00:00:00.030
Thank you for coming to my talk. My name is Petr Chalupa, and I work on TruffleRuby, which is part of a research organization with Enrico.
00:00:06.899
Before I start, I want to make sure you understand that this is a research project, so please do not make any investments based on what you hear today.
00:00:12.380
I will begin by introducing some of the technologies we are building on, then explain how we execute C extensions, talk about our old approach, and highlight the problems we encountered. Finally, I will discuss our new approach and how it improves our support for C extensions.
00:00:27.060
TruffleRuby aims to be a drop-in replacement for CRuby. We support C extensions, have improved startup times which are important for development, and offer just-in-time compilation. This generally makes us faster than other implementations. If you find a case where we're not, please let us know as it is usually just an optimization issue.
00:01:00.180
The name "Truffle" comes from a language implementation framework. It allows for specialization, which means self-modifying abstract syntax tree interpreters. Implementing languages with this framework is relatively simple and fast. Within the Truffle framework, there is a protocol that enables all languages implemented to communicate and exchange values without any transformation, thereby eliminating the usual barriers.
00:01:31.979
There is also an instrumentation API that, with some effort, can provide profiling and debugging tools. The way Truffle works is that it parses your language and transforms that into nodes. When it begins, all nodes are initialized, meaning no code has been executed yet. For example, if a node represents an addition operation, upon seeing its input values (like integers), it will replace itself with a different node specifically designed to efficiently add integers.
00:02:19.100
This process happens across all nodes, and once the tree of nodes is stabilized, it can be partially evaluated and compiled together. During this partial evaluation, the compiler drops out, leaving behind optimized machine code. We use GraalVM, which is a dynamic compiler written in Java. This allows TruffleRuby to leverage the powerful optimizations offered by Graal, including inlining and method cloning.
00:02:57.980
The last component is the Java Virtual Machine (JVM) that executes compiled methods provided by Graal. We bundle everything together into GraalVM, which is essentially one distribution of a Java virtual machine that includes the Graal compiler, Truffle framework, and various languages such as Java, Kotlin, Scala, as well as dynamic languages like JavaScript and Python. Additionally, as I'll discuss later, we support C, C++, and Fortran.
00:03:45.770
One of the other languages we support is Seulong, which interprets LLVM bitcode. This allows us to execute any language that can be compiled into LLVM bitcode, including C, C++, and Fortran, with a focus on C, as it's crucial for running C extensions. Our C extensions are executed within our runtime, which means we can optimize everything together. There are no language barriers to worry about.
00:05:53.870
We attempted to overcome a challenge in handling managed and unmanaged memory. Ruby objects are Java objects, meaning they are managed by the JVM and can be garbage collected. In contrast, native memory, like that allocated through LLVM, is unmanaged and cannot simply store managed Ruby objects.
00:06:10.490
Understanding the differences between managed and unmanaged memory is vital. When we execute C code, we often need to convert Ruby objects to unmanaged memory. This is one of the main challenges we are addressing in this talk.
00:06:21.500
The polyglot protocol, which is a feature of the Truffle framework, allows you to define functions on objects to facilitate communication with foreign objects in your language. For instance, when working with C code that interacts with a Ruby object, the C code can call a function to read members from Ruby objects using this protocol. This means that writing C code that interacts with Ruby objects can be done relatively easily while maintaining compatibility.
00:07:50.380
An example method taken from the zip standard library illustrates this approach. It utilizes Ruby objects stored in a struct and calls Ruby methods directly, requiring conversions to C types where necessary. In the past, we created handlers for managed objects and stored references instead of the objects themselves, which increased the complexity of memory management.
00:09:03.190
This handler-based approach led to the addition of numerous methods in the standard library to facilitate these conversions, resulting in cumbersome maintenance. We realized we needed to shift from unmanaged to managed objects as much as possible.
00:09:55.840
For example, we created managed Ruby objects that could represent structs, allowing us to avoid the need for frequent conversions between handles and managed objects. However, this still required some adjustments, such as handling pointers and calling initializers correctly. It was a step in the right direction but not sufficient.
00:11:34.060
Another significant issue was that C extensions held strong references to managed objects, complicating garbage collection. To address this, we had to analyze all C extensions to ensure handles were released properly. This was often not feasible due to the complexity of certain libraries, such as Nokogiri.
00:12:55.300
To solve these challenges, we implemented a system that wraps Ruby objects in a wrapper that specifies how to convert them to pointers. This allows for better tracking of object usage. When we call from C to Ruby, we unwrap any arguments first to get the actual objects, and we wrap the return values again.
00:14:56.090
As a result, we can run the code unchanged. By relying on this approach, we can handle C extensions more efficiently while maintaining compatibility with Ruby. Our examination of memory management in MRI revealed that it manages objects using stack marking and C data assignment.
00:16:21.750
We adopted a similar strategy by preserving references to Ruby objects when entering C calls. As we unwind the stack, we discard those references, thereby permitting garbage collection where necessary.
00:18:57.860
Our solution also involves implementing marking functions in a way that mimics MRI's approach. Each object that needs to be marked is tracked through a fixed-size list, and when this list is full, we run all marking functions to maintain strong references as needed. This ensures objects that need to remain alive are appropriately managed without leaking memory.
00:20:49.230
In conclusion, this process has significantly improved our compatibility with C extensions, allowing us to run many standard libraries and applications without modification. We can now use libraries such as OpenSSL, SQLite, MySQL, and others effectively without needing extensive patches.
00:23:14.650
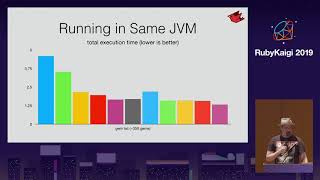
We've seen improved performance across various benchmark tests, and I encourage the Ruby community to experiment with TruffleRuby. Introducing smaller services with fewer dependencies is a good way to explore its capabilities.
00:25:15.370
I want to reiterate that while TruffleRuby is not ready for production use in all cases, it is suitable for experimentation with extensions running smoothly right now. You don’t have to rely on Java implementations but can use extensions more easily.
00:27:06.160
As I finish, I remind you that this is still a research project, and we are continuously monitoring and fixing issues that arise. Your feedback is significant as we work to improve our implementation.
00:29:47.180
I appreciate your attention and will be happy to answer any questions you may have. Thank you!
00:30:32.170
[
Applause
]