Talks
Optimizing Ruby's Memory Layout

#memory-management
#garbage-collection
#ruby-internals
#performance-optimization
#variable-width-allocation
#ruby-vm
Summarized using AI
Optimizing Ruby's Memory Layout
by Peter Zhu and Matt Valentine-HouseThe video titled "Optimizing Ruby's Memory Layout," presented by Peter Zhu and Matt Valentine-House at RubyConf 2021, discusses the current memory model of Ruby, particularly its fixed-size slots for object storage and the inefficiencies arising from this structure. The presentation highlights their Variable Width Allocation project, aimed at improving Ruby's memory management to enhance performance. Key points discussed in the video include:
- Ruby's Memory Management: Ruby uses a garbage collector to manage memory with an object representation known as 'r value,' which is fixed at 40 bytes, including flags and pointers.
- Garbage Collection Phases: The garbage collection process consists of marking live objects and sweeping the heap to reclaim memory. Optional compaction helps reduce memory fragmentation.
- Issues with Current Layout: Problems arise from objects needing multiple memory allocations, causing poor cache locality. Ruby's current model may lead to increased fetching times due to frequent malloc calls, negatively impacting performance.
- Variable Width Allocation: This project aims to integrate both object data and additional memory directly within Ruby's heap, significantly reducing malloc calls. This can improve data locality and reduce memory overhead.
- Performance Benchmarks: Early benchmarks showed a decrease in memory usage by 4% and performance improvements in scenarios using the new allocation methods, demonstrating a 35% increase in string comparison speed.
- Future Directions: The speakers discuss plans for expanding coverage to more object types, enhancing string resizing capabilities, and reducing the size of the r value structure to better align memory allocation with CPU cache lines.
The overall conclusion emphasizes the potential for improved performance and greater control over memory management in Ruby, making it an ongoing area of development and optimization for the community.
00:00:10.240
Hello RubyConf! I'm Peter, and I'm a Ruby core committer and senior developer at Shopify, working in the Ruby infrastructure team. Matt is also here with me; I'm a senior developer in the same team at Shopify. For the past year, we've been collaborating to improve how memory is laid out in Ruby.
00:00:22.400
In this talk, we're going to summarize the work that we've done so far, the challenges we've faced, and our future direction. Before getting into the details, we will provide some background on how Ruby's garbage collector structures and manages memory.
00:00:34.880
When we create an object in Ruby, the interpreter stores a data structure called an R-value in memory to hold it. The R-value is always 40 bytes wide and contains a union of different data structures that represent all possible Ruby core types. This means it can represent a string, an array, a class, and so on.
00:00:43.559
Each of these types contains its own fields and data structures specific to that type, while the R-value itself serves merely as a container for Ruby objects. Let's take a closer look at one of Ruby's object types, the class. The first 16 bytes of every type are always the same: an 8-byte field called flags, followed by an 8-byte pointer to the class of the object. The remaining 24 bytes vary across different types.
00:00:59.840
For class objects, they store a pointer to an extension object, while strings can store the actual string content, and so on. R-values are organized into regions called pages. A heap page is a 16-kilobyte memory region with a maximum of 409 slots, where each slot can hold one R-value. Importantly, the memory region of a heap page is always contiguous, with slot addresses being 40 bytes apart and no gaps in between.
00:01:09.920
Initially, when the heap page is created, all slots are filled with an internal type called T_NONE, which signifies an empty slot. This empty slot contains only flags and a pointer value called next, which can point to an R-value. This design allows empty slots to be linked together, forming a data structure known as the free list.
00:01:31.680
During initialization, Ruby traverses each page, visiting each slot one by one. As it arrives at each slot, it sets a pointer on the heap page called the free list pointer to the address of that slot and then sets the slot's next pointer to the address of the previously visited slot, creating a singly linked list of empty slots.
00:01:49.519
When an object needs to be allocated, Ruby requests an empty slot by asking the heap page for the first slot on the free list. The heap page returns the slot, and the free list pointer is updated to point at the next slot in the list. This unlinking of the slot from the free list allows data to be stored in it. The use of a free list results in fast allocation, maintaining constant time complexity even when the page is sparsely populated.
00:02:05.840
However, eventually, heap pages will run out of slots, necessitating the intervention of the garbage collector. If the free list is empty when Ruby attempts to allocate memory, it indicates that there are no free slots remaining in that page. Now, Peter will discuss how and when the garbage collector runs to release objects that are no longer needed.
00:02:22.720
Over to you, Peter! Now that we've examined how memory is structured inside Ruby, let's delve into how Ruby's garbage collector operates. The garbage collection process in Ruby encompasses three distinct phases: marking, sweeping, and compaction. The compaction phase is optional and will only execute if manually enabled.
00:02:39.680
During the garbage collection, Ruby ceases all code execution, meaning Ruby code will not run while the garbage collector is active. Given the complexity of garbage collection in Ruby, we cannot cover all technical details in just a few minutes, but we'll provide a high-level overview that captures the essential information needed for this talk.
00:02:54.400
Let's first discuss the marking phase, which determines which Ruby objects are alive and which can be freed. We begin by marking the roots, which include global variables, classes, modules, and constants. Following this, we perform a breadth-first search to traverse the network of live objects.
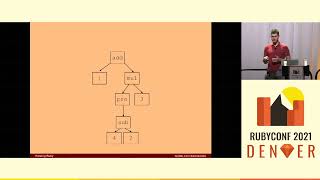
00:03:11.440
For example, in a hypothetical heap with two pages featuring seven slots each, if we have a total of ten objects labeled A through J, with empty slots indicated, the arrows denote references. For example, the arrow from object J to object D indicates that object J holds a reference to object D. References could be the contents of arrays or instance variables of objects.
00:03:31.760
The first step of marking is to mark the root objects A and B. From objects A and B, we discover that objects C and G are reachable and have not yet been marked, so we proceed to mark them. Then, from objects C and G, we find that objects F and H are reachable and unmarked, so we mark them too.
00:03:45.679
At this stage, objects F and H do not refer to any unmarked objects. Since we haven't marked any new objects in this step, we can conclude that marking is complete. All marked objects are now live, and all unmarked objects are deemed dead and can be reclaimed by the garbage collector.
00:04:05.920
We can simply scan the slots on the pages and free those that remain unmarked. Continuing with our earlier example, we place our cursor at the first unmarked object, which is object D. We can free this object to reclaim its memory.
00:04:20.240
Next, we advance the cursor until we encounter another unmarked object, which is object E. After completing page one, we move to sweep page two. Again, we continue until we find our next unmarked object, and we will free object I, then proceed to object J. Having swept all pages, the sweeping phase concludes.
00:04:31.760
The compaction feature was introduced in Ruby 2.7, and further improvements were made with automatic compaction in Ruby 3.0. This compaction process, although beneficial, remains turned off by default. Compaction relocates objects within the heap to the start of the heap, yielding several advantages such as reduced memory usage, faster garbage collection, and improved copy-on-write performance.
00:04:50.000
Ruby employs the two-finger algorithm for compaction, which we will explain in more detail. The compaction algorithm involves two steps: the compact step and the reference updating step. During the compact step, objects are moved from the end of the heap to the start. Once that step is complete, we proceed to update the references.
00:05:07.360
For example, consider the last live object in the heap is object H, while the first empty slot is slot one. We would move object H to slot one while leaving a forwarding address to indicate the original location of this object. This forwarding address will guide us in the reference updating step.
00:05:29.759
Next, we move object G to slot four and leave a forwarding address. Following that, object F is moved to slot five, again leaving a forwarding address. The compact step completes when there are no more objects left to move.
00:05:46.239
However, we still need to conduct the reference updating step. Let’s say our object references look as follows, where the arrows indicate references to other objects. We must check each object's references and update any that point to a forwarding address. For instance, if object B references a forwarding address, we would read this address to update it to point to the correct object, which could be object H.
00:06:06.639
Next, object C may hold multiple references to moved objects, so we will update these references to correctly point to their new locations. After updating all references, we can reclaim the forwarding addresses since they are no longer needed, allowing us to free up slots seven, eight, and eleven.
00:06:25.239
Now that we have covered how the garbage collector operates, let's reflect on something we’ve observed: the slots we've discussed always seem to be of a fixed size. Matt will discuss how we handle scenarios where objects require additional data.
00:06:41.720
As we have seen, Ruby objects aren't always of a fixed size. We need to consider two primary scenarios: when the object fits within the 24 bytes remaining in an R-value, and when it does not. For instance, consider the strings 'Hello World' (which is 12 bytes) and 'Hello RubyConf, thanks for having us' (which is 36 bytes).
00:06:56.480
When Ruby allocates a string, it checks the requested string length against an internal constant called R_STRING_EMBED_LEN_MAX. If the requested length is shorter than this maximum (as it is for 'Hello World'), it simply copies the string data into the remaining space in the slot after the flags.
00:07:10.720
However, if the length exceeds R_STRING_EMBED_LEN_MAX, Ruby sets a bit in the R-value’s flags called the NO_EMBED bit, signifying that the data is not stored in the R-value, but rather a pointer to a separately allocated memory region. To manage this, Ruby uses malloc to allocate a new memory region outside the existing heap and stores the address in the R-value's 24-byte space after the flags and class, subsequently copying the string data into the newly allocated memory.
00:07:26.559
With this, we have explored the primary ways Ruby stores objects in memory. Now, Pete will discuss some challenges associated with this memory layout and introduce our project, Variable Width Allocation, which aims to address those challenges.
00:07:41.680
Let’s discuss some bottlenecks within the Ruby heap that we are looking to tackle with this project. One major issue is that a Ruby object often requires several pieces of memory to store all its associated data. We've encountered examples like the string allocation, where the content resides at a separate location from the string object itself, leading to poor cache locality.
00:08:01.680
Moreover, this memory is frequently acquired through the system via malloc, which carries a performance cost. We commonly perceive that the CPU only has a single level of memory, but that's not accurate. To enhance performance, there exists faster memory incorporated directly onto the CPU called caches.
00:08:17.520
Caches are usually divided into multiple levels, usually three, with the lowest level being closest to the CPU core. This proximity allows electrical signals to travel shorter distances, enhancing performance. It's beneficial to discuss how CPU caches function; anytime a piece of memory is fetched from main memory, it is correspondingly stored in the CPU caches.
00:08:34.800
It’s crucial to understand that data is retrieved from main memory in cache line units—in x86 architecture (as generally seen in Intel and AMD CPUs) this is 64 bytes. Therefore, even if only a single byte of data is required, all 64 bytes are fetched. When CPU caches reach capacity, they overwrite the least recently used data to accommodate recently accessed data. We refer to this as a cache hit when requested data exists in the CPU cache, negating the need to access slower main memory, whereas a cache miss occurs when it doesn't.
00:09:00.560
To optimize performance, one key metric is to increase the cache hit rate, thereby minimizing the frequency of reads from slow main memory. Let's delve into the cache performance of the current Ruby implementation, examining an array as an example. In the existing implementation, an array points to a memory region in the system heap, allocated through malloc to hold its contents.
00:09:18.880
If our array comprises four elements, it requires four pointers to Ruby objects. Since each pointer occupies eight bytes on a 64-bit system, this necessitates 32 bytes of memory. Meanwhile, the array object itself consumes one R-value, totaling 40 bytes, while the content requires 32 bytes of additional space.
00:09:35.040
To access the elements of this array, two memory fetches are required, needing two cache lines. Acquiring memory from the system heap using malloc incurs a performance overhead; thus, it is beneficial to minimize the instances where we call malloc. Additionally, malloc requires space for headers that must store metadata when allocating memory, which can accumulate to result in increased memory usage.
00:09:49.680
We're not the first to pursue solutions for optimizing memory allocation in Ruby. Ruby 2.6 introduced an additional heap called the transient heap, intended to enhance Ruby's speed by decreasing the count of malloc calls. This initiative yielded positive results, with some benchmarks demonstrating up to a 50% performance improvement. Nevertheless, the transient heap has inherent limitations and cannot serve as a comprehensive solution.
00:10:10.080
The primary goal of our project is to bolster Ruby's overall performance by allowing Ruby to manage its memory layout directly, rather than depending on the malloc system library. Given that Ruby’s garbage collector is familiar with the memory structure of each object type, it can optimize for faster allocation and improved efficiency. By placing object contents directly following the object itself, we can enhance cache locality.
00:10:30.800
With the introduction of dynamic width memory allocation, Ruby can avoid making malloc system calls, thus improving performance. Now, let’s explore changes in the memory layout when we apply variable width allocation. Using the previous array example, this project seeks to transfer the array's data from the system heap to the Ruby heap, right after the object itself.
00:10:50.200
What does this accomplish? It eliminates the need for a malloc system call during the creation of the array object. Let’s assess whether we improve cache performance. Every Ruby object necessitates an R-value allocation, which is 40 bytes. The array's data comprises 32 bytes, and by placing the array's contents directly adjacent to the object, we can access the first three elements while remaining within the same cache line.
00:11:10.480
Thus far, we've integrated two iterations into Ruby, with the third open for feedback. In our initial two pull requests, we established the necessary infrastructure to transition data from being allocated in the system heap to residing within a heap page alongside the corresponding R-value. We also provided a reference implementation within our class.
00:11:27.680
The changes implemented thus far have been minimally invasive; this feature remains off by default and requires recompilation with a compile-time flag to enable. In our most recent pull request, we executed variable width allocation for strings and, given our confidence in this stability and performance, proposed to switch it on by default.
00:11:45.280
We'll discuss the performance outcomes later. Now, let's walk through an example of what this work actually entails, specifically with class allocation. Two scenarios for allocating R-values containing R-class objects exist; a class carries attached data such as its instance methods and instance variables. Thus, Ruby generates a separate data structure for this, known as RB_CLASS_EXT, which is fixed at 104 bytes and is allocated in the system heap.
00:12:01.280
This is the code for class allocation that doesn’t utilize variable width allocation. First, we acquire an R-value from the garbage collector using NEW_OBJECT. Then, we allocate space for the RB_CLASS_EXT struct using Z_ALLOC, which invokes malloc to get memory. In contrast, when we apply variable width allocation, we call a different NEW_OBJECT entry point that requests an allocation size.
00:12:18.560
This size encompasses the total bytes for the R-value and the RBA_CLASS_EXT struct combined. For instance, it would require 144 bytes for 40 bytes of the R-value and 104 bytes of RB_CLASS_EXT. The garbage collector ensures at least the requested size is allocated, but it may also allocate a larger slot than needed.
00:12:37.280
By observing the allocation process for classes using variable width allocation, we see that the garbage collector now has the capability to allocate space for both the R-value and the RB_CLASS_EXT struct within a single slot, thus optimizing memory allocation. Of course, this may result in slight wasted space, but it increases the efficiency of memory-use overall.
00:12:54.880
In our latest pull request, we also implemented variable width allocation for strings. Unlike classes, which have fixed-size data structures, strings can vary in length, presenting some challenges in handling their allocation effectively. Previously, only strings shorter than 24 bytes could be embedded as part of the object.
00:13:25.200
With variable width allocation, we modified string allocation to permit embedding of longer strings. For example, consider our example strings 'Hello World' and a longer string 'Hello RubyConf, thanks for having us.' The first string remains embeddable, while the second string, previously too long, can now also be embedded.
00:13:39.520
When we allocate the headers, flags, and class as usual, we can directly push the string content in directly thereafter. Those with keen observational skills may note that the string headers are now 18 bytes, instead of 16, since they now require additional space to store the longer embed length.
00:13:49.319
After allocating the headers, the contents amount to 12 bytes, necessitating 30 bytes in total—that fits within the slots of our first size pool, which each are 40 bytes. Therefore, we request a free slot in which to allocate, with 10 bytes left unused at the end of the slot. Now, let’s look at what happens when we try to allocate longer strings.
00:14:07.440
For instance, if we try to create a string that doubles in size by appending itself, it will exceed the slot limits. Currently, we do not have an efficient method in place to manage this resizing. Instead, we revert to an external allocation, akin to previous implementations where the content would be stored outside the Ruby heap. To convert an embedded string to a non-embedded type, we allocate memory for the new longer string using malloc.
00:14:23.720
Next, we modify the R_STRING headers to utilize the original 40-byte structure and set the NO_EMBED bit in the flags. Finally, we set the string’s data pointer to reference the newly allocated region. At this point, our string behaves as if it had been allocated prior to implementing variable width allocation.
00:14:43.760
However, this fallback solution results in wasted space beyond the initial 40 bytes; when resizing, if we remain allocated in an 80-byte slot, we waste as many as 40 bytes. Although this may not yield an immediate significant impact on performance for our workloads tested, it remains a concern for future solutions.
00:14:59.680
Now Peter will discuss our benchmarks and how we measure runtime and memory performance throughout this project. We implemented variable width allocation and committed it to the Ruby master branch using a limited amount of production traffic on a Shopify service, where we collected data across a day, serving around 84 million requests.
00:15:11.360
We did not notice any response time changes beyond the margin of error while analyzing average response times across multiple percentiles. However, we did find that variable width allocation decreased memory usage by approximately 4%. Additionally, synthetic benchmarks were run on a bare metal Ubuntu machine using Rails benchmarks and RDoc generation.
00:15:27.760
Using 'mc' and 'je malloc' as our allocators, we reviewed how different allocator implementations affected performance, given that various implementations yield different properties. The default allocator in Ubuntu is glibc, and if you wish to view deeper results and insights, refer to the linked ticket in our slides.
00:15:45.680
In the Rails benchmarks, we observed a slight increase in memory usage when using 'gwc' but no increase when using 'je malloc'. Notably, we also saw a small performance improvement for both allocators. The graph illustrates the residency set size (RSS), indicating the RAM memory held. We executed both branches twenty-five times each, each run encompassing 20,000 requests.
00:16:01.840
In the graph, the memory usage over time is depicted, with variable width allocation shown in green and the master branch in blue. The RDoc generation of Ruby documentation highlighted that, while variable width allocation generally increased memory usage, it ultimately results in significantly lower memory usage relative to increases in performance.
00:16:15.840
Micro-benchmarks were created to highlight variable width allocation's performance improvements. These benchmarks evaluated 71-byte strings, which would be embedded during variable width allocation and not during standard allocation. The benchmark results indicate that comparing two strings was 35% quicker, while allocation speed improved by 15%. Likewise, setting a character within the string also enhanced performance by 15%, demonstrating the benefits from variable width allocation.
00:16:32.720
We feel confident in the stability of variable width allocation, as it successfully passes all CI tests on Shopify's Rails monolith. We also tested it over a week using a small portion of production traffic, which processed over 500 million requests. Based on positive feedback from our benchmarks, we recommend that variable width allocation be enabled by default.
00:16:47.760
As of the recording of this talk, the proposal is open for feedback. Given that it may have undergone changes or even merged, please check the ticket linked in the slides for the most up-to-date information. Now that you’ve reviewed our current implementation alongside the performance results, Matt will now discuss some limitations we encountered and outline our strategy for addressing these issues.
00:17:06.640
The first limitation we want to address is increasing coverage. Presently, only classes and strings are capitalizing on the advantages that variable width allocation offers. To further enhance performance, we need to extend this capability to as many object types as possible.
00:17:24.240
Next, we must address the challenge of resizing. As discussed in our string implementation, we currently lack an elegant resizing solution for objects. This represents a significant challenge and is one of our immediate priorities. We are considering leveraging garbage collector compaction to assist in moving object data when resizing is necessary.
00:17:39.400
When we need to enlarge an object and the current slot proves inadequate, we could allocate the new data to a slot in a larger size pool and then utilize compaction to reposition the original object structure adjacent to its data while releasing the obsolete slot.
00:17:57.520
Another aspiration is to reduce the size of the R-value structure from 40 bytes to 32 bytes. This reduction would align slots in the heap page with CPU cache lines. In the accompanying diagram, you can observe that numerous 40-byte slots cross over two cache lines, requiring two potentially costly cache lookups for reading a single slot.
00:18:14.640
If we shrink the slot size down to 32 bytes, all slots become precisely aligned within cache lines, ensuring that reading from a slot never necessitates more than a single cache lookup. However, such an adjustment is not feasible at present, as many objects still rely on the complete 40-byte allocation; resulting in being assigned to a 64-byte slot or greater and consequently wasting up to 24 bytes or more.
00:18:30.280
Overall, we take pride in the progress we've made, yet understand that there remain challenges ahead and plentiful avenues for exploration. We plan to update the community regularly concerning our progress via conference talks and blog posts. For now, one of the best ways to keep track of our initiatives is through the Shopify Ruby fork on GitHub and the Ruby core bug tracker.
00:18:47.920
And that concludes our discussion. In this presentation, we examined how Ruby's memory allocator and garbage collector operates, shared insights into issues faced in Ruby's memory layout, and detailed our approach to remedying them with variable width allocation, as well as our ongoing progress in this project. We're committed to enhancing the implementation, and while there's a great deal of work still to be done, we appreciate your attention and thank RubyConf for hosting us.






















































































Explore all talks recorded at RubyConf 2021












+92