00:00:14.330
All right, so I'm going to talk about an idea I call "schema with SQL". This allows you to have all the advantages of a relational database while also incorporating some nice document features.
00:00:21.180
I'm Will Leinweber, and I'm probably best known for my amazing gem bundle, which installs Bundler when you install it. It's quite popular. I work at Heroku on the Postgres team, where we run numerous Postgres databases. I really like Postgres, and I want to share some of the cool things you can do with it.
00:00:27.270
To provide some context, I started out doing plain Active Record and building simple CRUD apps. That worked well for a while until I found CouchDB, which I fell in love with. It has great features like a nice HTTP RESTful interface and MapReduce capabilities, but what I loved most was the ability to store documents as regular objects in Ruby.
00:00:53.010
Using tables and maintaining a third-normalized form was often painful. My web applications didn't always deal with relational data; making many tables in pursuit of normalization just felt wrong to me at times. The last project I worked on involved a tool for artists to version their songs and present those versions to their fans. Each song had a title and pointers back to the artist, along with other metadata. Versions of the songs included details like changes between versions and the date created, along with a list of tracks.
00:01:35.440
While trying to model this in SQL, I faced a problem with the file part—justifying the presence of a files table didn’t seem logical since a file only made sense in context. Although I could have worked around this in SQL, my logic wasn't up to the task, so I used CouchDB, and it worked great.
00:01:58.569
Then I came to Heroku and began learning Postgres, which is a fantastic database that features multi-version concurrency control and phenomenal full-text search capabilities. The geolocation features and the latest version from Postgres includes K-nearest neighbors, allowing you to find the closest items on an index without sifting through many records.
00:02:06.110
Postgres also has built-in listen/notify features, and its various data types are incredibly robust. I could deliver an entire talk on the amazing features within Postgres. However, the aspect I missed greatly was transaction handling—being able to roll back changes. Now, whenever I face a daunting migration, I spin up a fork of my database and execute a migration to see if it works. If not, I can roll it back and keep trying until I get it right, which saves me substantial time.
00:02:44.350
However, I still missed the document model. I should say that I used to miss documents, but I don't anymore—and I'll explain why.
00:02:51.010
I found two features, Hstore and PLV8. One can be used today, while the other is still somewhat cutting-edge and not quite ready for production use. I’m excited about both. Let’s start with Hstore. Hstore provides a key-value column type within Postgres, which means you can have your standard table with one column designated as an Hstore document.
00:03:11.350
One fantastic aspect of Hstore is that you can create an index on it. How many of you in your applications have a generic serialized table where you treat a serialized column as an opaque object without being able to query it? Well, now you can actually query it!
00:03:40.970
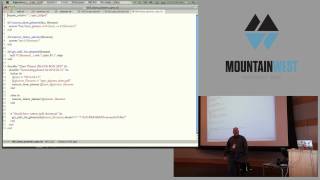
Let me show you how Hstore works. Here's an example query. It selects a string and casts it into an Hstore type. For example, if 'X' is 'A' and 'Y' is 'B', you can use the arrow operator to extract values from the Hstore. For instance, if you're asking for the 'A' key, it returns 'X'. Also, you can concatenate two Hstore objects, but be cautious because if keys overlap, the existing keys will be overwritten.
00:04:06.670
You can also subtract keys from an Hstore document; this works as long as the keys match specifically. Using this knowledge can lead to significant flexibility in how you handle your data.
00:04:42.950
There are many more operators available; for more details, the Postgres documentation is quite helpful. Another exciting feature is that you can utilize Hstore in a WHERE clause to select products based on certain attributes or conditions. For example, you can select all products that are red based on an Hstore attribute.
00:05:14.160
You can also perform updates. For instance, you could change all color attributes of products to blue and add new attributes if they do not exist. You can even join other tables based on Hstore attributes, so you have all the powerful features of SQL available while accessing serialized columns.
00:05:42.490
The standout feature is the ability to create an index! With a functional index, you can access specific keys quickly, which significantly enhances performance when querying. Hstore indices can greatly optimize how you interact with your semi-structured data.
00:06:07.290
Using a Postgres 9.1 database, all you need to do to integrate Hstore is create the extension, and you're set. Active Record now includes built-in support for Hstore, so you can utilize this feature seamlessly in your applications.
00:06:44.890
One of my colleagues demonstrated this capability through a live demo. You can check out that Hstore demo to see how it behaves in practice.
00:07:14.830
Next, I’d like to discuss PLV8, which embeds the V8 JavaScript engine into Postgres. For those unfamiliar, V8 is Google's JavaScript engine, which is also what Node.js uses. The benefits of PLV8 are substantial for those of us in the Ruby community, as it allows for the writing of trusted JavaScript code within Postgres.
00:08:09.970
Installing PLV8 is straightforward. You can build it from source, and once installed, it enables the use of JavaScript inside your database functions. This is particularly exciting for creating functions that handle complex operations or data transformations.
00:08:56.379
To demonstrate, I want to present a simple Fibonacci function implemented in PLV8. The approach of using JavaScript to perform calculations can greatly improve execution speed compared to using traditional procedural SQL. The ability to leverage JavaScript alongside SQL presents a powerful combination for developers.
00:09:28.550
While PLV8 might be experimental, it opens up opportunities for optimizing Postgres functionality and enhancing application performance. The community is vibrant and maintaining these enhancements contributors can positively impact how we use databases.
00:09:47.799
As we continue, I'd like to showcase how JavaScript can be specified in SQL. Here’s an example where you can create a JavaScript function that interacts with JSON data stored in your database. Storing data in JSON format can be beneficial for flexible data structures.
00:10:37.799
In conclusion, utilizing features like Hstore and PLV8 can revolutionize how we handle data in relational databases, allowing us to benefit from great flexibility and powerful performance. The importance of combining these document-like features with well-defined schemas in Postgres can't be overstated.
00:11:23.650
I encourage everyone here to explore these options and think critically about where your data exists and how best to utilize it. There are ample opportunities in considering the locality of your data and optimizing your data layer accordingly.
00:11:46.470
Thank you for your time, and I'm happy to answer any questions!