00:00:16.600
So, well again, thanks for coming! My name is Carl, I work at Tilda, and this is my esteemed colleague, Yehuda Katz. I don't believe he requires much of an introduction.
00:00:23.080
Today, we're going to talk about measuring your app. But before we get started, I just want to begin with a quick story.
00:00:29.800
This was my first job out of college. It was your basic e-commerce app. They had products for sale, you added them to your cart, checked out, and processed your order. Pretty basic stuff.
00:00:40.879
On the day in question, I was tasked with implementing a simple feature. I was only supposed to tweak the coupon page on the checkout process.
00:00:46.320
I thought it was an easy job, and I did it in just a couple of hours. I shipped it out, and QA accepted it. They had a couple of testers who’d bang on the app to ensure everything worked well for them—very scientific.
00:00:53.239
So, the app went out to production, I went home, and everything seemed fine. Then, I got a call from my boss at 8 PM. He said, "Hey, how's it going?" At that moment, I knew something was off because he never called me.
00:01:10.439
He told me he was looking at some numbers and that the sales seemed low. I thought, "Okay, sales seem low."
He continued, "I was told you made some changes to the checkout process—I think you might have broken something." My boss was also the owner of the company. It wasn't too huge, but I could hear the stress in his voice.
00:01:27.600
I could imagine him at home refreshing sales reports every day, making sure nothing was broken. So, I got my computer out, thinking, "Alright, step one, let's see if I can reproduce the issue." No luck. I went through the entire process, and there was no problem.
00:01:42.640
It's late at night, and I decided the next step would be to revert my changes. Incidentally, this was a long time ago, and we didn't use source control, so that made reverting a bit tricky. It was a simple change, so I went by memory, reverted it, pushed it out, and sent an email to my boss, notifying him of the rollback.
00:02:00.240
Thirty minutes later, he called again. 'Sales are still down,' he said. Well, I hoped I had reverted correctly. I thought, 'Something went wrong.' Next, I decided to SSH into the server; that seemed like the obvious next step.
00:02:19.120
I added debug statements. At that time, I was actually first learning Rails, but this job was a PHP shop. Adding debug statements was much easier because you could do it on the fly and automatically reload the deployment. Nevertheless, I couldn’t find anything wrong. This took me about five hours of debugging.
00:02:39.839
It turned out that someone else had updated the Google Analytics tracking code that day, a minor JavaScript snippet. Having no source control made it complicated to track that change. On the checkout page, the JavaScript was interacting weirdly with our JavaScript in certain browsers.
00:02:57.000
As it happened, the problematic browser was Internet Explorer. I was young and didn’t think to check it. What lessons can we learn from this, besides the obvious one about using source control?
00:03:10.959
My boss had a hypothesis: sales were down. But nobody had a real way to validate that hypothesis quickly. He looked at some sales reports and kept hitting refresh multiple times. Meanwhile, I had my assumption that my coupon tweak was the culprit. Yet, I had no real way of validating that without diving into extensive debugging.
00:03:38.440
If I had been collecting even a little data beforehand, I think it would have made troubleshooting much easier. This is going to be the thesis of this talk. I hope nobody here would skip writing tests for their app; I'm going to convince you that you need to measure anything that matters in your app—anything that provides value.
00:04:06.560
This way, you can quickly detect when things break. Before we continue, let’s have a quick game: Which line is slow? On the next slide, I’ll show you a very basic Rails action with only two lines of code. This action is supposed to respond in about one second, and it’s up to you to determine which line is taking longer.
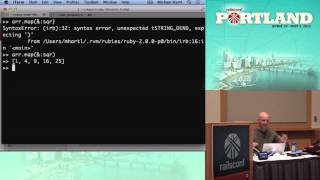
00:04:39.600
Here are the two lines. I’ll give you a minute to review them. So, who thinks line one? (One person raises their hand.) Alright, what about line two? (The vast majority raise their hands.) What does Yehuda Katz think?
00:05:03.639
I don't know. The second line of this action is 'users = User.where(admin: false)'. The action ends with 'render json: users.first'. So, in theory, what's happening here is that 'User.where' creates a scope, which is a lazy object. When you call 'first' on that lazy object, it's supposed to rewrite the SQL query to be efficient.
00:05:29.280
However, let me show you more. I'm telling you now that this code is in the model. That should be 'self.where', and it’s overriding that function. So, knowing that, which line do you think is the culprit? (Audience response.) Line one? (Quiet response.) Line two? You’re getting smarter.
00:05:55.440
Here’s the measurement: the first line takes 0.1% of the request time, while the second line takes 0.4%. So now we have some data, and we can continue looking further for the problem.
00:06:22.159
Here we find a filter with a bit of code. Many of you have probably seen code like this before. The main point is that this is somewhat of a tongue-in-cheek example, but I'm sure no one here knows every line of code running in their Rails app.
00:06:52.680
Even if you're the sole developer on that app, there are probably hundreds of gems you’ve pulled into it, and you don't know every line. This brings us to how we address performance and issues when things go wrong.
00:07:13.680
I was at CodeConf a few years ago and heard a talk by a gentleman named Go To Hale. What resonated with me was his statement that as developers, we aren't merely paid to code—we are paid to provide business value.
00:07:37.040
We're paid to write code, but that code must add features, improve speed, or contribute something that provides real value to the business. That means what really matters is what's happening in production, not how it runs faster on your development box.
00:08:09.720
How can we measure what’s actually happening? We need to have a correct mental model of how our code runs in production, and we achieve that by measuring.
00:08:29.440
So, what do we measure? The simple solution is to measure business value. We need to analyze our application's responsiveness and how users complete tasks that ultimately make us money.
00:08:55.680
Going back to my original story, the obvious thing I could have measured was revenue. This is probably the key metric for most businesses—unless you are a Silicon Valley VC-backed startup.
00:09:16.560
If I had a graph with a line showing dollars made per minute, I would have seen the drop-off in revenue after my changes. It could have been as straightforward as a visual cue, saying, 'Oh, I deployed this change, and now the revenue is plummeting.'
00:09:41.120
Moreover, we can take this data, save it, and use it as a reference to notice trends. We can create benchmarks to gauge expected revenue throughout the day and have tools to alert us anytime the current performance falls below our set thresholds.
00:10:06.880
Imagine that if our boss didn't have to call us a few hours later about broken functionality, we would all be happier. A quick alert could notify us within five minutes of a deployment that something went wrong.
00:10:33.640
We need to go beyond a simple metric. If I know something is wrong and we’re not making money, I need to quickly make a decision on what’s broken. This requires an understanding of all the steps in the money-making process.
00:10:56.880
We should be tracking every step. For instance, let's track how many users add items to their shopping cart, how many items get added, and how many items get removed. Then we need to measure the number of users who check out and the number of users having successful orders.
00:11:23.640
I suspect you are using tools to measure this on the business side, but as developers, we also need tools to measure performance for ourselves. This would allow us to investigate the data when something goes wrong.
00:11:42.480
If it's important for your business, you should measure it. If it’s not measured, how do you know it’s working? Performance is also directly tied to business value.
00:12:12.320
You've probably heard studies from companies like Google and Amazon, which reveal how significant response times can be. Google discovered that each 0.1-second increase in search result time decreased ad revenue by 20%, while Amazon experienced a 1% sales loss for every additional 100 milliseconds.
00:12:30.560
Performance is critical for business as well. However, the good news is we already have tools to measure the average response time for our app, although there’s a caveat.
00:12:54.960
I need to venture into academia briefly. Many developers hear the term average response time and think they are getting useful information to understand how their app performs.
00:13:14.480
However, I’m here to tell you that relying solely on averages creates a misleading and broken mental model of what’s going on. Let's start from the basics: to calculate an average, you sum all the numbers in your list and then divide by the count.
00:13:51.679
That’s fairly straightforward and relatively easy to collect data on. In contrast to the average, let's discuss the median, which is more useful. The median is found by arranging numbers in order and identifying the middle number or the average of the two middle numbers.
00:14:15.279
This method isn't as easy to implement because you need to maintain all the numbers to calculate the median. Furthermore, the standard deviation is also important but harder to collect—it's a measure of how dispersed the numbers are in your data set.
00:14:40.480
For instance, imagine we have a set of integers. A standard deviation of 4.96 means that moving 4.96 in either direction from the mean reduces the likelihood of hitting any particular number.
00:14:59.679
Most people’s mental models are rooted in the bell curve. For example, let's say someone tells you the average response time is 50 milliseconds with a standard deviation of 10 milliseconds. Using that, you might think that 68% of your requests will be between 40 and 60 milliseconds.
00:15:29.120
Moreover, the assumption would be that as you move farther out, the likelihood of encountering a much longer response time diminishes. However, in the real world, it is often more complex, and the distributions don’t resemble normal distributions.
00:15:52.840
Take, for example, the height of people. If we say the average male height is 60 inches with a standard deviation of 3 inches, that means around 68% of all men are between 57 and 61 inches tall.
00:16:18.080
But what if I told you the average salary of workers in the U.S. is around $60,000 with a standard deviation of $30,000? The distribution becomes skewed, and your intuition tells you that there won’t be many high earners.
00:16:44.080
However, the reality is that high salaries can exist. In fact, the distribution shows that the longer the tail, the less likely it seems for them to exist in our initial understanding.
00:17:07.280
To illustrate, when learning we adapt a mental model where we think many values converge around the mean—with some tolerances around the edges. We might overlook vital information that’s occurring beyond those limits.
00:17:27.840
If I tell you that the mean response time is 100 milliseconds with a standard deviation of 50 milliseconds, you'd expect 95% of requests to be between 20 and 80 milliseconds.
00:17:46.960
However, the real world dictates that outliers can exist. Thus, an outlier response time of 500 milliseconds, which seems way off, turns out to be not as rare as we think.
00:18:08.640
This misunderstanding can be hazardous as many web performance metrics don't follow normal distributions. Many web requests often present a long tail, meaning that the data can extend out into the distant right.
00:18:31.280
The skewed view diverges from the normal distribution like we expect, meaning we need insights into the long tail. We need a better understanding of this reality.
00:18:52.960
Instead of the normal distribution, web responses behave more like long-tailed distributions. So, for example, with an average response time of 150 milliseconds and a standard deviation of 50, a 500-millisecond response time might actually be more common than we suspect.
00:19:14.960
Again, while this does not mean half of all requests take that long, it implies that a notable proportion will fall in that category.
00:19:36.560
To summarize, if your mental model is that things cluster around the mean, you're missing a large chunk of reality. If you focus solely on data around the mean, you risk missing crucial insights related to web response performance.
00:19:58.720
The same applies to understanding outliers when performance bottlenecks arise in your application. For instance, if I were to tell you that the 95th percentile is 500 milliseconds, that would still highlight that one in every twenty requests is likely slower than this.
00:20:21.280
The count of slower requests should promote you to act rather than dismiss them solely based on averages. We’re developing a tool called Skylight, which focuses on accurately measuring distributions in a way that enhances your understanding of application performance.
00:20:51.040
Currently in MVP mode, Skylight aims to replace outdated methods, providing fast, practical insights into the distribution of performance metrics. Observing actual response distributions is an essential part of understanding how your application performs.
00:21:22.160
It's worth noting, that tools offering real-time data don't depict the ideal outcome derived from averages or expectations alone. Users can see legitimate differences like where their slowest requests and the faster requests intersect, allowing you to make better decisions.
00:21:42.680
As we analyze a large number of requests, we may discover that certain requests demand more concentration or attention, leading to informed decisions about where optimizations need to take place.
00:22:04.280
It's essential to highlight the importance of understanding response distribution rather than relying on a simple average. In real-world statistics, averages often create misconceptions when navigating performance issues.
00:22:24.960
To ensure accurate metrics, Skylight focuses on identifying key trends amongst average response times—segregating the fast from the slow while eliminating factors such as GC noise.
00:22:50.560
This has resulted in more informed handling of slow requests. In short, analysis of complete distributions leads to a more thorough understanding of your application.
00:23:11.560
Lastly, we are excited and engaged, using real data to influence improvements. Feedback from real users greatly shifts our focus when rectifying issues, highlighting the importance of accurate metrics.
00:23:30.560
Real-world insights can help highlight patterns that guide future decisions about application performance. Bringing about a better product requires understanding what’s truly happening.
00:23:56.880
If you're ready to be part of the journey, we encourage you to visit our booth. Your feedback will ultimately shape Skylight and elevate how we measure application performance. Thank you for joining us.