00:00:16.480
All right, are we ready to go? Ready to do this? I think I'm ready.
00:00:23.199
My talk is called 'Services and Rails: The Sh*t They Don't Tell You.' I'm going to discuss how Yammer builds services alongside Rails and share insights about the aspects that we often overlook.
00:00:34.559
My name is Brian, and I work on the Rails team at Yammer. One of the things we do is help extract chunks of functionality from our large Rails application into services, integrating them back into the Rails app.
00:00:45.360
I also love Ruby, music, and Zelda. So, what is Yammer? We build social networks for businesses that facilitate conversations and collaboration across various business applications.
00:00:58.399
At Yammer, we use our own product heavily, which allows us to essentially avoid using email, which is fantastic. This is an old image of what Yammer looked like about a year or a year and a half ago, but it illustrates all the moving parts on this page. All the different colored boxes represent various services.
00:01:14.799
If any of these services aren't available, we still have some degree of a degraded state here, and often, the user won't even notice that one of these services has gone down. Now, some fun facts about Yammer: we have over a hundred web servers running our Rails app and over 40 Memcache servers. We process about 500 million requests a day to our Rails app, we have a 98% cache hit rate, and we hardly ever go to the database.
00:01:37.759
We perform about 240,000 Memcache gets a second and 20 billion cache hits a day. However, we also have some not-so-fun facts: our test suite takes about 10 hours to run. We parallelized it across 20 EC2 instances, and even then, it still takes about 20 to 25 minutes. Luckily, we now have a second test suite that is our fast test unit suite, which is helping significantly.
00:02:03.759
Before we dive deeper into the discussion, I want to address something I often find irritating about talk titles. I dislike when talks have gimmicky titles but don't explain the gimmick. I want to make sure I don't fall into that trap. This is actually the first conference talk I've given, despite having presented it three times now.
00:02:37.120
While preparing this presentation, I reflected on my last experience of speaking in front of a class. One key element I remembered was the importance of the template you use. So, now that we are part of Microsoft, we have numerous templates to choose from, and I found one I really liked.
00:03:10.400
It said, 'Full bleed photos can set a mood or evoke emotion, making for a more memorable presentation.' I decided to incorporate this slide into my presentation. Every time you see this guy on screen, he'll help highlight important points we don't often discuss. My intention was that this would help you know when we were discussing main points. However, people later told me that they knew me as 'the guy with that dude in all his slides,' so at least I was memorable.
00:03:43.920
Let's get started. Much of what I share might not apply to you yet if you're building a startup to determine viability. You're likely going to ignore a lot and focus on getting things done because adding services brings complexity. You probably don't know enough about your business and applications yet to implement this kind of structure.
00:04:12.480
This doesn't mean that writing clean, well-designed code isn't essential; it's just that thinking about services at that point is difficult. If you have clean code, extracting it into services will make your life significantly easier.
00:04:39.280
Once you realize you need to build services to scale, you'll have to make some uncomfortable decisions. At Yammer, we have a huge Rails app with over 300 models and more than 200 controllers. This application is supported by over 20 JVM services, and some of these services handle over a billion requests a day.
00:05:02.400
Despite this, we still manage to work with our large Rails app. It becomes increasingly challenging, but we've managed to address some pain points by gradually building out services. However, we still face difficulties when it comes to tasks like sharding or upgrading Rails; these are all-or-nothing projects, making the process quite painful.
00:05:31.680
Now, let's discuss service-oriented architectures. It seems that SOA has developed a negative reputation at this conference, but it enables us to accomplish many amazing things. One of the primary goals is to achieve components that scale individually. These small, focused services are more versatile and allow for easier reusability.
00:06:07.440
Here is a diagram of our Rails app alongside a few of the services we have. With our previous stack experience, we were able to separate components of our search infrastructure. In the middle, we have a denormalized data store service that takes data from the Rails app, denormalizes it, and makes it available for other services to interact with.
00:06:31.919
Additionally, we have our indexing service that builds the Lucene indexes from transaction streams from the central data store. On the edge, we have our search interface. When we wanted to add another feature to the search service, such as autocomplete, it was seamless because we already had the necessary infrastructure in place.
00:06:57.520
We can deploy these different services independently and gain a clear understanding of each service's specific needs regarding performance patterns and production. We no longer need to allocate resources haphazardly across the entire stack, which is one of the key advantages of this separation.
00:07:25.440
The loose coupling compared to a monolithic application allows us to encapsulate everything effectively. We can deploy and push out independent updates without significant cross-dependency issues—granted, our interfaces need to remain consistent, but that’s a separate challenge we can address.
00:07:50.560
Currently, we are switching out our file backend from Node.js to a Java service. The transition has been fairly smooth due to having these clearly defined, separated concerns.
00:08:18.960
Another goal of adopting service-oriented architectures is maintaining codebases that can scale across our organization. If you've worked on a monolithic application, you may have found yourself stepping on people's toes while trying to manage a lot of application knowledge to understand how everything functions.
00:08:43.680
Let’s examine distributed execution—not from the computing perspective, but from a development standpoint. Because of the loose coupling and the way we’ve divided our codebases, it is now easier to assign teams to specific services while coordinating with the clients or consumers. This allows teams to collaborate efficiently on how various components will interact.
00:09:07.680
We often build dummy components to facilitate service building without implementing everything initially. This way, we can expose the service's interface while allowing the client side to start sending data, albeit not necessarily the correct data straight away. This allows teams to unblock each other and continue making progress.
00:09:38.160
As I've mentioned, this doesn't happen overnight. When you're starting a new application or startup, all of this adds complexity and can hinder your ability to ship products quickly. In the early stages, a single undivided codebase allows for rapid changes, direct access to data layers, and easy code sharing, thus avoiding the overhead associated with managing multiple services.
00:10:07.680
You'll learn a lot of these lessons iteratively. It's essential to understand Conway's Law, which states that organizations that design systems are constrained to produce designs that reflect their communication structures.
00:10:30.080
If our organization is optimized to avoid bottlenecks, we'll create code that aims to function similarly. This is especially important when considering service structure and communication between development teams. A common scenario is that organizations separate departments either vertically or horizontally, which may lead to silos that inhibit communication.
00:10:55.680
An example from our early days at Yammer involved a messaging team responsible for handling message feeds. They managed both the service and its integration with the Rails side, making it a significant responsibility. However, this led to siloed knowledge, and it wasn't always the most critical focus area.
00:11:23.200
As we recognized the limitations of the feature team approach, we opted for a functional division of labor. We established a Rails team that would take care of the implementation of services within the Rails framework and coordinate with a core services team to define how these services would function.
00:12:13.040
While the Rails team continues to handle the monolithic architecture issues, the aim is to progressively move more functionalities into services, thus reducing the knowledge burden on the Rails side.
00:12:40.560
When creating a new service or feature, we assemble cross-functional teams representing every project aspect. Typically, these teams consist of two to ten members and remain engaged for two to ten weeks. This setup encourages dynamic collaboration across various projects.
00:13:12.440
We have a broad range of projects, including infrastructure projects, developer tools, and core product features. The flexibility of these functional teams allows us to assign engineers to work on a variety of challenges.
00:13:42.080
As there are multiple roles involved within the cross-functional teams, they typically include two Rails engineers, a core services engineer, a mobile client team member, a product manager, and a QA engineer. This structure brings autonomy to teams that are closely connected to the code.
00:14:10.560
They negotiate the MVP with the product manager to ensure we build the smallest feasible product to test our assumptions with our users. Managers aren’t involved in writing code, allowing individual contributors to drive the decentralized design process.
00:14:34.160
Consequently, these teams create well-informed, isolated, and reusable systems. The key takeaway here is that these teams are temporary; they assemble, solve whatever problem they are tackling, and then move on.
00:15:06.240
Since managers are not involved at this level, any team member can take on the tech lead role, providing an opportunity for various engineers to gain leadership experience. These cross-functional teams quickly acclimate to the domain they're working on while leveraging the advantages of distributed execution to work simultaneously without blocking one another.
00:15:33.760
The teams also coordinate the API between services and clients, which results in these naturally emerging services. However, there are trade-offs involved.
00:16:01.920
For instance, distributing expertise might introduce challenges; some may argue that having non-specialized teams is beneficial, but team members need to learn new domains repeatedly.
00:16:34.240
Coupling the API and implementation for clients presents another challenge. As we build these components, careful consideration is necessary to ensure our API remains effective.
00:16:53.600
Following a project’s completion, the cross-functional team disbands, which complicates support for features. In the past, a dedicated messaging team would easily handle any messaging-related bug, but this is not always feasible in a cross-functional model.
00:17:14.080
To manage this, we established a support engineering team. This team addresses urgent issues, ensuring that the primary cross-functional teams aren't constantly interrupted by problems they previously worked on, maintaining focus on developing new features.
00:17:44.800
There's a wealth of knowledge required for the support engineering role, but it’s structured as a rotating opportunity, allowing team members a chance to either grow or revisit other teams.
00:18:03.680
Now, about building services—there's no single way to do it. Many of our services operate in such a way that they're encapsulated within Rails, and clients cannot connect with them directly.
00:18:37.679
These services have their own back-end systems, but they remain behind the Rails application. While this approach has been beneficial for us, we are still reliant on Rails resources and require the Rails app to interact with these services.
00:19:04.320
Eventually, you'll want to allow direct client interaction with a service. Sometimes this transition is straightforward—like our 'Mugshot' service that dynamically resizes and caches avatars—because it has minimal state and a focused purpose.
00:19:34.160
As you progress, you'll face additional considerations, particularly when it comes to authenticating how the browser communicates with these services, a challenge that we hadn’t previously encountered.
00:19:54.560
As your application matures, you may find yourself needing data that resides within your Rails application directly from a service. Although reading from the Rails application's database isn't necessarily harmful, it's not the best approach either. Writing to the database, however, can pose significant challenges, especially since Rails knows about the caching layer, while our services do not.
00:20:24.320
Active Record can complicate this process, as it often 'holds your data hostage’—it provides powerful tools like callbacks, validations, and state machines, which are beneficial when constructing our applications. However, they create issues when trying to extract data for direct access to a service.
00:20:53.920
To handle this, we rely on storing IDs and indexing data via our services, hydrating the relationships through the Rails application. One growing trend is to move data entirely out of the Rails realm and into the service so that it retains ownership of that data.
00:21:16.840
This approach allows us to manage our sharding and caching implementations more effectively. However, it's vital to remember that, in many instances, we previously relied on Memcache.
00:21:39.840
Therefore, the service needs to maintain an effective caching layer or respond with comparable speed. With the decision to move data, we often face the realization of duplicating data.
00:22:07.680
Having to duplicate data creates potential complications. Generally, you can't afford downtime during this process, and if the service doesn't function as intended, rolling back can be challenging. Thus, it’s essential to create a backup plan as you duplicate data.
00:22:40.800
Double dispatching is often our approach to backfilling data into the service while continuing to write data requests to the database in Rails. As this process unfolds, we monitor the service to assess its production viability.
00:23:02.080
The backfill serves as a glimpse into the service's scalability, with data being input at a much faster rate than in a typical production environment. This allows us to evaluate capacity and anticipate performance.
00:23:24.000
However, this also leads to the challenge of managing duplicate data. We need to clean this up swiftly since confusion arises when data exists in both the Rails app and the services, creating ambiguity for developers.
00:23:52.160
It's crucial to ensure the transition is handled well because the familiar method feels comfortable, and making the leap to adapt to new challenges can be daunting.
00:24:16.000
While diving into these new issues is necessary, it's important to create an incremental transition. Ultimately, you have to decide when to commit to fully switching over to your new model.
00:24:41.600
In our journey, despite all this additional complexity, a solid development story is critical. If you cannot ensure your developers can efficiently work with the environment, they may struggle to adapt.
00:25:04.800
It's important that the benefits of adopting services outweigh the difficulties; otherwise, developers may revert to previous methods, leading to more potential problems.
00:25:25.360
To simplify this process, we've utilized Vagrant. With an internal Vagrant development setup, we ensure it's as close to production as possible, using the same Ubuntu version.
00:25:51.440
We can run all our services locally, keeping pace with rapidly changing requirements while ensuring developers have minimal knowledge of service internals when they're not directly working on them.
00:26:12.240
This internal tool runs within our Vagrant VM instances and allows us to manage services seamlessly, ensuring they’re installed or updated appropriately from a central panel.
00:26:34.160
Our one-click deployment system, which is integral to our workflow, offers a simple interface for deploying services rapidly, enabling engineers to set things in motion without hassle.
00:26:56.640
Monitoring and alerting have become essential. We use various tools for monitoring our JVM services and infrastructure, while our Rails app utilizes custom charting tools.
00:27:09.360
Understanding performance in lead-up environments is critical. As we integrate multiple services, we begin to care more about response times, ensuring that they function properly.
00:27:43.680
When our Rails app interacts with a service that isn’t responsive, we have to ensure that the requests degrade gracefully instead of failing outright. Alerts provide us much-needed information in these cases.
00:28:05.480
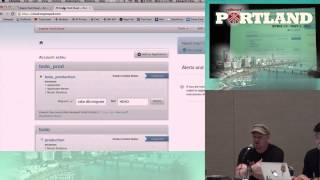
To illustrate our monitoring efforts, I want to introduce a tool called Charty. It gives a clear perspective into our Rails app, allowing us to analyze response times in efficiency, focusing on high-impact actions.
00:28:32.000
With Charty, we can monitor trends and understand performance issues more thoroughly. This meticulous visibility helps us address challenges and better manage service integration.
00:29:03.920
Consequently, having standardized deployment processes and a dependency management system becomes pivotal for overseeing multiple services. This prevents us from getting bogged down in unique exceptions.
00:29:29.360
Our approach is further solidified by using a unified format for responses, data protocols, and monitoring interfaces, as seen in a technology called Dropwizard, which standardizes our service package for Java services.
00:30:00.080
While Java serves as our main implementation language for these services, we have no intention of dismissing Ruby's potential applications for service design. Large-scale architecture changes will continue to carry trade-offs.
00:30:28.320
Understanding and addressing these trade-offs is essential. As services become unavailable, we need to have plans to manage service failures.
00:30:54.480
For example, the impact of a service failing can result in significant operational challenges—identifying failure points across complex service interactions requires thorough comprehension of system flow and service dependencies.
00:31:24.960
Recently, we experienced a failure with a service that caused a cascading failure across other dependent services, leading to a slowdown that rendered the client experience unusable.
00:31:42.640
Understanding the complete system dynamics when services fail is crucial. We recommend testing these scenarios in staging environments to see what happens when services go offline.
00:32:01.840
As we recap the discussion, prioritize reevaluating costs and trade-offs. Make sure the choices being made still align with your goals, and don’t scale until you’re confident.
00:32:29.840
When you recognize the need to transition to services and embrace the associated complexity, ensure your organization is supportive of such changes. It's important to promote a culture of service-oriented development.
00:32:54.640
Finally, deploy tools that help you move quickly without sacrificing quality. Remember that your customers care about the results, not the internal workings. If developers face hurdles, they might choose the path of least resistance and continue adding features to the monolith.
00:33:35.280
As parting advice, be prepared to be wrong. Mistakes are part of the learning process. Our team has rewritten our search stack multiple times, and each iteration has taught us valuable lessons about services.
00:33:49.600
Reflect on past decisions, recognizing that they may not align with current needs. The landscape may shift as your goals evolve—adaptability is essential. We’re all continually striving to improve our enormous Rails app, recognizing that every increment of change is a step forward.
00:34:11.200
Thank you, everyone, for your time and attention. You can find more information on my company’s engineering blog, and my name is Brian Morton.