00:00:12.830
All right, everyone. Welcome, and thanks for coming to my talk. I'm here to talk about Postgres at any scale.
00:00:19.890
To start off, here's some contact information. If you have any questions afterward, you can find me on Twitter as @leinweber. I work for Citus Data, and here's our website for those who don't know us.
00:00:34.710
For those of you who may not know me, you might have installed my gem, Bundler, which requires Bundler itself.
00:00:40.290
I created this a long time ago out of frustration. You know how it goes: you run `bundle install`, `bundle update`, and then when you want to install, you accidentally type `gem install bundler`. After making that mistake so many times, I decided to create this gem. It's essentially a gemspec, and it might have one of the highest number of downloads per line of code for any gem. So, you might have it on your system.
00:01:07.400
In this talk, I'm going to cover three different stages of a Postgres database's lifecycle. I'll start with when you're just beginning and your data is small, discussing how to take advantage of Postgres features at that small scale.
00:01:18.750
Next, we’ll look at what happens as you scale to medium size and how operations change with a medium-sized Postgres database.
00:01:31.020
Finally, we'll address strategies for handling large scales of data, as well as how to manage that transition effectively.
00:01:41.960
When we talk about large sizes, we need to consider different factors that can affect performance. It’s not just about overall data size, but also the fluctuation in data – how much you're writing to the system compared to how much you're pulling out. For instance, a database with minimal data that's constantly being read and written will behave differently than a database that has a large amount of static data.
00:02:19.800
So, when designing your system, consider both the overall size of the data and your data processing needs. Before you even get started, it's important to plan for where your database might end up as you scale.
00:02:46.890
This can be easier said than done. Oftentimes, things start small and then snowball out of control, leaving you scrambling to manage everything before you realize it’s too late. I hope that some of the concepts in this talk can help you prepare for that and put things in place while you have the time.
00:03:05.550
The very first thing I'd like to stress is please take backups. You’ll hear this in every database talk, and yes, it is crucial. It's not enough to just take backups; you also need to restore them periodically to ensure they're functioning properly.
00:03:24.510
You want to test your backup system when your database is small because the feedback loop for backing up and restoring is much quicker at that stage. Additionally, the system is less complicated, allowing you to focus and make sure everything works as expected. The tool that comes with Postgres, `pg_dump`, works very well for this purpose.
00:04:05.100
It creates a logical backup, which means if you need to restore the backup on a different system architecture or a different Postgres version, it will work just fine. We'll talk later about a tool that does physical backups, which require matching versions.
00:04:28.830
It's super important that you test your backups regularly. I've said it before, and I’ll say it again – you don't want to find out that your backups don't work when you're in a crisis. It’s essential to stress this point.
00:05:14.150
When you're starting out with a small database, embrace the constraints that Postgres offers. There are many constraints you can choose to enforce, allowing you to impose data integrity rules that ensure assumptions you make in your application are enforced at the database level.
00:05:41.680
Using constraints effectively is one of the best ways to leverage Postgres. People often overlook this aspect, focusing instead on more flashy features, but it’s a powerful aid for maintaining data integrity throughout your application and database.
00:06:25.470
For example, unique column constraints should be enforced directly in the database instead of relying solely on application-level validations, which might change in the future. Other constraints we can discuss are often lesser-known but very useful for keeping data consistent.
00:06:55.000
Despite Rails popularizing the idea of embracing constraints, it's often underutilized in actual database design. If you use the unique constraint in your database alongside application-level checks, you will greatly reduce the chances of bad data entering your system.
00:07:30.080
Maintaining tight control over your data integrity at the database level can prevent long-term headaches when bad data is continuously written during ongoing application development. Ideally, your database should act as the final guard against bad data.
00:08:07.340
The simplest constraint you can implement is making sure that your columns are not nullable. Despite how basic this may seem, I frequently see applications where this constraint isn't set. By default, columns are nullable, but best practice suggests that you should explicitly define non-null constraints.
00:08:35.560
You’ll likely find 'weird cases' where assumptions about data integrity in your application don't hold true. Whenever you consider that a column should always contain data, enforce this at the database level to eliminate surprises later.
00:09:05.850
Another interesting constraint to consider is a unique index across two columns. For example, if you're handling reservations, you can ensure that no one can make two reservations for the same person and the same room simultaneously.
00:09:36.680
Postgres supports creating unique indexes based on combinations of data, which is very powerful. Beyond these constraints, it’s important to leverage the diverse range of data types that Postgres offers.
00:10:01.770
With Postgres, you can use specialized data types like `macaddr` for storing MAC addresses, ensuring that only valid MAC addresses can be entered. This helps prevent invalid data from being saved into your database.
00:10:57.060
Moreover, creating custom data types is quite straightforward with Postgres, and JSONB is one such type that allows you to store semi-structured data.
00:11:01.270
JSONB ensures the data is well-formed, provides special operators for manipulating this data, and has great use cases across various applications. You might find it useful to have some structured columns alongside a JSONB column.
00:11:55.500
Moving on, another lesser-known but important feature in Postgres is the range data type, which allows you to store both start and end points in a single column.
00:12:06.550
This can be particularly useful for managing time periods, allowing you to ensure that start times and end times do not overlap when storing billing information, for example.
00:12:42.360
You also need to be aware of ensuring that any event does not conflict with others when managing ranges, which can help prevent double-billing situations.
00:13:05.620
Exclusion constraints are great in Postgres to avoid such conflicts. This flexibility can really help when developing applications, reducing the chance for costly errors.
00:13:40.160
Constraints in Postgres can also be custom-defined using check constraints, allowing you to enforce rules such as ensuring a number is only positive or follows the Fibonacci sequence, although this might be more of a niche case.
00:14:22.860
On the medium size side of things, when you begin to have more than 100 GB of data or ramp up your write operations, you’ll realize potential performance bottlenecks.
00:15:03.160
Most applications either stay small or shoot right through medium size to large scales without much time spent here, but there are still improvements that you can make.
00:15:31.700
This stage is a good time to review your constraints and data types from the earlier phases to ensure you're set up for success.
00:16:02.240
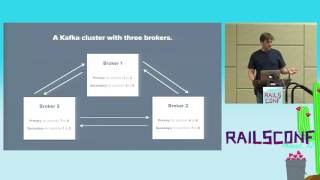
As you scale beyond what a single machine can handle, you'll want to consider implementing a hot standby.
00:16:20.880
This allows your main instance to failover to a standby in case of any issues. Regarding backups, at this level, you’ll also want to start using useful tooling like `Wally`.
00:16:49.800
Wally makes use of write-ahead logs to maintain continuous backups. Having well-structured backups in place can save you during an outage.
00:17:15.360
As we delve deeper into Postgres, we set and enforce various database constraints and practices for maintaining data integrity. Moving to large scales, things become even more complex.
00:17:50.780
You’ll need to proactively prepare your systems to allow for larger data sets over time. Once you scale, look at implementing sharding to distribute data effectively.
00:18:11.060
When your database can't handle the load anymore, consider distributing it across several smaller databases, with your application managing data access.
00:18:40.020
Citus is an open-source extension for Postgres.
00:19:00.220
Once your application outgrows single-instance Postgres, Citus can help divide and conquer by distributing writes across different nodes.
00:19:26.610
Through its architecture, you'll maintain the ease of use and familiarity of Postgres while enjoying the benefits of a distributed system.
00:20:01.870
With Citus, you have capabilities such as handling higher write rates and greater data storage by distributing load over multiple nodes.
00:20:37.980
This also simplifies scaling during global events, reducing performance issues.
00:21:01.520
We’re able to handle impressive write rates on a distributed architecture, and scaling out allows significant performance increases.
00:21:27.370
You could have over 500 times improvement for query executions when utilizing multiple cores via distribution.
00:21:53.060
To summarize, handling larger datasets in Postgres is about leveraging its various features and constraints effectively.
00:22:14.520
Invest in proper backups and ensure that you're equipped to effectively utilize sharding as your application grows.
00:22:33.180
Communication is key, both with your team and stakeholders – everyone must be on board with the importance of maintaining data integrity.
00:23:01.630
You must also develop a solid monitoring system to recognize significant changes in performance proactively and deal with them before they become problematic.
00:23:35.170
Thank you for attending this session. I hope you gained valuable insights into managing Postgres at various scales. If you have any questions, feel free to ask.
00:24:48.420
I hope this talk has helped you understand how to prepare your Postgres database to grow with your application, and the principles of effective scaling.
00:25:08.230
Thank you all once again, and I'm happy to take some questions.