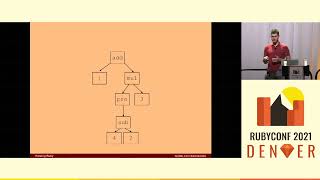
00:00:11.280
My name is Chelsea Troy. I'll talk a little more about myself later, but you're in the workshop titled "Tackling Technical Debt: An Analytical Approach." If you're looking for the joint cognitive systems workshop, that's across the hall.
00:00:16.880
I won't be discussing that, but let's go ahead and get started.
00:00:29.599
The first thing to know about this workshop is that we're going to cover a lot. I see a 99-minute timer in front of me; the schedule said two hours. I will take the entire two hours, however, it is going to be relatively fast-paced. Hopefully, you'll learn a lot.
00:00:36.320
If I do not get to a question that you have, which may happen, please feel free to post it in the Discord channel. I will be checking that after the workshop and throughout the weekend.
00:00:49.360
Posting in that channel has the added benefit that other people will see your question and answer as well. So, if we run out of time for questions, and you still have a question in mind, do not worry; we will definitely get to those.
00:01:02.000
Feel free to post questions during the workshop, and I will check them afterward. The link for the channel is in the slide, which you should all have.
00:01:12.640
Currently, there are plans to turn this into a slightly longer version of a workshop for Graceful Dev, which is a project that AVD Grimm is doing. I will be very interested to hear your feedback on this workshop to determine what we should expand upon.
00:01:29.360
Finally, if you are a Twitter user, there are three handles you can include in your tweet. One is, of course, the RubyConf handle, one is my handle, and then one is the handle of my lovely assistant, Leah Miller.
00:01:41.200
So, I guess that's about it for this slide. So, let’s get started. As mentioned, Leah will be assisting throughout this workshop. We'll be asking all of you for your input at various points, and it’s important that your comments go into the mic for accessibility reasons.
00:02:06.159
Leah will bring you the mic, so if I ask you to raise your hand, Leah will choose who gets the mic. If we only have one or two people raising hands, just wait until you have the mic so that we can all hear your beautiful voice as you explain your question or share your story.
00:02:34.560
This is a picture of me, taken in my home city of Chicago. You can almost see the Sears Tower right behind my head; we don't call it the Willis Tower.
00:02:50.800
So, if you ever come to Chicago and you hear that, don’t subscribe to that.
00:03:00.640
Okay, so let’s get started.
00:03:02.400
What is technical debt? I think there are a couple of misconceptions about what technical debt is, so I want to address those quickly.
00:03:08.959
We all have an idea of what it looks like. I suspect you all have an idea of what it feels like. Hands up if you know what tech debt feels like. Okay, that's a lot of the room.
00:03:21.440
The first misconception that I want to dispel is that tech debt is tantamount to bad code.
00:03:27.920
This misconception is harmful when we're trying to talk about the state of our codebase. It causes us to equate the developers that came before us with bad development, which is usually not the case.
00:03:40.159
There are a lot fewer really terrible engineers than there are good engineers who had to do something under constraints that we do not understand, causing the code to be the way it is now.
00:03:52.799
The practical reason that equating tech debt with bad code is an issue is that it puts us under the impression that if we write good code, then we are not adding maintenance load to our codebase, which is not true.
00:04:05.360
We will talk about maintenance load a little later.
00:04:11.840
The second misconception about tech debt is that once you build a feature, it is free. Once we have built it, once it is shipped, once it is working, we do not have to worry about that feature anymore; we don’t have to consider it when we write further code.
00:04:22.639
That is not the case. For features, we pay rent. We have to perform maintenance on those features. This is where the term "maintenance load" comes in that I mentioned earlier.
00:04:39.440
I like to define technical debt in terms of two concepts, which we are going to discuss. The first of them is maintenance load. Maintenance load is the proportion of total developer effort spent maintaining the existing feature set.
00:04:51.600
For example, if you have one developer who spends four out of five days working on features and other tickets related to maintaining the codebase, then the maintenance load is 80%.
00:05:02.160
Some examples of what might count as maintenance load could be updating, up-versioning, or investigating existing code. Hands up if you've done something like this? Congratulations, you have engaged in maintenance load.
00:05:20.639
Determining whether a given feature ever worked is maintenance load. Anyone done this? You’ve done maintenance load. Did you figure it out? Sometimes I haven't.
00:05:31.919
Adjusting deployments so that existing functionality will scale is another maintenance load example. Have folks done this? Few hands, yeah, you’ve done maintenance load too.
00:05:42.639
The heuristic I use to determine what counts as maintenance load is this: any developer activity that is not adding or removing a feature counts as maintenance load.
00:05:57.600
Now, we could get into depth about what a feature is, but we're not going to do that for now. Take your definition of a feature; if you're not adding one or removing one, everything else you're doing counts as maintenance load for the purposes of this workshop.
00:06:21.120
The other concept that we need to know when defining technical debt the way I do is context loss.
00:06:28.160
This is often a key reason we end up doing this kind of work. Frequently, I have encountered codebases where I was told that there was a lot of technical debt.
00:06:40.400
Particularly earlier in my career, I would equate that with bad code and think that it was convoluted or something like that.
00:06:53.599
Sometimes, I was told this was the way things were, then I would get into that codebase and realize that the code isn't that bad; it’s just that nobody here knows how it works.
00:07:09.680
That's context loss—it’s missing information about how, whether, or why part of the codebase existed or worked. It has very little to do with the quality or functionality of the code itself.
00:07:23.680
It has everything to do with how context was shared or stored among the remaining team members. Context loss can occur in several ways.
00:07:38.720
For example, if something wasn't documented and the team forgot, that's context loss. Hands up if this has happened to you? Huge source of context loss right there.
00:07:47.680
This is why churn events are so risky technically; they drive your maintenance load way up, usually.
00:08:00.000
Another example might be that the code becomes so complicated that even the original author isn't sure what's going on anymore. Hands up if this has happened to you? My hand is up.
00:08:13.120
This can happen with such speed; I teach computer science students that this can happen as fast as four or six weeks if it’s something sufficiently complex.
00:08:28.000
So, that is context loss. Now, we’ve got maintenance load; we’ve got context loss. We're ready to talk about what technical debt is.
00:08:41.120
Tech debt is the maintenance load in the existing codebase that comes from context loss. That’s what it is, and that’s what it means.
00:08:56.800
So, how do we quantify that? We can quantify that in terms of how much of our developer time and effort is getting spent.
00:09:10.160
Fantastic! How do you know if your maintenance load is under control right now? We talked about numbers, but you're all in this room and you didn’t know that definition or that numeric quantification before we got in this room.
00:09:24.720
So you must know somehow. What are some of the signs that your maintenance load is not under control? They might include agreements with products to take on tech debt to deliver a feature like: “Hey, this boat’s got to get from here to there. Do you mind taking on a little water just until we get there? Promises that we’ll let you bail it out once we get there?” So, maintenance load is not under control.
00:09:55.320
Another example could be when the team accepts that there are some features that just don’t work. Show of hands? You all have this going on, couple hands raised. It could be that support teams have been told, "Yep, these buttons don’t work. Just tell them to do it manually; we’ll work around it." So, maintenance load is not under control because we can't maintain the corpus of features that we're committed to maintaining according to our user interface.
00:10:29.599
Another example might be that there are repositories or features that the whole team avoids. Has anyone had this experience? A repo nobody wants to go into, a legacy API nobody wants to touch. Yeah, a lot of noses go up. Anything where the entire team at stand-up is like "nose goes" is an abandoned house; these are signs that your maintenance load is not in fact under control.
00:10:49.920
So now I've got an individual question for you. Each of you will answer this individually.
00:11:06.640
The link on the screen leads to a Google Doc, and I encourage everyone to type your responses in there because it'd be interesting if everyone can see everyone’s responses.
00:11:27.360
The first question is, what is your worst maintenance load horror story? What is your worst maintenance load horror story?
00:11:52.240
And then how about the opposite situation, where things were smooth and easy to maintain?
00:12:02.560
I’ll give you a couple of minutes to type something into that doc.
00:12:10.880
Would anyone feel comfortable sharing their answers to this question? Raise your hand if so.
00:12:25.440
Leah will bring the mic to you. We've got a couple over on the rail here by the doors.
00:12:50.720
So, we have a legacy server that nobody knows how to maintain, with legacy code that no one codes anymore, but we somehow have to keep running.
00:12:58.560
Sounds like fun!
00:13:03.840
If you spell "fun" with a PH.
00:13:12.480
Anyone else willing to share?
00:13:21.760
We've got one over here: years ago, I worked in a support department for internet banking.
00:13:28.480
We did a professional service contract for a client, took them live on a new copy of their internet banking site. Four months in, they reported that a few users weren't receiving some alerts.
00:13:40.960
I discovered that that alert had never fired in the four months they'd been live.
00:13:51.680
Awesome, it never worked!
00:13:58.160
Alright, maybe we can do one more.
00:14:02.960
Do I see anybody else? Show of hands?
00:14:07.280
It looks like you've got someone.
00:14:15.040
A team was underwater with on-call responsibilities, so they added a second person to on-call.
00:14:37.760
I have a couple myself. I work on one application; well, that’s not a fair characterization. I work on a couple of different applications.
00:14:48.160
As we discussed, a developer built the application and then left for various reasons, and the company has been using it for a while.
00:14:58.799
A lot of interesting stuff happens in those codebases, but they’re fun to learn to spelunk.
00:15:09.760
Okay, now I have another individual question for you. This one I’m going to give you five minutes for.
00:15:17.760
What practices distinguish your maintenance load horror stories from good stories?
00:15:28.240
Now, here's what I mean by that: what is your team doing during the horror stories?
00:15:36.160
What is development like on the codebase during the horror stories versus what is development like on the codebase where you have a smooth experience?
00:15:48.120
What are the differences? Some of these differences might not necessarily be programming practices. It could be the age of the codebase.
00:16:01.680
One might be ten years old while another may be six months old; that's a big difference! Or the differences might be the size of the team.
00:16:14.720
But there are also generally practices, such as the way that the team approaches documentation, testing, and even meetings.
00:16:22.239
So, I'd like you to write down somewhere on your own computer. We will use these later.
00:16:34.720
Think about your horror story and the opposite, and ask yourself what practices distinguish those two teams.
00:16:41.920
Make a little list—we will use this list later, so actually do the exercise.
00:16:48.480
Now that you've got your list, we’ll call that our cliffhanger for part one of the workshop; we are going to come back to those.
00:16:55.920
So, now we know what maintenance load is, let's talk about why it rises.
00:17:01.840
There's another critical concept here, which I call code stewardship.
00:17:08.880
I’m not entirely positive that I like the term code stewardship, so if you have a better idea for what to call this after we talk about it, feel free to tweet it to me because I am taking submissions.
00:17:21.600
But for now, we’re going to call it code stewardship, which specifically refers to the skill of reducing maintenance load.
00:17:30.880
I want to be clear: we cannot eliminate maintenance load unless we eliminate all of the code since we have to maintain the system. However, this is the skill set for reducing maintenance load.
00:17:44.800
It’s a skill set that we generally do not tend to incentivize or prioritize in programming education or in professional programming environments.
00:17:50.879
The places that do prioritize this are anomalies.
00:17:58.320
Let me give you five examples here.
00:18:03.520
It includes writing discoverable code. By this, I mean writing code that someone who has not seen this code before will be able to use the code itself as an artifact to understand what the system is supposed to do.
00:18:22.799
That's discoverable code.
00:18:28.400
Another example might be writing code with malleability and rigidity in the right places. I want to explain what I mean by this, because we often say that we want to keep our code flexible.
00:18:48.480
We want to keep our code flexible. But what are some other things we want to do with our code? People are familiar with DRY: Don't Repeat Yourself, right? So we want DRY code, but we also want flexible code.
00:19:05.040
Suppose we dry up some code from two different places and then we find out that one of the places needs to change. Is it easy to change relative to the way it used to be? No.
00:19:18.080
When we dry up code, we trade malleability for the conciseness of that code. We make it more rigid because we are trying to get some other things done. We are making a bet.
00:19:30.240
We are making a bet that if we want to change this thing, it means we want to change it everywhere. If that bet turns out to be wrong, our code is not malleable in the ways that it needs to be.
00:19:48.720
Now, I want to offer some grace here: it is very difficult to make code malleable everywhere. I’m not sure it’s possible to make code malleable everywhere, or if you were to do it, you would likely have to give up other things.
00:20:01.600
You would have to give up dryness, for example, because every single instance of a place where you do something needs its own copy of the code for it to be independently changeable.
00:20:14.080
That also means that if you do want to change something everywhere, now it is difficult. That malleability isn't in the right place.
00:20:22.720
It’s very hard to make the code malleable everywhere—I’d say almost impossible. So we have to figure out what is most likely to change in our code in the future and we have to place our malleability in the places where it is most likely to change.
00:20:38.720
The trade-off will be that we’ll make the code more rigid in places where it is less likely to change, but those rigid areas are supporting the malleable portions of the codebase.
00:20:55.839
We are putting our malleability and our rigidity in the right places because if we try to make code flexible everywhere, it usually ends up being flexible nowhere.
00:21:06.480
Another example of code stewardship might be documenting code with detail in the right places.
00:21:18.480
Show of hands: who’s read documentation that did not help you figure out how to use the library you were trying? Yeah, it’s most of it. And it’s not entirely the programming team's fault.
00:21:37.360
Code stewardship, like I said, is a set of skills that we tend to undervalue, under-incentivize, and under-teach, and that comes with documentation, too.
00:21:55.760
We ask programmers to be good writers, indexers, and teachers. That’s a separate skill set and it can be hard since writing is difficult.
00:22:04.560
When we ask programmers to do that on the side of their programming job, a lot of documentation ends up not being what we want it to be.
00:22:16.960
Here's another example: writing tests that convey code functionality and boundaries. Tests are really valuable for several reasons.
00:22:31.120
Automated tests can help us catch regressions in our codebase. If we accidentally break something, they can give us the confidence to make changes, even significant ones, without worrying that we’ve introduced regressions.
00:22:46.240
Tests can also serve as living documentation for our code. If code is frequently going to change, it’s helpful to have documentation that either deletes itself or tells us that it has become invalid when the code changes.
00:23:02.560
Tests are precisely that; when I get into a new codebase that's well tested, I like to use those tests as a laboratory to understand what the code does.
00:23:17.760
I can change things in the test and figure out what's going to break and how it’s going to break. I can understand what people expected my code to do.
00:23:25.040
A lot of times I can even tell how this code has broken before, because there’s an automated test that indicates a failure.
00:23:34.080
That’s valuable information too.
00:23:40.000
Here’s another example: transferring context to other members of the team. This is a very valuable code stewardship skill.
00:23:54.320
If somebody leaves, they take a lot of context with them. I want to say that the smaller the team working on an individual unit is, the more deliberate we have to be about this.
00:24:09.440
Picture context for now as a giant beach ball. If I throw it towards you, do you think it's likely to hit the floor? I don't think it's that likely to hit the floor because there are a lot of you and you're pretty close together.
00:24:18.080
So it's probably not going to hit the floor. Now, suppose that I was in here and there were five of you scattered around the tables, not closely working together. If I threw that beach ball, there's a good chance it would hit the floor.
00:24:36.720
If somebody is not available, they have to hand that beach ball off to somebody else. That's context transfer.
00:24:45.440
We can do it through pull request reviews, documentation, testing, artifacts, and many other means.
00:24:59.920
Now, I'm going to give you an individual exercise, and this is where we come back to the list I had you write earlier.
00:25:09.679
Earlier, you considered what practices distinguished high and low maintenance load accumulation on teams over time: horror story codebase and smooth and easy codebase.
00:25:39.440
Now, I would like you to copy those examples one by one and paste them into this easy retro link under what kind of example it falls.
00:25:52.240
What I want to know is whether those practices you listed fall under any of the five examples we just discussed of code stewardship. If so, copy them and paste them into that column.
00:26:03.920
If you have a practice that does not fall under any of those five examples, place it in the sixth column for other examples of code stewardship.
00:26:16.960
I will give you a couple of minutes to do that. If anyone has trouble accessing the easy retro, just raise your hand and we’ll come and help.
00:26:34.080
We are experimenting with methods here; this is my first time doing a workshop of this size in person.
00:26:44.720
I’ll give you a couple of minutes to copy and paste your stuff in there. Let me see if I can pull this up so you can see on the big screen.
00:26:55.680
This is the easy retro.
00:27:01.760
Oh, we got some stuff! We got some stuff!
00:27:08.960
Now I need that horse race music.
00:27:29.440
So, writing discoverable code: someone says it was a newer repo that was fairly small and narrow in scope.
00:27:39.619
The changes all followed the paradigms that were set up from the beginning, including the testing suite, making changes easy and safe. I like this.
00:27:46.640
One point I want to make is that for those newer codebases, you generally have a small enough number of features for a team to stay on top of it more easily than if you're talking about a ten-year-old codebase.
00:27:59.840
Favoring readability over terseness and cleverness is important in writing discoverable code. High cohesion and solid object-oriented design patterns are also characteristics to aspire to.
00:28:10.080
Another example is writing code with malleability and rigidity in the right places, avoiding premature abstraction.
00:28:21.440
I like that one. I give another talk about refactoring, and like to talk about the rule of three in that one. I don't generally consider consolidating until I have three instances of something.
00:28:34.480
I give another talk on this in detail because I do not trust my ability to predict with less empirical evidence than that what’s actually the same. I've messed it up too many times.
00:28:46.640
Let’s look at some more examples: heavy use of interfaces and private methods. Open discussions with product about possible ways the product will change.
00:29:02.960
This is super helpful! We'll talk more about talking with products a little bit later.
00:29:09.600
Good test coverage: testing suites are ignored because writing the tests was too difficult and time-consuming. That must have been one of those nightmare codebases.
00:29:21.680
Fast CI and frequent deployments: a small, tight feedback loop can be super useful from a pragmatic perspective, because if it is difficult or impossible to run your codebase frequently and easily, people won't do it.
00:29:34.080
And it’s not because they're trying to be naughty; it's because they can't get their work done if they continuously try.
00:29:47.920
Okay, documenting with detail in the right places, clear documentation written without assumptions about what the reader knows or can do.
00:30:01.360
Documentation that includes examples where similar changes were made can be very helpful. Sometimes a PR to follow is extremely useful.
00:30:12.640
For example, I work on a programming language called Roc. It's a functional programming language compiler written in Rust. We’re adding many built-ins to it.
00:30:27.040
These built-ins are things like finding the max, min, or index of an item in a list. When someone adds one of these built-ins, we can point them to a similar built-in, giving them a chance to see where we made a similar change.
00:30:40.480
That helps maintain a consistent architecture.
00:30:53.440
Documentation that focuses on the shape of data at key points in the flow is equally important. All features tied to a story or ticket, extensive documentation on both technical tasks and decisions made.
00:31:10.160
Adding a README in subfolders specific to the content inside the folder can be very helpful. When we are supposed to document more, the first instinct is to add more stuff to the README; eventually, that README gets to 6,000 words.
00:31:27.840
It's absolutely beautiful from an artistic perspective, but it's hard for devs to figure out what they’re looking for.
00:31:39.760
Transferring context to other members of the team is essential. This is a significant code stewardship skill.
00:31:46.800
If someone leaves with a whole bunch of context, I’d like you to picture context now as a giant beach ball. If I throw it toward you now, do you think it’s likely to hit the floor? I don’t think it’s that likely to hit the floor.
00:32:02.480
The reason is that there are a lot of you and you’re pretty close together, so it’s probably not going to hit the floor.
00:32:12.080
Now, suppose that I was in here with only five of you interspersed. If I throw that beach ball, there’s a good chance it’ll hit the floor.
00:32:24.640
If that person is not available, they will have to throw that beach ball to somebody else. That’s context transfer. We can do it through pull request reviews, documentation, testing, and other means.
00:32:39.760
Now I'm going to give you an individual exercise. This is where we go back to the list you wrote earlier. Earlier, you considered what practices distinguished high and low maintenance load accumulation on teams over time.
00:32:54.960
You should now take those examples and copy them and paste them into this easy retro link under the column of what kind of examples that they fall under.
00:33:09.040
What I want to know is if those practices you listed fall under any of the five examples we just discussed of code stewardship.
00:33:22.080
If so, you can copy them and paste them into that column. If you have any practice that does not fall under any of those five examples, I would like you to put them in the sixth column under other examples of code stewardship.
00:33:36.000
I’ll give you a couple of minutes for that. If anyone has trouble accessing the easy retro, please raise your hand and we will help you.
00:33:49.920
We are experimenting with methods; this is my first time doing a workshop of this size in person.
00:34:05.440
So, I’ll give you a couple of minutes to copy and paste your responses in there. Let me see if I can pull it up so you can see on the big screen.
00:34:17.680
Now we got some responses! We’ve got responses now.
00:34:30.880
So writing discoverable code: a person says this was a newer repo that was fairly small and narrow in scope.
00:34:41.520
The changes followed the paradigms that were set up from the beginning, including the testing suite, making changes easy and safe. I like this!
00:34:51.920
It underscores the importance of clear and simple design and maintenance.
00:35:01.920
I also appreciate the use of interfaces and private methods.
00:35:05.440
We had heavy use of interfaces that keep our design clean.
00:35:10.720
It's useful to have open discussions with product teams about possible changes that may come.
00:35:22.960
Good test coverage can help catch regressions and enable confident refactoring.
00:35:40.080
We also stress continuous documentation, ensuring that our tests serve as a living record of expected functionality.
00:35:50.560
Finally, maintaining open lines of communication between team members helps transfer critical context.
00:36:00.840
Collaborative knowledge sharing ensures that all members remain in sync.
00:36:10.080
I will now take questions; however, we are nearly out of time.
00:36:20.120
One thing I want to point out is that I have a feedback form for you.
00:36:28.640
I am very serious about improving my workshops, so I would appreciate it if you could answer those questions.
00:36:36.560
It’s going to help me make this workshop better and to expand it for the future.
00:36:49.520
There’s also an option to provide your email address if you’d like to hear about future expansions.
00:37:03.040
I really appreciate your time, and I'm happy to let you go for the day, or you can stick around for questions.