timeout expires, we kick off a new election.
00:16:30
This randomness is crucial to avoid simultaneous self-nominating votes across the nodes, which could lead to a stalemate for the term. Sufficient randomness ensures that one candidate is elected smoothly while others are deferred.
00:17:06
When a node secures a majority vote, it declares itself the leader and broadcasts its victory to the cluster members. This election system is consolidated to utilize the same method used for appending data to the cluster.
00:17:37
Only the leader sends out append messages, establishing clear leadership through trust between nodes. The process continues, and if the cluster approves, it resets state and sends a note confirming the new leader.
00:18:17
In practice, the election process is crucial. The elected leader must have more data than any others, and if logic dictates otherwise, a new leader must be selected where data consistency is maintained.
00:18:49
This leads to a resilient cluster capable of storing and responding to client requests. After storing data, we collect logs showing that all nodes of the cluster share identical data.
00:19:19
It is essential to elect a leader and store data redundantly when clients are forwarding requests to the leader. The cluster cannot commit any data unless a leader is designated.
00:19:53
When the leader disappears or becomes inaccessible, the rest of the cluster must react by choosing a new leader efficiently. Heartbeats, which could be emptiest append messages, are sent periodically to ensure that nodes know the leader is still operative.
00:20:39
If a node experiences disconnection from the leader, it will track the time without communications, as heartbeats signal leader presence. Eventually, if a node passes its timeout, election processes will restart.
00:21:14
Our code will be adjusted for the timeout resets when a member gets a message from the leader, adding randomization to mitigate simultaneous election attempts. Consequently, we will introduce a message to handle the aftermath if we identify a leader.
00:21:40
If the Ractor connects with a leader, it ensures that successful messages are accepted. The process should exit smoothly. Ractor should also ensure to handle node departures gracefully without needing to raise exceptions in the case of closure.
00:22:10
We can observe this in practice. As we initiate the system and conduct an election, a node will notice a leader vacancy and attempt to elect itself, sending out requests for votes to others.
00:22:43
After voting occurs, the first node to notice the absence of a leader will gain the necessary votes and subsequently become the new leader, allowing the replication of data to continue smoothly.
00:23:18
From here, Raft achieves the necessary capabilities: having a cluster with an elected leader, storing and replicating data, and effectively responding to client requests even if the original leader goes offline.
00:23:55
Raft organization focuses on the importance of ensuring that elections yield verified, data-rich leaders. The cluster's election and operational systems are interdependent, relying strongly on the synchronization of all active nodes.
00:24:23
As we examine what we have constructed, critical aspects of the algorithm—such as data preservation, precise message delivery, and effective response mechanisms—come into play.
00:24:56
Once we've established our cluster, we have successfully created a framework that not only elects leaders and replicates data but also allows the continuity of functionality even with downtimes.
00:25:27
In concluding this session, it is vital to recognize that although we've implemented a substantial portion of Raft effectively, certain sections were bypassed for simplification purposes, such as ensuring data integrity through log length verification.
00:26:12
Moreover, many parts of Ractor, like local storage, which is reminiscent of thread-specific data storage, allow the retention and management of various persistent states, with APIs designed for advanced message management.
00:27:01
Ractors offer the chance to delegate complex tasks seamlessly while ensuring higher responsiveness and more straightforward error handling. It's quite the advancement in terms of performance benefits in Ruby.
00:27:45
I hope it was clear throughout that I'm genuinely excited about Ractor and its capabilities, opening new potential avenues for Ruby and reinforcing its position as a multitasking language.
00:28:26
Thank you all for your time. While I don't tweet much about programming, do feel free to follow me! I will have the slides and code available on GitHub in due course.
00:29:07
This is my dog Hoss; I would like to extend my gratitude to friends and co-workers who offered feedback during this session. A special thanks to the authors of Raft and Ractor.
00:29:43
Lastly, please remember to tip your hotel housekeeping staff—they work hard! If you have a work expense policy, it likely covers these tips.