00:00:05.600
Hey everybody, my name is Ariel Caplan, and I'd like to welcome you to my talk, "The Trail to Scale Without Fail: Rails?"
00:00:14.580
Before we hop into the content of the talk, I want to take a moment to step back.
00:00:20.039
Please have a look at the image on your screen right now and think about why I chose this image, which doesn't seem to be related to scaling at all.
00:00:33.899
To me, what I see here is one user, one device, having one experience. When we talk about scale, it's easy to get lost in big numbers and fun technical details.
00:00:46.379
Ultimately, what we're really trying to do is create this kind of individual experience many, many times over. When we think about things this way, and ensure we are not just focusing on average response times, but instead really considering the ultimate user experience, we achieve much better results.
00:01:04.199
Now, to jump to the other side of the spectrum and dive into technical details, what do you think is the biggest Rails application in the world?
00:01:17.520
I began thinking about this a few years back when I attended a talk at Ruby on Rails called "The Recipe for the World's Largest Rails Monolith" by Akira Matsuda.
00:01:29.580
During that talk, he described Cookpad and the immense traffic they handle. He talked about various metrics that showcase the gargantuan scale of their Rails monolith.
00:01:41.700
The one I want to highlight is requests per second; he mentioned that they handle about 15,000 requests per second, which I found pretty impressive at the time, especially considering that at my company, the app had maybe a few hundred requests per minute.
00:02:02.280
The following year, at RailsConf, Simon Eskilden gave a talk about Shopify where he described that they handle between 20,000 to 40,000 requests per second, peaking at 80,000. I'm going to focus on that 20,000 to 40,000 range.
00:02:30.959
Just a few months ago, Shama, who is a VP of Engineering at GitHub, mentioned that the GitHub API deals with over a billion API calls daily.
00:02:43.019
I don't know if this includes git pulls and pushes or if it is really representative of their overall traffic, but I’m assuming it’s accurate within the general order of magnitude.
00:03:00.180
So we have several different Rails applications that showcase how to work at scale. If we want to compare them, we normalize them to requests per day.
00:03:17.640
Cookpad is about 1.3 billion requests per day, while Shopify is at 2.6 billion. That was in 2016, and I don't know how Cookpad has grown since then.
00:03:25.379
I know they have expanded into a few more countries. Shopify has nearly doubled the number of stores they host, so they are probably around 5 billion by now.
00:03:31.500
GitHub, just a few months ago, was at a billion requests per day.
00:03:39.180
Cloudinary, where I work, handles about 15 billion requests per day. These are not just regular requests associated with a Rails app; they are primarily media requests.
00:03:51.120
To give you a sense of our scale, it's like taking the other three examples and doubling them.
00:04:03.480
Now, consider a typical Rails app. A client makes a request to a server, which talks to a database, retrieves some information, and sends a response back to the client, either in HTML or JSON.
00:04:10.380
When we're dealing with Cloudinary, we operate a bit differently. I'm going to keep this view simplified, even though both your apps and our app are much more complicated architecturally.
00:04:31.320
Cloudinary serves images and videos. Often, we will not simply serve the images and videos we have stored; we also make various transformations.
00:04:45.000
If you've ever done image processing, you know it’s a computationally intensive process, and that’s what we handle for each of these requests.
00:05:10.380
Let’s dive deeper into what Cloudinary does, particularly if you're not familiar with our service, to understand the nature of our services, our use cases, and the resulting traffic.
00:05:28.680
We will focus on one image and how it journeys through our process. The first thing is that you can upload an image to Cloudinary.
00:05:37.920
We store it in one of our cloud storage solutions, typically Amazon S3 but sometimes Google Cloud Storage.
00:05:46.320
Next, we apply transformations and deliver the media via a CDN. Most of you can probably imagine what uploading and storing are, but the latter two items on this list might be more confusing.
00:06:02.160
Let’s clarify by going through them. Imagine you have an image uploaded by a user. Perhaps it’s not perfectly cropped and has a lot of open space.
00:06:24.960
You may want to fit it into different layouts on your site, which may require multiple crops, such as a portrait and a landscape crop. You also want to crop intelligently without simply taking a random slice.
00:06:47.760
If the image is to be used as an avatar, you would focus on the face. Additionally, you might want different sizes and shapes of the same image, such as a larger version for the author’s profile and a smaller one for comments.
00:07:02.640
In essence, you might not want to stop there, as you can enhance colors and pixelate faces to protect users' privacy.
00:07:18.000
You can also add a company watermark at 50% opacity. All of these transformations can be achieved in Cloudinary by appending little bits to the request URL.
00:07:36.420
For example, parameters specify enhancements, the cropping method, gravity to focus on the face, and the preferred compression. The transformations are all specified in the URL, and when parameters change, a different image is generated.
00:08:02.760
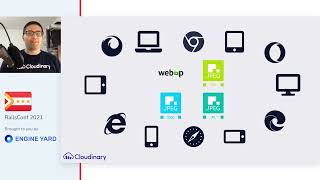
All requests in Cloudinary entail significant computational work. Your users will likely access your site from different devices and browsers, each supporting different image formats.
00:08:34.560
For example, WebP is supported in Chrome, but Firefox only gained support in late 2019. Different image formats must be generated and served appropriately.
00:08:57.000
Let’s discuss CDNs. The idea here is that you have your servers, maybe in Northern Virginia.
00:09:04.800
Your users might be anywhere around the world, and you want to serve media from a server that is closer to them. However, if your app servers are in one place, the CDN provides a network of computers around the world.
00:09:21.780
By caching media close to the user, the CDN can serve requests efficiently, saving time in loading content.
00:09:33.540
Now that you are a bit more familiar with how Cloudinary operates, let’s look at how we serve the 99.7% of delivery requests that involve transforming and serving media.
00:09:53.700
Most requests in our queue come from different sources like a media library GUI for cataloging and editing, various developer APIs, and bulk operations.
00:10:06.960
While I won’t focus much on them, bulk operations can be very heavy—like deleting 40,000 assets. Nevertheless, most requests center on delivering media.
00:10:24.480
Before diving into how Cloudinary solves problems at scale, let me share a bit about myself. I've been working in Rails since graduating from Flatiron School in 2015 and at Cloudinary since 2018.
00:10:38.660
I am @amcaplan everywhere that matters, particularly on Twitter and GitHub. If you want to contact me later after this conference, feel free to reach out on Twitter — my DMs are open.
00:11:01.920
I love conferences and have attended many Rails and Ruby events, enjoying the opportunity to interact and hear different perspectives.
00:11:26.520
I didn’t personally build most of the tech I’m about to discuss but had the opportunity to speak with those who did. My main interest here is to share some inspiring stories of Rails scale with you all.
00:11:56.020
Now, let’s dive into how Cloudinary scales. I won’t discuss auto-scaling in detail, but all our servers are in the cloud, allowing us to scale various groups up and down.
00:12:06.740
The topics I’m going to cover include dividing our service into layers, sharding, geographical location considerations, deduplicating work, and the human factors involved in scaling.
00:12:26.640
Starting with layers, I’m reminded of the quote from Shrek about layers. Like onions and ogres, Cloudinary has layers. Let’s go through the basics of an actual request lifecycle when hitting Cloudinary.
00:12:59.580
When a user makes a request, it first hits the CDN. If the asset is cached, it serves it back without talking to a Cloudinary server. If not, it proceeds to our servers, starting with a system called Segat, which shields our main app from excessive traffic.
00:13:34.680
The Segat service talks to the correct cloud storage bucket based on the request URL. If the asset isn't available, it goes deeper into the system.
00:14:02.480
Next, we rank our layers. The I/O layer is the main app that interfaces with the outside world, while the CPU layer handles the more computationally intensive tasks.
00:14:24.900
Once the CPU processes the image, it sends it back through the I/O layer to Segat and finally to the user's computer. Each layer helps us handle around 15 billion requests, as the CDN caches assets, only sending a fraction through the Cloudinary servers.
00:14:53.760
In 14 out of 15 cases, the CDN has the asset already cached, meaning most requests never touch a Cloudinary server. Of the remaining requests, around 150 million will go to the I/O layer and about 125 million will reach the CPU layer.
00:15:21.020
In terms of technologies, the I/O and CPU layers are both Rails applications running on different servers for optimization. The Segat service is built in Go, providing efficient handling of most of the traffic.
00:15:40.740
The CDN is essential for us, especially when serving media, and we collaborate with CDN providers like Akamai and Fastly. By using their services, we can leverage best-in-class technology for our content delivery.
00:16:01.680
Our strategy reduces the workload on our systems, enhancing both reliability and performance when dealing with high volumes of requests.
00:16:24.180
We also maintain multi-CDN support, which allows us to switch between CDN partners seamlessly in the event of downtime on one end, ensuring reliability.
00:16:43.320
However, using multiple CDN providers comes with its challenges. We need to comply with their individual requirements, such as formatting rules and cache invalidation processes.
00:17:05.160
We also need to manage billing by parsing log files to track which customer used particular resources—an aspect that requires continual attention.
00:17:38.940
Moving on, let’s consider another aspect of our architecture: the I/O layer and its relation to the CPU layer. The lightweight Go service manages a vast number of requests efficiently, dealing with many connections.
00:17:58.560
Despite our efforts to optimize, balancing workloads can be challenging yet allows us to streamline different job requests effectively.
00:18:24.840
When outlining our operations for scaling, we also aim to look at how layers within our architecture can function independently. Each layer’s capacity can adjust as needs arise.
00:18:40.680
For example, if the CDN handles an increase in requests, Cloudinary doesn’t need to scale simultaneously. Each facet of our architecture can be optimized separately, ensuring that our resource distribution is efficient.
00:19:03.140
Security is also a priority; our CPU layer is safeguarded to mitigate potential vulnerabilities, ensuring that it operates effectively without direct internet access.
00:19:24.600
Next, let's dive into sharding, an essential topic for many Rails developers. This concept is crucial for databases as it enables the splitting of data across multiple databases; however, this comes with its own set of challenges.
00:19:39.600
Sharding can complicate operations, especially when designing how to partition the data and how to work with joins across multiple databases.
00:20:10.320
Our strategy at Cloudinary involves leveraging a central shard for critical active data while distributing workloads by assigning clouds to distinct shards.
00:20:41.560
When you sign up for Cloudinary, you might get a dedicated cloud, representing its own independent workspace with dedicated resources.
00:21:00.840
Requests coming in are organized based on shards, allowing for efficient handling and simplification into our backend architecture.
00:21:32.120
For our application, we employ specific helpers to identify the appropriate shard during requests. This simplifies scaling while managing the complexities of data distribution.
00:21:53.920
Despite this streamlined approach, working with shards comes with complexities. Code bases can become cluttered with shard references, complicating maintenance.
00:22:18.120
Many Rails developers are aware of the kinds of challenges that sharding can introduce—it's essential to be conscious of how this affects data evaluations and ensure queries operate within the correct shard context.
00:22:41.520
Sharding provides flexibility, allowing us to cater to individual customer needs by placing clients with large traffic spikes on their own shards or grouping them together.
00:23:01.500
The next factor in our architecture, location, serves as the geographical distribution of our server network. This strategy ensures customers get the best performance possible.
00:23:26.660
Cloudinary maintains dedicated servers for different regions, allowing us to efficiently serve media closer to where the majority of users are located.
00:23:48.060
While we provide premium-level service to customers in the US, we also cater to clients across Europe and the Asia-Pacific.
00:24:05.880
We utilize dedicated databases across regions, which helps with performance issues. However, that introduces challenges regarding the primary database access for multi-region configurations.
00:24:30.960
In terms of updates, we implemented a near-real-time synchronization system—called NRT cache—where information is cached until updates are pulled from the primary database.
00:25:01.500
This setup leads to potential latency, but for most cases, updates synchronize quickly enough.
00:25:30.720
Despite these setups, challenges can arise. For instance, we had a spike in errors when migrating data across clouds due to simultaneous updates, which significantly increased traffic during that surge.
00:26:02.520
To manage these, we ensure thorough checks during code changes that may impact larger updates, aiming to find alternative approaches and minimize disruptions.
00:26:25.620
Ultimately, effective scaling hinges on managing individual customers' traffic without impacting service across the board. Rate limiting and throttling are key methods we employ.
00:26:56.880
Another factor for handling traffic spikes involves the fair queuing system: each job is assigned a number of slots, enabling us to fairly allocate processing power.
00:27:23.560
The system’s design helps streamline traffic during surges and efficiently utilize our computing resources, particularly for larger jobs.
00:27:44.960
In addition, implementing processes to mitigate the burden during spikes, including database access queuing and maintaining overall resource availability, enhances system resilience.
00:28:11.280
As with many systems, there are challenges regarding reliability. Our locking system, known as Lobster, prevents conflicts over transformations by managing read and write locks thoughtfully.
00:28:33.800
This lock is essential during processing to avoid any resource competition from multiple requests associated with a single asset.
00:29:00.760
Despite initiatives to ensure high performance through meticulous planning and failure protocol systems, managing failures remains a concern.
00:29:21.660
Finally, let’s touch upon human factors. By fostering an informed partnership with clients, we not only help them utilize our platform more effectively, but we can also encourage them to let us know about anticipated spikes.
00:29:49.020
Encouraging proactive communication about anticipated traffic increases permits us to scale our systems effectively in preparation for their needs.
00:30:13.560
Now, transitioning to the relevance of Rails—we acknowledge that the bulk of our requests don’t necessarily touch Rails directly. The performance-oriented tasks often reside outside Rails.
00:30:44.820
However, despite any language-based shifts in performance-sensitive areas, we still find Rails to be a highly productive environment for our development needs.
00:31:14.700
Our company initially succeeded using Ruby on Rails as the core technology for the first years, showcasing how effective it can be for startups.
00:31:47.760
At the same time, we continue to explore polyglot microservices, aiming to enhance our tech stack by integrating pieces conducive to our team's and project’s growth.
00:32:09.480
The aim is to ensure a collaborative environment where our engineers can work in languages they feel most comfortable with and find efficiency.
00:32:27.240
In summary, while adapting to new technologies presents challenges, embracing both legacy and modern tools will help us address future scalability demands.
00:32:51.480
I want to thank everyone for being part of this session, for listening, and for engaging fully. Your contributions are appreciated.
00:33:00.420
Feel free to reach out if you have any questions, and enjoy the rest of the conference!