00:00:05.040
Howdy, and welcome to 'Rails DB Migrate: Even Safer,' also known as 'Safe Database Migrations 2: Electric Boogaloo.'
00:00:11.340
Today, we're going to discuss how to make schema changes to your large relational database without taking down your Rails app or causing any outages or performance impacts for your customers.
00:00:30.480
Before we dive in, a little background about myself: My name is Matt Duszynski. You can find me online on Twitter at BSDzunk, on GitHub as dzunk, and I have a personal website, which is a domain hack of my own name, though it doesn't have much content right now. Perhaps that'll change by the time you watch this video; a person can only dream.
00:01:06.900
Currently, I work at Weedmaps, possibly the greenest tech company around these days, and I’m originally from Houston, Texas. I managed to escape the city before all the sports teams I loved and grew up watching experienced what felt like an entire collapse. But let's get back to the topic at hand.
00:01:47.040
Today, we're covering some advanced changes that you may need to implement in your database a few years down the line. Your Rails app has likely grown successfully, accumulated a lot of data, added many new features, and possibly incurred some technical debt along the way.
00:02:10.200
Specifically, we will discuss five things: safely adding and removing columns, changing a column's type, adding constraints to existing columns, and finally, we will end with a case study of replacing an entire table while the application is running.
00:02:15.420
Before we get into the meat of the discussion, let's cover a little housekeeping. I hope you are aware that this talk primarily focuses on relational databases.
00:02:30.480
If you’re using MongoDB, you may find yourself having a tough time. I should also mention that we use PostgreSQL as our primary data store at Weedmaps, so I have the most experience with that. Most of this talk will utilize PostgreSQL-specific terminology. However, that doesn’t mean the concepts won’t translate—if you’re using MySQL, be prepared to do a little extra work.
00:03:32.340
Finally, this talk builds on concepts I covered in a previous RailsConf 2019 talk titled 'Rails DB Migrate Safely.' If you haven't seen it or aren’t familiar with these concepts or why migrations can be dangerous at scale, I encourage you to pause this video and check out that talk. It covers some basics we won't delve into here.
00:03:57.540
We can take a moment now to reminisce about the bygone era of 2019, a time when we could see people in person—good times indeed.
00:04:18.360
The main concepts I covered in the original talk are locks, transactions, and concurrency. Understanding why these migrations are dangerous and the need to exercise special care when executing them requires knowledge of the ACID properties of database transactions: Atomicity, Consistency, Isolation, and Durability. Your relational database engine uses locks to guarantee these properties across multiple connections and operations, particularly during migrations. When schema changes are underway, various lock modes come into play, ranging from access share, which allows other operations to access the row or table in question, to access exclusive, which prohibits any other connection from performing operations, including reads.
00:05:41.880
For example, MySQL ranges them from a 'SELECT FOR SHARE' to a 'LOCK TABLES.' Access share and access exclusive are the PostgreSQL terms. There are also other more granular locking modes, but they're less relevant; however, we will discuss one in particular later in this talk. Just be aware that these modes exist and how they control access across the spectrum.
00:06:07.800
Most importantly, you must understand why these migrations can be risky. Any temporary performance impact in a high-throughput system can trigger a cascading effect, ultimately bringing your entire application down. If your database winds up waiting, it won't answer queries from your Rails app, which must then wait for the database to server their requests. This situation can result in bottlenecks and potentially a complete denial of service. Now that we have that background, let's start with our first subject: removing a column.
00:06:41.880
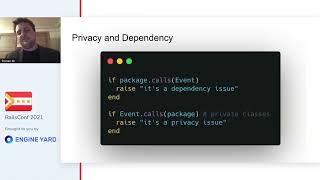
As a bonus, we’ll also cover both of the hardest problems in computer science during this talk: cache invalidation and naming things.
00:06:55.680
For our first example, let’s consider removing the 'name' column from our users table. Perhaps we've replaced it with split fields, like 'family name' and 'given name.' Alternatively, we could decide that identifying our users solely by number is better.
00:07:08.820
However, if you run this migration as it stands, you might see something like this in your error tracker. So, what’s happening? Much of the magic associated with Rails comes from Active Record. When you boot your Rails application, Active Record queries the database to get the current state of the schema for all relevant tables. This process informs it about the attributes present in your model, their types, default values, and how to instantiate the meta-programming that makes your Active Record models function properly.
00:07:43.980
Underneath that Active Record ORM layer, it ultimately builds raw SQL queries to execute actual database operations. So, not only do the models instantiate with attributes based on the schema, but Active Record also controls how the insert and update statements are constructed during changes. When removing a column, the column may be deleted from the database, yet it remains present in the schema that was loaded at boot, since Active Record doesn't automatically reload it after the migration. Consequently, the insert and update queries still refer to a column that no longer exists.
00:08:51.240
Fortunately, this problem is quite simple to fix. Instead of simply removing the column, we first define it as an ignored column on the model using the built-in ignored column setting. We can ignore the 'name' column, deploy that change to production, and then safely remove the column as we discussed earlier.
00:09:28.440
Before proceeding, I want to highlight the importance of deploying these changes to production separately. Most changes we discuss today, including this one, require a specific sequence of deployments to ensure that no old code is running, which may depend on outdated columns or schemas.
00:09:55.020
I will not outline each deployment specifically as that will vary based on your application. Are you multi-region? Are you running in Kubernetes, as many are nowadays? Regardless, I want to emphasize that each step of safely making these migrations often requires a separate production deployment.
00:10:09.240
Also, don’t forget to ignore columns before you remove them. In large applications with many developers and modules, you might need to remove multiple columns simultaneously. Continuing our 'name' example, the authentication team might also remove an old password hash from the user model.
00:10:49.560
However, these ignored column settings do not stack; only the last executed line for setting ignored columns will apply at runtime. So, because 'authorizable' is included first, and then 'ignored_columns' set in the model, only the 'name' column can be safely removed. Attempting to also remove the old password hash will yield those familiar Active Record statement invalid errors noted earlier.
00:11:04.920
Much of the knowledge shared is gathered through the School of Hard Knocks. To avoid the issue entirely, I recommend ignoring columns at the model level only. This same problem may occur if you have a class hierarchy with abstract classes where ignored column definitions at multiple levels can overlap, leading you to ignore fewer columns than expected.
00:11:27.600
So, while our approach may appear a bit backward, now that we’ve figured out how to safely remove a column, let’s discuss adding a column and prepared statements and how these two may conflict. For the purpose of this example, we will use the 'active' boolean in our users table.”},{