00:00:20.480
My talk, as you said, is called "Services and Rails: The Shit They Don't Tell You." Today, we're going to discuss how Yammer builds services alongside Rails and explore some things that are often overlooked.
00:00:25.680
This is me—my name is Brian, and I work on the Rails team at Yammer. One of the things that the Rails team does is help extract chunks of functionality from our Rails codebase and integrate those into services.
00:00:32.640
I also love Zelda, music, Ruby, and, of course, Yammer. Now, maybe I can talk closer to the microphone; does that help?
00:00:57.280
Check... good? Awesome! So, first, I have a little pet peeve about the titles of talks, and I want to address that. I don't like when talks have a title that doesn't relate to the content, so I'm keen to ensure my talk includes the 'they don't tell you' gimmick.
00:01:09.760
As mentioned earlier, this is my first conference talk. Just a week ago, I was nervous but excited about presenting. While preparing, I thought back to the last time I had spoken in front of a class and recalled that one important aspect back then was choosing the right template for my talk.
00:01:32.720
Now, Yammer is part of Microsoft, which provides us with many templates. I found a slide in one of them that said, 'Full bleed photos can set a mood or evoke emotion, making for a more memorable presentation.' I thought this was valuable, so I included it in my presentation. This slide allowed me to connect my pet peeve about talk titles to our discussion.
00:01:57.360
It illustrates that every time there's a point we don't often discuss. This character will frequently be on screen to help highlight those moments.
00:02:30.800
Now, regarding this topic: This might not apply to you yet. However, if you are building a startup to determine viability, you might want to push some of this aside and focus on getting things done. Introducing a lot of complexity can be counterproductive at this stage.
00:02:41.280
Nonetheless, it doesn't mean you shouldn't write clean, well-designed code. It's just that, at this point, focusing on services might be a distraction. If you do have clean code, extracting it into services will be much easier.
00:02:52.959
As you begin to build services and scale, you must do some things that may feel uncomfortable.
00:03:04.720
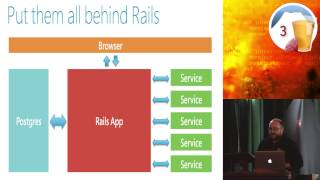
At Yammer, we have a massive Rails application with over 300 models, some of which are substantial. Additionally, we have more than 200 controllers and significant content in our lib directory. Our system is backed up by over 20 JVM services we have built, with some of these services handling over a billion requests daily. Thus, we maintain a pretty substantial ecosystem.
00:03:21.599
However, we still deal with this massive Rails app, and the challenges intensify as we proceed. For a long time, this structure has worked for us, and we've managed to chip away at the problem by progressively building services, although it often feels painful.
00:03:39.520
However, tasks like sharding or updating Rails or Ruby turn into all-or-nothing projects, which can be quite difficult.
00:03:52.720
In this talk, we will discuss Service-Oriented Architectures: why we build services and what benefits they provide us.
00:04:03.439
One of our fundamental goals is to develop components that can scale independently. When you have small, focused services, they are more versatile and enable easier reusability.
00:04:16.799
Let’s talk more about reusability. We have our Rails app and several other services in our infrastructure. This example is based on some of our prior experience with search stacks. We were able to separate different components of our search stack.
00:04:28.560
In the middle is Flattery, which serves as a denormalized data store in Rails. We have hooks in Rails that publish data into Flattery, allowing us to store a denormalized representation. Dexi, depicted to the right, is our service that builds Lucid indexes from transaction streams sent from Flattery.
00:04:51.681
Ultimately, we built our search interface in this manner. When we wanted to incorporate a new search service into the stack, it was relatively easy for us. We developed an autocomplete service called Completey, which integrated directly into the existing pipeline.
00:05:14.560
We already had the necessary components in place and clean interfaces defined. The same principle applies to exporting data, where we have a service called Slurpee. Part of this pipeline already existed, and we didn't have to pull data from Rails again.
00:05:28.960
That's fantastic because now we have many independent components that can scale individually. This setup allows us to better understand each service's specific needs and performance patterns.
00:05:41.280
We can assess these metrics and avoid unnecessary resource allocation across the entire stack.
00:05:59.440
This flexible architecture is enabled by the loose coupling of components. We have encapsulated many of our concerns within smaller, more focused services.
00:06:10.160
We can independently push updates to each service without necessitating large-scale deployments. The Rails app still demands mass deployments; however, we can release smaller pieces of infrastructure in various ways.
00:06:27.360
Most importantly, we can swap out infrastructure components without needing to notify anyone, as long as we maintain consistent interface standards.
00:06:39.360
Currently, we are in the process of changing our files backend. It's been somewhat painful, requiring more adjustments than anticipated, likely due to some initial missteps.
00:06:52.080
Largely, we have the ability to replace this entire service with a new one.
00:07:10.560
The second goal of adopting service-oriented architectures is to create maintainable codebases across the organization. If you've worked with a monolithic application, you have probably encountered challenges like stepping on each other's toes or needing to retain vast amounts of application knowledge.
00:07:27.200
With services, you navigate through numerous 'black boxes' dedicated to specific tasks. You can learn about these services as required on a case-by-case basis.
00:07:45.440
This advancement gives us a concept of distributed execution enabled by the loose coupling of services.
00:08:00.320
This division isn't just in a computational sense but also applies to development. We split our codebases, which makes it easier to appoint a team to a specific service. That team can coordinate and establish how these components will interact with each other.
00:08:15.680
We often create dummy components at the initial stages, integrating some data on the Rails side while developing a service that accepts this data without yet performing any operations.
00:08:34.080
When the project progresses and approaches completion, we establish a full end-to-end test. This allows team members to unlock each other and incrementally develop the service.
00:08:51.440
Our discussion may seem complex; the journey of transitioning from a single codebase to distributed services is filled with challenges.
00:09:03.280
When you're an early-stage startup, managing this level of complexity can hinder your ability to ship products quickly. With a unified codebase, you have the freedom to implement changes swiftly.
00:09:17.760
You can interact with your data layers directly, share code easily, and evade some overhead associated with managing services. Although some challenges may resurface later, swift progress is vital.
00:09:32.560
We discovered at Yammer that moving to this distributed structure often requires organizational change.
00:09:46.560
At Yammer, we frequently discuss Conway's Law, which states that organizations designed to avoid bottlenecks will produce systems that reflect the communication structures of those organizations.
00:10:07.360
It's important to consider how our development teams are structured when contemplating services. Many organizations divide their departments vertically or horizontally, leading to silos.
00:10:19.920
This siloing can result in team members becoming overly attached to their responsibilities, which ultimately inhibits communication and decision-making.
00:10:34.080
In the early days at Yammer, our messaging team managed the service that handled all message feeds. The team was responsible for both the service and the Rails side of the implementation.
00:10:51.440
They decided on the interface and how to implement it, leading to siloed knowledge about the entire system—something that wasn’t necessarily the best use of their time.
00:11:07.200
As we considered scaling to accommodate future needs, we had to determine how to strategically manage feature teams.
00:11:24.320
To improve our organizational structure, we adopted a new model. This is what we have now: a Rails team and a Core Services team.
00:11:39.680
The Rails team is predominantly responsible for developments in the Rails app while the Core Services team handles service-oriented tasks. All codebases at Yammer are open, so being on the Rails team doesn't limit you to writing Ruby code.
00:11:56.320
While the Rails team has to understand the monolithic Rails application, moving elements into services helps reduce dependencies on that knowledge.
00:12:07.680
We also introduced the idea of cross-functional teams. When we begin developing a new service or feature, we assemble a cross-functional team with representatives from all relevant departments.
00:12:23.760
These groups usually comprise two to ten members from various functional teams, who work on a project together for two to ten weeks. This approach ensures that team members constantly work with new people on diverse projects.
00:12:40.800
This method resonates with Sarah's point about diversity in project teams. Although we don’t do consulting work, our domain remains dynamic, and we face numerous problems simultaneously.
00:12:56.960
From infrastructure projects to developer tools and core product features, we also handle backend tasks related to tech debt and service extraction.
00:13:10.880
Our analytics team builds tools for the data pipeline, and these tools and features sometimes circle back to product engineering.
00:13:26.240
While we have functional teams, we essentially have a pool of engineers who can work on a wide range of challenges.
00:13:39.120
An example of a cross-functional team would include two Rails engineers, a core services engineer, a mobile client engineer, and various other contributors, depending on the project needs.
00:13:52.320
This setup promotes a decentralized design process with autonomy, leading to well-crafted, isolated, and reusable systems.
00:14:05.120
These teams are ephemeral; they disband after completing their project and transition to new endeavors.
00:14:19.680
Another interesting feature is that any one of the team members can serve as the tech lead for a specific project.
00:14:31.200
Rather than a perpetual manager overseeing these teams, leadership roles shift with every project, allowing individuals to contribute code and gain diverse experience.
00:14:49.760
Once teams are assembled, they delve into their designated domains, leveraging distributed execution to accomplish their tasks. They coordinate on the API agreements between services and clients.
00:15:03.040
As a result, we regularly form service-oriented collaborations when these cross-functional teams convene.
00:15:20.160
It's important to note that while this model offers advantages, it also presents trade-offs. We have encountered some challenges but have generally managed them well.
00:15:39.920
One potential drawback of not having specialized experts across the application might seem negative, although some might argue it provides flexibility.
00:15:55.520
However, there are costs associated with having teams constantly learning new domains.
00:16:12.320
Another emerging issue we’re discussing more frequently is the risk of tightly coupling client API implementations, as our mobile clients demand increased customization of data.
00:16:27.760
It's crucial we remain vigilant regarding feature-oriented project designs to ensure we keep our systems decoupled.
00:16:42.080
Following project completion, we still need to support those features. Once teams disband, shipped products may encounter bugs, which we need to address.
00:16:59.520
We counter this through the formation of support engineering cross-functional teams, which regroup for two to ten weeks to tackle these as-needed issues.
00:17:14.720
This process can be a bit more challenging due to the unfamiliarity with the domain and codes written by the original teams. But it's a trade-off we accept.
00:17:29.280
There isn’t just one method to pursue this strategy; it may look different based on specific needs and circumstances.
00:17:44.320
It may still resemble the structure of a Rails project for the foreseeable future. We modified our organizational structure but continue to grapple with challenging problems.
00:18:01.680
A common temporary solution is routing traffic through Rails instead of allowing direct communication with services. This yields some practical benefits, but it also forces us to rely on Rails resources to access service functionality.
00:18:18.080
Eventually, we aim to permit browsers to communicate directly with services, but when pursuing this route, we must also consider issues like authentication.
00:18:34.320
Problems can arise when we try to implement this model, and navigating these challenges appropriately becomes critical.
00:18:51.680
Users often look for efficient authentication solutions when they wish to bypass Rails to access data stored behind it.
00:19:06.960
Ensuring seamless connection with databases is essential, although writing to those databases can create complications.
00:19:23.120
Active Record is a powerful tool with many conveniences, but we face complexities when we try to extract data.
00:19:30.080
Detangling data from services comes with its own unique obstacles, especially when we deal with callbacks, validations, and state machines.
00:19:46.720
We often find ourselves making decisions that involve consulting Active Record to access the original data.
00:20:01.120
One potential route is to minimize reliance on Active Record altogether. Some companies take this approach; however, at Yammer, we find it incredibly useful.
00:20:18.560
Often, we use our services as indexes, stored with IDs or relationships.
00:20:37.680
In practice, that means our services build the index structure, although we still need to fetch original data from Rails. Rails management is necessary to successfully retrieve and handle that data.
00:20:52.640
Recently, we've considered shifting more ownership of data to services, referring to these as "bodega services," where you rely on a focal point for certain types of data.
00:21:10.960
We aim to streamline operations by trying to ensure that these services perform as quickly as accessing data from memcache. This goal is inherently challenging.
00:21:30.240
When we talk about moving data, we often find ourselves duplicating information, which can present logistical challenges.
00:21:46.640
Chances are, if you're like us, you can't afford downtime when moving data. If a service doesn't perform as expected, we face difficulty in rolling back changes.
00:22:06.080
That's where having a backup plan becomes critical. We pivot towards 'double dispatching' to backfill all the data to services.
00:22:24.720
We simultaneously write to the database while posting data concurrently to the service. During this process, we monitor and profile the service's performance.
00:22:41.440
This allows us to incrementally move traffic to the new service while ensuring relevant safety measures are in place. We have an exit strategy available if necessary.
00:22:59.040
We will be introducing a significant amount of new data input to the service, which often can happen at a much faster rate than normal service operations.
00:23:15.200
This forward-thinking approach enables us to build capacity and anticipate how services will respond.
00:23:30.080
Once we initiate this process, we encounter another challenge: duplicated data.
00:23:45.440
We need to address how to manage and clean up this duplication swiftly to avoid confusing our developers.
00:24:01.440
At times, we fall short in cleaning up data promptly, leading to confusion—not an ideal situation.
00:24:15.760
Fundamentally, we must accept that we need to be willing to fully commit, which can be hard, as comfort with the old way might tempt us.
00:24:29.920
Staying in your comfort zone is not always an option; there needs to be readiness to confront new problems.
00:24:43.680
Understandably, you'd want to have a solid backup plan. Still, at some point, you need to choose to make the transition. The cost of maintaining a temporary strategy can drain resources.
00:25:00.160
Leaving your comfort zone and embracing the complexity of new systems is imperative.
00:25:14.560
For developers to succeed, they need a solid story regarding their development environment. If your environment is cumbersome, developers are likely to revert to comfort zones.
00:25:36.960
So, my big recommendation is to use Vagrant. It’s been a great asset in structuring our development environment.
00:25:50.640
We strive to keep the environment as similar to production as possible, running Ubuntu on both ends. This replica allows us to operate all services locally.
00:26:04.400
However, as our number of services grows, we are encountering issues due to resource limits, especially since our laptops typically support only 16GB of RAM.
00:26:18.160
We also need to keep up with rapidly changing services. Developers have to stay updated on these matters.
00:26:36.960
We built a tool, running inside Vagrant, called Soup Kitchen. It’s designed to help developers update services efficiently.
00:26:53.760
It allows us to manage service updates seamlessly, so the main focus remains on development quality rather than constant maintenance.
00:27:05.360
Furthermore, we have to consider the deployment of these services. It's crucial that we have a process in place for adding new services effectively.
00:27:20.400
We need a system that manages efficient deployments and provides stable, pre-released packages supported by ongoing development.
00:27:36.000
As we manage numerous applications, it’s essential to ensure every engineer can deploy their services effortlessly.
00:27:52.240
We created a one-click deployment tool named Diplomacy, which unfortunately is not yet open-sourced but allows engineers to add new services without complicated processes.
00:28:10.080
The other aspect we need to be acutely aware of is monitoring and alerting systems for our increasing number of services.
00:28:24.720
Planning capacity and monitoring service performance is vital for ensuring smooth operations.
00:28:39.200
We utilize several monitoring tools, including New Relic, alongside in-house tools to track performance.
00:28:56.960
With that said, you also need standardized tools across all services, which streamlines response formats, data protocols, monitoring interfaces, deployment strategies, and dependency management.
00:29:15.680
This approach eliminates the notion of unique or special cases that complicate service interaction.
00:29:34.480
At Yammer, we have adopted a toolkit known as Dropwizard. This tool, maintained by Coda Hale, helps us package necessary Java libraries for service development.
00:29:52.680
Dropwizard offers an efficient setup for a production-ready service with built-in monitoring, alerting, and metric reporting functionalities.
00:30:13.920
While we heavily lean on Java, this doesn't rule out the possibility of utilizing Ruby for building services. There are scenarios in which extracting services into Ruby first and refactoring existing code is a more valid approach.
00:30:30.720
Even if we identify a need for more performance later, we can always shift to another language as the situation dictates.
00:30:48.320
Service-oriented architectures come with trade-offs. They offer abundant benefits, yet also present complex new considerations that must be navigated meticulously.
00:31:05.440
For example, complex systems are inherently prone to failure. A robust strategy for managing service unavailability should be developed as part of the response plan.
00:31:23.440
You may face problems detecting issues within multiple service levels, as alerts could originate from locations that don't reflect where the actual failure occurred.
00:31:39.600
As you adopt service-oriented architectures, be aware that transactions aren't free. These additional services introduce new complexities that must be managed.
00:31:56.320
Adjustments may be required to streamline API updates, and coordinated service deployments must be effectively supported across multiple client versions.
00:32:11.360
To recap, it's vital to continuously assess the costs and benefits of your decisions regarding service architecture. Are you still aligned with the trade-offs you initially accepted?
00:32:28.320
Being aware of your organizational structure is important—it’s beneficial to build a culture that supports service development and flow.
00:32:45.200
As your systems grow more complex, staying efficient in service deployment becomes essential, especially as you strive to meet customer needs.
00:33:01.680
It's important not to allow difficulties in building services to hinder your progress. When pressure mounts, you might be tempted to revert to earlier, monolithic structures.
00:33:15.680
Continuing to innovate in service design is crucial, and many lessons await on this journey. In the same way that you are allowed to acknowledge when you are wrong, embracing the learning process comes into play.
00:33:31.520
Each time we rewrite elements of our codebase, we discover new facets of effective service-building. Don't assume past decisions will remain valid, as adjustments in circumstances and information can change.
00:33:49.680
With that said, my name is Brian, I work at Yammer, and I appreciate your attention today.
00:34:05.360
However, just to clarify, that wasn’t all I had to share! After preparing my presentation, some questions arose.
00:34:15.920
I thought it best to address them at the end of my talk since they interrupted my presentation flow.
00:34:26.960
One question that often comes up is: "What should I extract into a service?" My general answer is that it truly depends on your application.
00:34:42.720
However, we have identified some successes with less state-dependent features. These services are easier to extract when they haven't become tightly integrated with your Rails application.
00:34:59.680
When developing new services, it's always easier to build components that don’t yet exist.
00:35:16.960
However, bear in mind that not every feature should be extracted as a service. At Yammer, we utilize A/B testing frequently.
00:35:34.240
After confronting some performance issues, we considered building a service around our experiment framework, but ultimately decided otherwise.
00:35:50.560
The data we require resides more closely within our Rails app, compelling us to recalibrate our focus on existing solutions.
00:36:08.800
It may be tempting to start anew, but often enhancements within the framework you currently have can lead to better outcomes.
00:36:24.640
Even after extracting something into a service, it’s critical to remember that you're not absolved from traditional development challenges.
00:36:37.680
Service extraction requires continuing diligence in terms of technical debt and evolving requirements.
00:36:53.760
Thus, adapt adeptly to changing conditions, ensure the reliability of services, and retain awareness that comfort with existing solutions might invoke reevaluation.
00:37:09.440
Now that I may have points worth discussing, let's return to the last slide for closure.
00:37:23.360
The idea is to be prepared to embrace mistakes. Acknowledgment and recovery are vital in ensuring you remain resilient as a service builder.
00:37:45.600
Thank you all for your time!