00:00:19.439
All right, everybody! My name is Jeremy, and I also have copious free time. We're going to start by waking up. Joe told us a couple of different things yesterday that we need to do to get going in the morning. So, I'm going to have everybody raise your hands a little bit.
00:00:30.800
I've got some question-and-answer stuff we're going to do, and we need to ensure both your hands work. So, raise them both up! Come on, both of them up! I'll clap them. Do it a few more times. Come on, all right!
00:00:43.120
Is everybody getting ready and warmed up? All right, so wake up, everybody! I've got my applause early, so that worked out well. If you were hoping for the split face with a bald side and a hairy side, unfortunately, I had to take the mean and just kind of average it out.
00:01:00.719
I'm a bit of a data junkie. I enjoy looking at people's data to see what they have and understand what kind of things happen. My goal is to help them figure out something to do with it or get some really good information out of it. In general, I'm always looking for interesting data sets. A lot of the time, what we have are streaming datasets or just public data, but most of the really interesting data is people's private corporate data that they're not going to share with anyone. However, it helps them do better in their business.
00:01:38.880
So, a couple of survey questions. You're already hands-on, and I know you can do this. Raise your hand if you consider yourself someone who processes streaming data. We've got a few. All right, quick examples – anyone? Who here processes the Twitter stream? Who does not process the Twitter stream? Yes, okay! So we have log processing, Twitter stream, all sorts of stuff along those lines.
00:02:00.159
So, how many of you say you process batch data? Just one, two, three, four… all right! For those of you that process your batch data, how many of you think you process your batches more than once a day? All right, more than once an hour? More than once a minute? Maybe anyone processing more than once a second? We'll get into the definition of what some people call streaming data. You'll see a little correlation that's kind of interesting.
00:02:38.879
This is Big Ruby, so we have to use the term 'big data.' Like Matt, I'm not really a fan of the term; I think it's gotten a little bit of over-hype. But there is a new book out from Nathan Mars. Has anyone heard of Storm? So, there was a company called BackType, and they developed a whole system called Storm to process the Twitter firehose, and then they got bought by Twitter. It's actually a pretty interesting system; I've only played with it just a little bit, so further experiments are necessary. Nathan Mars and a co-author have a new book out for Manning called 'Big Data.' It's still in beta, so it's only half there, but it contains some interesting content.
00:03:26.720
I'll probably mention it a couple of times in the talk, but first, we're going to have a little bit of fun with the term 'big data.' This is Wikipedia's definition: a collection of data sets so large and so complex that it becomes difficult to process using on-hand database management tools or traditional data processing applications. I don't know who wrote that, but the interesting thing is that I did a talk on the definitions of big data about a year and a half ago, and this wasn't the definition at that time on Wikipedia.
00:04:00.560
For that talk, I tweeted, 'Hey folks, what do you think the term big data actually means?' and I got all sorts of interesting comments. Some of them included ideas like when data can't be processed in real-time or when data doesn't fit in memory. Everybody had different definitions, and to me, that kind of boiled down to one basic thing: if you're scared of it, it's big data! I mean, it sounds good because for me, big data means something that needs to fit on, you know, a dozen machines. I know how to deal with that; I'm comfortable with it. Something that requires 50 data centers to handle? Okay, that scares me. Someone else might get scared by data that fits on more than one machine, and so I think everyone’s term for big data is about the data levels that make them feel uncomfortable.
00:05:08.760
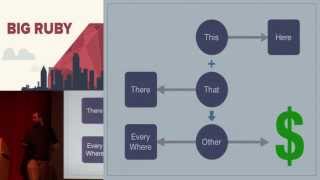
This is a model of a big data system or a data system. So, you start off with some data, and you need to store it. That's okay; that's the start. But when you have this data, you realize that you actually need that data located over there and need to store it over there as well. Now, here's where the real magic comes in: if you have this data and that data, and you put them together, you get other data. This other data is where the real magic happens because you're going to use that everywhere. Of course, as in any recipe requiring a couple of ingredients, what's the final step? Profit!
00:06:12.720
This is a sort of general scheme describing what happens. You get an initial data feed of something and realize you need something else to complete it. You combine these two to end up producing someone's data product or something they might be willing to give to someone else or use for internal analysis.
00:06:55.760
So, what do we mean by streaming? We go back to what the different batch levels people are doing, whether one minute at a time or one second at a time. Wikipedia has this definition of streaming data: a sequence of data elements made available over time, where the elements are processed one at a time rather than large batches. However, there is no definition of 'large.' What is a data element? A minute's worth of data? A second's worth? It depends. For my purposes, if you're taking data in periodically and consistently, that's streaming data to me.
00:07:31.760
If you look at that asymptotic curve, eventually it all leads to streaming data in one form or another. Also, if you recall Jim's flying robot presentation yesterday, he processed the data line by line; it was data packets. So technically, Jim was processing streaming data with those flying robots! We have robots processing data in our world, so just watch out. In my observations, I've concluded that big data and streaming data go hand in hand because the easiest way to attain a level of data that makes you feel uncomfortable is to have to acquire it all the time. You must deal with it constantly, address all the error cases, and handle everything that comes with accepting data from someone else or even your own systems.
00:08:39.440
This insight is conjectural, so take it for what it's worth, whether you agree or not. We can discuss it later. First things first: we have definitions before we engage in our discussions about streaming data. Any rogue fans in here listening to Ruby Rogues? Josh Susser is always saying that we start with definitions, so we started with some definitions. Now, what's the first thing we need to do when dealing with our data? Anyone?
00:09:02.720
I’ll give you a freebie: we need to get the data. It seems simplistic, but this is actually one of the more critical components of dealing with streaming data. Getting the data affects everything down the road; throwing a rock in a stream will ripple and affect everything downstream. We need to establish our sequence of data elements.
00:09:34.560
I've encountered about four different ways to obtain data from an external source. By 'external,' I mean outside of the data system you’re working with. If you're processing your own Nginx logs, those may be arriving via syslog and then aggregated and dumped into another system. You might also pull from the Twitter stream or other different types of systems. The first and probably oldest method is polling. Who does some kind of polling for data upstream or outside of a system?
00:10:34.960
Polling is a data system's way of asking, 'Are we there yet? Do you have data for me?' You go over and over again, and most of the time the answer is 'no.' Eventually, some data becomes available. One of the problems you encounter with polling is how to know if you’ve already received the data. There are a couple of different strategies I've dealt with, like retrieving scraped RSS feeds. In some cases, the upstream provider gives you a token—a timestamp—every time you grab a chunk of data. For your next request, you would send that token while requesting modified data since that timestamp.
00:11:09.680
Other places don't keep track of your location in the data. You need to request the data, then check it against what you've already retrieved. In some cases, an upstream provider may keep track of your state so you can request data without resubmitting, but I find that more rare. The majority of time, you keep track of your own token or state. There are a few problems with polling. We face similar issues with a couple of other mechanisms. I'll discuss all the negative aspects of the different data acquisition methods when I review each.
00:11:56.960
The next method, which is similar to polling, involves a notification or webhook system. How many people subscribe to RubyGems using webhooks? This is an excellent example of a notification system or PubSubHubbub. You're saying, 'Hey provider, I want to subscribe to a particular stream of data.' You inform them how to get in touch when you have data for me. When a new data point becomes available on the upstream provider's part, they ping you with a notification.
00:12:15.200
Interestingly, that notification doesn’t include the data you're trying to access; it simply informs you that there's data to collect. It’s like when the FedEx guy leaves a ticket at your door telling you, 'You've got a package. Come down to the store before 7 PM to pick it up.' A third method is quite similar: notifications contain the data you're supposed to retrieve. Most people are probably familiar with email—'Hey, you've got a new message, and here's all the data in it.'
00:13:13.440
Using email as a notification mechanism is very interesting. One of the best systems for disk queuing storage formats is maildir, since each message resides in a separate file. If you touch or read it, it simply moves to another directory, allowing for simple handling of your mail. So, maildir as a cue processing system is a fun method of managing the data flow. Payload is essentially a notification but with data; it shares some of the same problems as notifications that I will discuss later.
00:14:17.679
The push model is what everyone knows about, particularly with Twitter. How many of us have processed or half-processed Twitter in the past? There's a variety, whether it's a public feed, a ten feed from Gnip, or the actual full firehose. Twitter is a push system, as are Netflix and other streaming systems. Within a push system, you open up a socket, typically authenticated, and then the data gets thrown at you.
00:14:57.760
Let's start with some downsides. We've mentioned these four different methods of acquiring data. Each has its advantages and disadvantages. Polling has the drawback of requiring you to manage your own state; you need to know where you are and what you have retrieved. Notifications and payloads have a different problem: while polling gives you control over everything, with notifications and payloads, you must be there to listen for messages.
00:15:31.200
If you're not there to receive the message, both methods require a persistent setup that's always available. Whether you are the data provider or consumer, both sides have overhead. It depends on whether that overhead is deemed significant based on the contractual relationship between the two parties. Notifications and webhooks are effective methods; however, payloads also enjoy popularity, particularly within emails. Email offers a robust solution in terms of reliability.
00:16:19.440
Push systems, from my perspective, are the most brittle. You connect to a data stream to receive information. If you're not connected to that data stream, you won't receive any information whatsoever. In the case of Twitter, unless you're paying for Gnip's archival archival access, any data missed will be lost forever. You should understand that push systems can be demanding and unreliable.
00:17:05.360
One of my clients formerly processed the Twitter firehose. If our collector went down for a minute or two, that data is gone. Most of the Twitter content is essentially junk, so it doesn’t matter that much, but your customers may not grasp this. They pay for analysis on data; they do not understand the reasons behind the absence of the data. Thus, it is crucial to ensure backup mechanisms are present during streaming data acquisition.
00:18:12.160
When dealing with data acquisition, you should think about primary, secondary, and tertiary methods. It's essential to have these methods in place, for they are fundamental for working with streaming data or any data types in general. While I don't have enough time for code examples, it's available on Copious Free Time GitHub repository. I can take a couple of quick questions or add a bonus segment if time allows.
00:19:34.560
I was reading this big data book, and much of the content resonated with familiar themes from earlier work. Those concerns include how the advent of big data echoes the conventional themes prevalent in data warehousing during the previous decade. This raises some intriguing points, suggesting that the big data phenomenon we've come to recognize is, in essence, a reiteration of long-established data warehousing concepts.
00:20:06.760
Notably, the authors contend that the largest benefit of the data warehouse foundation is accommodating future unknown requirements. This phrase strongly mirrors previous studies emphasizing the capacity for unanticipated requirements in large datasets. Ultimately, you cannot generate new insights from data you don’t possess. The prudent perspective is to maintain robust archival processes that ensure all data remains accessible for future inquiries, enhancing your analysis.
00:20:53.759
Concisely, my sentiment is about the importance of having data readily available—this allows for new discoveries and prevents lost opportunities due to past oversights. It serves as a safeguard against erroneous assumptions, further illustrating that preparedness is crucial in managing big data and streaming environments.
00:21:05.000
I appreciate your attention—thank you!