00:00:12.639
Hello, everyone. Today, I'm going to talk about processing streaming data with Kafka.
00:00:17.680
First, let me tell you a bit about myself. My name is Thijs Cadier, and I work at AppSignal.
00:00:23.519
Just to clarify, my name is pronounced this way—it’s a bit of a tutorial on that.
00:00:29.519
I’m from Amsterdam in the Netherlands, and coincidentally, today is the biggest holiday of the year.
00:00:34.600
Amsterdam looks quite festive today, but I'm here with you instead of at the celebration.
00:00:41.680
I appreciate you all being here. At AppSignal, we develop a monitoring product for Ruby and Elixir applications.
00:00:47.840
As with many such products, you often start with the assumption that it won’t be too hard.
00:00:58.199
However, it usually turns out to be quite challenging. A critical consideration for our product is that we need to process a significant amount of streaming data.
00:01:04.559
Essentially, our product operates with an agent that users install on their servers.
00:01:12.200
This agent runs on various customer machines, posting data to us regularly, including errors and slowdowns.
00:01:19.320
We process and merge this data to create a user interface and perform alerting, which falls under the category of streaming data.
00:01:26.079
Streaming data is typically defined as being generated continuously at regular intervals.
00:01:31.119
It comes from multiple data sources that all send it simultaneously.
00:01:37.520
There are classical problems associated with this type of data processing.
00:01:42.560
One obvious issue is database locking. If you perform numerous small updates, the database locks most of the time.
00:01:48.640
Consequently, everything slows down. You need to load balance this data effectively.
00:01:55.680
The goal is to ensure that data ends up with the same worker server whenever possible, enabling smarter processing.
00:02:04.920
Now, let’s explore a simple streaming data challenge we can discuss as a use case.
00:02:11.039
Imagine a popular website with visitors worldwide, supported by servers distributed across the globe to handle this traffic.
00:02:22.720
We want to process the log files generated by these visits.
00:02:29.080
We have a continuous stream of log lines that contain each visitor's IP address and the URLs they visit.
00:02:36.079
For our purposes, we want to turn these logs into a graph tracking visits from different countries.
00:02:41.680
Is this a complicated task? The answer is, at a small scale, it’s not difficult.
00:02:47.920
You can simply update a database record for every single log line.
00:02:54.200
This straightforward approach requires you to use an update query on a country table, which includes a country code and a count field.
00:03:01.720
Every time you receive a visitor from a particular country, you update the relevant record.
00:03:07.360
However, the problem arises with maintaining data integrity in the database.
00:03:12.200
The database needs to handle the possibility that existing data might need to be updated as new log lines come in.
00:03:19.040
This requires locking rows, which can lead to the entire database locking down under heavy load.
00:03:26.320
At AppSignal, we faced this bottleneck several times.
00:03:32.800
One possible solution is sharding the data.
00:03:39.080
You could put all the Dutch visitors in one database and US visitors in another, thereby scaling out by grouping data.
00:03:46.959
While this can be effective, it introduces complications.
00:03:53.680
For example, querying data across different database clusters can become slow and complicated.
00:03:59.920
Additionally, if you decide to adjust how you shard the data—for instance, to count by browser—you’ll have to rewrite significant portions of your system.
00:04:06.160
This process can be cumbersome, involving extensive migration scripts.
00:04:12.680
At AppSignal, we also need to perform more extensive processing than simple counting.
00:04:18.760
This means we face bottlenecks not just in the database but also in the pre-database processing stage.
00:04:25.760
We had envisioned a scenario where a worker server would collect traffic from customers and then transmit that to a database cluster.
00:04:32.800
However, this model presents a major issue: if a worker server dies, the customer loses valuable reporting time.
00:04:39.760
So, we could introduce a load balancer that distributes traffic evenly across worker nodes.
00:04:46.080
While this works better, the risk still remains that a worker won't have the relevant customer’s data available for processing.
00:04:55.200
This fragmentation hinders our ability to perform effective processing.
00:05:01.760
It would be much simpler if all the data from one customer were processed by a single worker.
00:05:06.920
This would enable more efficient calculations.
00:05:13.440
For instance, instead of incrementing the visitor counter every time a log line arrives, we could cache those locally.
00:05:21.480
Then, after a short interval, we could perform a single batch update, significantly reducing the database load.
00:05:27.760
Our goal is to batch streams, implement caching, and perform local computations before writing to the database.
00:05:34.320
This caching is also vital for performing statistical analyses, like histograms, which require all relevant data to be together.
00:05:42.080
Thus, we return to our original scenario: routing all customer data to a single worker.
00:05:49.200
If we can accomplish that batching, we may not need the heavy sharding we initially considered.
00:05:55.840
However, we would still face the single point of failure issue, which could affect customer satisfaction.
00:06:03.000
This is where Kafka comes into play.
00:06:09.759
We explored various systems, and Kafka offers unique properties that allow for routing and failover effectively.
00:06:16.240
Using Kafka makes it possible to load balance and route data without too much complexity.
00:06:23.760
Now, let me explain Kafka by outlining four key concepts that are essential for understanding its framework.
00:06:29.760
Bear with me as we delve into these concepts.
00:06:37.759
First, we have the topic, which serves as a grouping mechanism for data, similar to a database table. A topic contains a stream of data that could range from log lines to JSON objects.
00:06:50.720
Messages within a topic are partitioned—in this case, they may be split into 16 different partitions.
00:06:57.239
The fascinating aspect is how data can be partitioned: a message with the same key will always reside in the same partition.
00:07:03.840
Next is the broker, which is the term Kafka uses for its servers.
00:07:09.120
The broker stores the messages and ensures they reach the final component: the consumer.
00:07:17.120
A consumer in Kafka is similar to a client or database driver—it allows you to read messages from a topic.
00:07:23.160
Kafka does have its own terminology, which can sometimes be confusing, as many of its components already exist under different names.
00:07:29.200
I’ll explain each of these concepts in more detail.
00:07:37.760
This is what a topic looks like: a specific topic can have multiple partitions, each containing a stream of messages.
00:07:44.960
Each message has an offset that starts at zero and increments with new incoming data.
00:07:51.360
You can also configure how long the data remains available in the topic.
00:07:57.520
When we group messages by country, they will end up on the same partition—all key-related messages are efficiently handled.
00:08:07.000
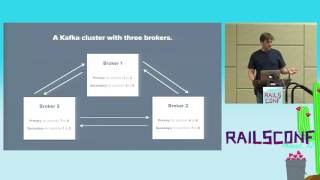
Next is the broker, which essentially stores the partitions and messages.
00:08:15.680
Each broker is a primary for some partitions and secondary for others, providing redundancy.
00:08:22.480
For example, with three brokers, each one can take a share of the primary tasks.
00:08:29.680
If one broker experiences failure, the others can take over its tasks without losing data.
00:08:36.080
Thus, this system provides excellent redundancy and reliability.
00:08:44.000
Finally, regarding consumers: a consumer in Kafka resembles a database or Redis client.
00:08:52.560
It allows you to listen to a topic, and Kafka supports multiple consumers, each tracking their own message offset.
00:08:59.680
For example, imagine we have two consumers, one handling Slack notifications and another managing email alerts.
00:09:06.960
If Slack is down while the email consumer runs smoothly, the email alerts will proceed without any issue.
00:09:13.920
When Slack becomes operational again, its consumer will catch up with the missed messages.
00:09:21.000
This architecture enables robust external system integration without one service disrupting others.
00:09:27.760
In cases where we have more partitions, a consumer group can facilitate parallel processing.
00:09:35.760
Kafka intelligently assigns partitions to consumers within the same group, ensuring effective load distribution.
00:09:44.000
If a consumer goes offline, the system redistributes the workload to maintain seamless operations.
00:09:51.760
Now, let’s shift gears and discuss how we can harness this from a Ruby perspective.
00:09:58.040
The relationship between brokers and consumers involves how consumers read data from partitioned topics.
00:10:05.760
From the consumer's view, Kafka handles data fetching transparently, alleviating direct concerns about data storage.
00:10:12.639
We’re planning to build an analytics system using the logs, tracking the number of visitors from various regions.
00:10:20.200
We’ll utilize two Kafka topics and three Rake tasks for this process.
00:10:27.760
Our end goal is a straightforward Active Record model tracking visitor counts.
00:10:35.960
The model will contain fields for the country code and visit count, alongside a hash to store cumulative counts.
00:10:43.840
During processing, we’ll loop through the hash, fetch or create entries for missing countries, and increment their counts.
00:10:51.679
The whole architecture involves importing logs to a Kafka topic, running preprocessing, and aggregating the data.
00:11:00.080
You might wonder why preprocessing is necessary. Immediate routes to the database can overwhelm individual server workloads.
00:11:07.679
Many visitors often come from a single location, leading to significant disparities in worker loads.
00:11:15.120
This uneven distribution can be costly and create processing inefficiencies.
00:11:22.760
Thus, we process some data before aggregating it to maintain overall efficiency.
00:11:30.600
Step one involves importing log files, which might not represent true streaming data.
00:11:37.760
In reality, the logs would have been streaming continuously from web servers.
00:11:45.200
The import task loops through log files, converting each line into a Kafka message, simulating streaming behavior.
00:11:55.680
For example, the message delivery in our code calls for sending each log line to the page views topic.
00:12:03.680
After this, the second step involves preprocessing the incoming data, especially determining each IP's country.
00:12:11.920
We set up a consumer that reads data from the previous topic, parsing it into manageable components.
00:12:19.520
In this step, we create hashes with attributes like country and browser for further processing.
00:12:26.120
The processed output is then sent to a second Kafka topic in a well-formatted JSON structure.
00:12:34.560
Line 51 holds the key detail: we assign a partition key, which will group data for future aggregation.
00:12:41.840
By ensuring that messages with the same country code end up in the same partition, we facilitate efficient calculations.
00:12:49.760
Now, we reach the final step, where we consume the data from the second topic and engage in aggregation.
00:12:56.400
The aggregation task consumes nicely structured JSON hashes.
00:13:03.600
We have a Ruby hash called @country_counts initialized to zero for all country keys.
00:13:12.720
For each message we process, we extract relevant data points and increment our aggregate counts.
00:13:19.679
The main loop runs every five seconds, calling the Active Record model to save current counts in the database.
00:13:26.760
After performing this, we reset the count for the next aggregation period.
00:13:33.080
This aggregation task continuously reads data for five seconds, incrementing counts each time.
00:13:42.240
Finally, it writes the current counts to the database, preparing for the next cycle.
00:13:50.080
We return to our UI to monitor the updated visitor statistics.
00:13:56.560
In the controller, we fetch and display visitor stats, ordered by descending count.
00:14:04.160
We also compute the maximum and sum of counts to ensure UI reliability.
00:14:11.280
At the front end, we create a straightforward HTML table to showcase our data.
00:14:18.560
This design illustrates how we can use Kafka to efficiently process incoming data streams and display results.
00:14:26.320
Now, let’s move on to the demo of our application.
00:14:34.560
I've set up three tabs for demonstration.
00:14:41.760
The importer simulates continuous log line streaming into a Kafka topic.
00:14:49.760
Next, we run the pre-processor to transform these logs into actionable JSON data.
00:14:57.760
As you can see, we are successfully processing logs into structured JSON.
00:15:05.760
We can even add a second pre-processor to handle more partitions, enhancing our overall capacity.
00:15:13.760
Simultaneously, we’ll initiate the aggregator to manage incoming data and produce statistics.
00:15:21.760
As we refresh the output tab, you'll notice visitor counts updating every five seconds.
00:15:28.960
Each time the aggregation runs, we observe a cumulative increase related to incoming logs.
00:15:36.960
Moreover, by launching a second aggregator, we can see how Kafka reallocates partitions effectively.
00:15:44.960
As a result, you will notice some counts in one tab decrease as Kafka redistributes workload.
00:15:52.360
This efficiency demonstrates Kafka's ability to manage and balance data across multiple workers.
00:16:00.080
That concludes my presentation on processing streaming data using Kafka. Thank you!
00:16:14.000
I welcome any questions about the presentation.
00:16:22.680
A common query revolves around what occurs if a consumer goes down without committing offsets.
00:16:30.760
In my talk, I chose not to complicate matters by discussing this, but it’s important to note.
00:16:37.440
Consumers decide when to notify Kafka that they’ve processed messages, allowing for potential rewinds.
00:16:45.120
If a consumer pauses on an uncommitted offset, it can reprocess messages upon recovery.
00:16:53.360
Because we flush data when committing, they tend to be in sync.
00:17:01.760
Another question often raised concerns formatting restrictions for messages in Kafka.
00:17:09.760
The answer is, there are no inherent restrictions; each message comprises a key and a value.
00:17:16.560
We frequently utilize Protocol Buffers in our Kafka topics, but JSON or alternative formats are equally viable.
00:17:24.600
While Kafka provides robust capabilities, running it entails a learning curve, especially surrounding Java components.
00:17:32.600
If you're interested in avoiding these complexities, options like AWS Kinesis are available.
00:17:39.680
Thank you for your attention, and feel free to share any additional questions you might have!