00:00:10.719
All right.
00:00:12.000
Hello everyone.
00:00:15.280
Our applications live in complex systems with points of failure that span space and time.
00:00:20.960
As developers, we write code that is executed in systems that we rarely fully understand. It would be a poor use of our time to try to anticipate all the ways in which our code can fail.
00:00:30.800
The errors that our code raises give us feedback on the code paths that have certain assumptions baked into them, which require us to re-examine our understanding.
00:00:40.399
It's our superpower to make reasonable assumptions, let our tests guide us, and allow our systems to tell us how and where they are breaking down, rather than trying to predict those failures.
00:00:57.280
This also means that sometimes we must put on our gear, step into our spaceships, and identify which issues will cause us harm and which we can let slide.
00:01:03.039
We may all share the understanding of the importance of reacting to uncaught exceptions. However, some of our processes—or lack thereof—can make these notifications elicit a sense of dread.
00:01:24.560
Welcome to Schrödinger's Error: Living in the Gray Area of Exceptions. I’m Sweta Sanghavi, a developer at BackerKit. I've become really interested in why exceptions are so difficult to manage and what we can do about it.
00:01:40.720
Today, I'm going to walk you through some process experiments we've tried on my team at BackerKit and highlight the learnings we've surfaced. Then, we're all going to engage in triage duty together and look at some tools we can use to help manage exceptions effectively.
00:02:01.920
Alright, put on your helmets and your space boots. Keep your arms inside the vehicle at all times.
00:02:08.399
To lay some groundwork, at BackerKit, we support creators in fulfilling their crowdfunding projects. If you’ve backed a crowdfunding campaign, you may have received your survey through BackerKit.
00:02:18.720
We are a small, lean team. Our daily flow involves pairing up in the morning and working down a backlog or queue of features, chores, and bugs.
00:02:35.840
We surfaced a problem that, despite knowing the importance of reacting to impactful exceptions, we weren't very effective at doing so. Upon thinking more critically about our process, we realized it was pretty light on addressing these exceptions.
00:02:51.920
We had a Slack integration that surfaced unresolved or ignored errors into a channel. Still, while pairing, someone who was either soloing or had a spare moment may not look at that channel when something important was happening.
00:03:01.120
This setup required context switching from prioritized queue work. Furthermore, there was no owner or designated developer for issues, resulting in only a few people regularly checking it and many others not really paying attention.
00:03:18.239
We realized we had low alignment on which process to use for managing exceptions and not a shared understanding of what effective management looked like, which exceptions were high priority, and what actions to take in response.
00:03:36.000
There was also a significant backlog of errors, making it challenging to scan through quickly or to surface urgent issues that needed addressing.
00:03:48.879
So, we started to experiment with some process changes to improve our exception management. Our first experiment was affectionately called "Badger Duty." We utilize Honeybadger as our observability tool, so Badger Duty involved each of us managing exceptions for the week.
00:04:05.279
We tracked how long it took to triage and address any significant exceptions. This was our first attempt at chipping away at the errors and also at desiloing exception management. As we each became more familiar with exception management, we began to identify our pain points and understand why it was difficult for us.
00:04:25.040
Firstly, priority was unclear. It was difficult to gauge when something was urgent just by scanning exceptions, and in comparison to our high-value feature work, addressing exceptions could seem low-priority. Internally, we weren't aligned on which exceptions were of high priority.
00:05:10.160
Additionally, many exceptions had low actionability; we lacked a well-aligned response strategy, which often left us feeling stuck when encountering problematic exceptions. We also discovered a lack of alignment on our overall goals, highlighting the need for this initial experiment to establish a base for future iterations.
00:06:06.080
Through this first experiment, we recognized that having a structured process gave us clarity on who was tackling exceptions and helped identify areas of misalignment. We realized the significance of getting aligned on our goals as we continued to iterate on this process.
00:07:03.680
Also, Badger Duty provided a foundation for us to explore disagreements during pairing sessions while triaging exceptions, facilitating the first steps towards alignment.
00:07:51.440
I’m going to take you through the goals we arrived at as a team. Our first goal was to enable visibility of signals through the noise when managing exceptions. It should be apparent when something requires attention and surface above the more noisy exceptions.
00:08:05.440
Part of achieving this involves addressing some of that noise to allow important signals to come through. Our goal isn’t to reach zero exceptions or achieve an inbox zero mentality.
00:08:59.679
We also aimed for collective ownership of addressing exceptions. We acknowledge that having everyone exposed to exception occurrences in the app fosters involvement in finding solutions, sharing knowledge, and leveraging different perspectives.
00:09:33.760
Finally, we want to proactively address exceptions and prevent unfavorable user impacts. For instance, we should identify when a user finds themselves in a state they can't escape from before we receive those user reports.
00:10:07.760
In line with this, we proposed another process change. The next step was to implement rotating pairs to triage exceptions daily. Having a clear owner allowed for focused attention on managing exceptions.
00:10:38.720
This setup also permitted resource decisions to be made at the start of the day by looking at schedules, high-priority work, and workload capacity.
00:11:05.760
Regular exposure for everyone in the team to the nuances of exception management further supported alignment as different people encountered the same issues and discussed the pain points, thereby facilitating solutions collectively.
00:12:00.240
Now, I’ll illustrate what it looks like to be on triage duty at BackerKit. When you start, you begin at the top of the unaddressed errors queue. You have a 15-minute timebox to determine the priority level of the bug.
00:12:47.920
Generally, you have three options: either determine that it should be fixed but not immediately addressed (so you note it down), or acknowledge it, indicating that there’s nothing actionable at the moment but noting you'll want to be aware if it happens again.
00:13:31.440
The third option is if you conclude it’s a high priority and you need to fix it right away, in which case you would create an immediate bug ticket and start working on it.
00:14:15.280
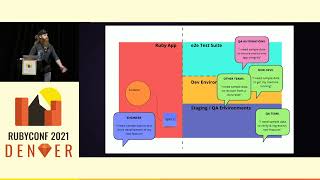
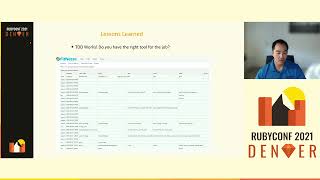
For particularly high-priority exceptions, a tool we'd use during bug duty is the dashboard to get a quick glance at unaddressed exceptions. This transforms the errors from our Slack integration into a more user-friendly interface.
00:15:00.560
Using the dashboard allows us to make informed decisions about our backlog, as we can better understand the volume of errors and the rate at which they require attention.
00:15:50.080
I also want to elaborate on what it means to acknowledge an issue. Acknowledgement in our process implies we recognize the error but do not require immediate action.
00:16:05.440
We’ve initiated auto-resolving weekly, meaning if an acknowledgement isn’t revisited within a week, it will show up again, compelling the team to reassess its priority.
00:17:12.560
Establishing categories for why we might acknowledge exceptions has proved helpful in discussions about the priority of different exceptions.
00:18:05.440
One key learning from our latest process changes was that exceptions can be tackled collectively over time. When you’re limited to 15 minutes for triaging, you learn to focus on making progress rather than fixing everything at once.
00:19:24.960
It reshaped my perception of how to address an issue. Sometimes it simply means adding information to breadcrumbs or parameters for the next person who might handle it.
00:19:42.720
You can also take small actions, such as refactoring to clarify the source of an error for future developers, or logging the incident to keep track of recurring issues.
00:20:10.560
Another critical learning was the art of crafting bug stories that are compelling enough that developers would actually want to pick them up. Providing sufficient context for the next person to understand what you've found is essential, without allowing unrefined theories into the ticket.
00:20:45.760
Useful practices include linking to logs, explaining how to replicate the exception, and attaching any relevant information discovered during the investigation.
00:21:27.520
Moreover, writing a test that showcases the same system causing the exception can be incredibly beneficial for linking to a bug ticket, affirming your understanding of the underlying issue.
00:22:11.920
Another discovery from the triage duty process was that while we were good at creating bug tickets, we weren't always picking them up, causing our backlog to grow.
00:22:34.960
To counter this, we made it a part of our process to pull a set number of bugs over each sprint. Having that commitment means we inherently prioritize bugs by creating dedicated space in our sprint planning.
00:23:48.000
If no one advocates for specific bugs to enter a sprint, it suggests to us that those issues might not be of high importance, and allows for a natural culling of the lesser priority bugs.
00:24:28.960
Additionally, by analyzing our top occurring errors, we've noted that a small number of exceptions often account for a significant portion of the total. Regularly addressing these can be particularly effective in reducing overall error noise.
00:25:25.440
Finally, it’s crucial to identify levers for improving efficiency. Prioritizing to allow faster triaging has illuminated what has historically slowed us down, and given us a better understanding of the context required for addressing exceptions.
00:26:00.640
Now, I’d like to go through two specific errors from our app as part of our triaging process. The first is a Faraday timeout error; we'll walk through understanding its context together.
00:26:57.440
Our priority will involve determining the nature of the error: this NetReadTimeout error lets us know that data is not being read within the expected time threshold. It's important to understand the implications and frequency of the occurrence.
00:28:28.720
From our investigation, we know this error occurs infrequently but when it does, it is accompanied by user actions trying to retrieve data.
00:29:11.600
In light of the fact that our retry procedures on this issue will have a less than beneficial outcome without addressing the root cause, deciding when/if to implement a fix is essential.
00:30:05.680
Moving on to our second error: a missing correct access error from the project vector worker, which seems to frequently occur in situations where external integration credentials are involved.
00:31:00.800
Again, analyzing the context of this error lets us identify its source and determine whether implementing a preventative measure or workaround could alleviate this problem.
00:32:34.200
In our experience, optimizing how we handle recurring low-value exceptions impacts our product quality and user experience.
00:34:00.960
Ultimately, I'd like to share that addressing exceptions is a continuous process involving cooperation, patience, and the right tools.
00:35:20.000
I appreciate everyone joining me on this exploration of exceptions. If you have further questions or thoughts, please reach out to me on Twitter or find me outside after the session.
00:36:08.000
Thank you to my coworkers who inspire me to continue experimenting and to everyone at RubyConf 2021 who helped shape this discussion. If you’re interested in learning more about TDD, experimentation, or crowdfunding, do reach out to BackerKit—we’re hiring!