00:00:28.960
Welcome everyone to the presentation on understanding parser generators in Ruby, with a focus on contributions to Lrama.
00:00:34.920
Thank you for taking the time to join me today.
00:00:42.719
My name is Junichi Kobayashi, and I'm looking forward to discussing this topic.
00:00:48.320
I will be presenting on parser generators in Ruby, specifically my contribution to Lrama.
00:00:57.359
Let me start with a brief introduction.
00:01:05.400
My GitHub username is Jun612, and I work as a software engineer at ESM, where I'm part of the Ruby group.
00:01:15.000
In my spare time, I enjoy playing rhythm games and indulging in speed cubing.
00:01:22.360
Now, allow me to provide some information about my company, ESM.
00:01:29.960
ESM is a development company based in Japan, and I’m pleased to share that four of us are attending this event.
00:01:36.159
Our company is generously covering all travel and accommodation expenses.
00:01:42.759
ESM stands for System Management Insurance, and you can see our name written in Japanese in the slide.
00:01:48.640
I had a chance to explore some local attractions.
00:01:54.680
For example, I visited a shop named Soy Milk King, where I stopped by for breakfast.
00:02:02.280
I'm looking forward to this session and appreciate the opportunity to present.
00:02:08.599
Here’s an outline of what we’ll cover today.
00:02:13.680
First, I'll define some basic knowledge regarding parser generators, which is essential for understanding this presentation.
00:02:21.360
Next, I'll discuss my contributions to Lrama.
00:02:27.640
I'll then share insights into the internal structure that I encountered during the implementation.
00:02:35.400
Finally, I'll talk about my future goals concerning parser generation.
00:02:41.799
Let's start by discussing some basic knowledge regarding parser generators.
00:02:48.360
I will cover various topics including the components of parsing, which include lexical analysis and parsing techniques.
00:02:54.319
Moreover, I'll introduce some technical terms in programming language theory.
00:03:00.640
So, let's begin with the components of a programming language processor.
00:03:06.599
A programming language processor operates by taking source code as input.
00:03:12.360
For instance, the first function is lexical analysis which converts the source code into tokens.
00:03:18.919
Let’s consider a simple example: a class declaration in Ruby.
00:03:26.879
The tokenization process breaks this declaration into meaningful parts.
00:03:33.120
Next, we talk about parsing, which is a process that constructs the internal structure from tokens.
00:03:40.639
For instance, a parser will take tokens and build a structure representing the program's syntax.
00:03:47.879
There are different types of parsers and each programming language has its own unique grammar.
00:03:54.520
The output of the parser is crucial as it represents the structure of the code.
00:04:01.680
I'll now explain the terminology related to parsing and formal languages.
00:04:08.640
Formal language involves linguistics that deals with the structure of languages without their meanings.
00:04:15.479
It focuses on how languages can be expressed as a set of symbols.
00:04:23.320
Context-free grammar, a specific type of formal grammar, is used to generate complex languages.
00:04:30.000
These grammars are used in the BNF notation, which helps define language syntax.
00:04:37.119
There are two main types of symbols in these grammars: terminal and non-terminal symbols.
00:04:44.000
Terminal symbols appear in the text while non-terminal symbols can be replaced by other symbols.
00:04:50.960
Let me walk you through some examples of three grammars outlined in BNF.
00:04:57.640
For instance, we can represent numbers as sequences, where the number consists of two digits.
00:05:05.440
This representation shows a language that defines valid integer values.
00:05:11.760
The next example introduces arithmetic expressions, which utilize operations like addition and subtraction.
00:05:17.880
The language represented here includes a combination of digits and arithmetic symbols.
00:05:27.359
In summary, these grammars help define and validate structures of programming languages.
00:05:34.280
Next, I want to discuss my contributions to Lrama.
00:05:41.760
Lrama is a Ruby-based parser generator that I contributed to by implementing a 'Named References' feature.
00:05:47.760
This feature enhances the ease of writing and maintaining grammars within Lrama.
00:05:55.000
Lrama aims to provide functionality similar to other popular parser generators such as GNU Bison.
00:06:02.000
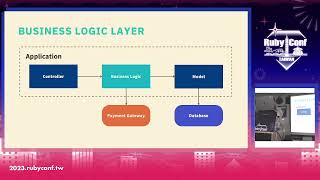
As I continue, I will delve into the internal structure of Lrama and how it facilitates its operations.
00:06:09.000
The diagram I created illustrates the journey of data as it moves through the parsing process.
00:06:17.000
This journey involves tokenization, parsing, and finally generating the output passed.
00:06:25.000
Through this system, the source code is processed to produce bytecode.
00:06:34.000
The significance of having a standalone parser generator like Lrama is its flexibility in handling changes.
00:06:43.000
This flexibility simplifies the integration of new features tailored to Ruby.
00:06:51.000
Now, let’s discuss named references in detail.
00:06:58.000
Named references allow developers to use symbol names instead of numeric positions in grammar.
00:07:05.000
This makes the grammar more readable and easier to maintain.
00:07:12.000
In the next section, I will explain how named references work in practice.
00:07:19.000
The use of names reduces complexity and the likelihood of errors during grammar adjustments.
00:07:28.000
Also, named references enhance the expressiveness of the grammar, benefiting future modifications.
00:07:34.000
I'll detail the implementation process for named references in Lrama.
00:07:41.000
Through systematic testing and refinement, I was able to ensure that linking actions to symbols works effectively.
00:07:49.000
The key was ensuring the context kept the state of symbol associations.
00:07:57.000
This aspect is crucial when handling various operations within the parser.
00:08:06.000
After implementing and testing, I submitted my changes to the repository.
00:08:14.000
Looking ahead, I plan to work on additional enhancements to the parser generation process.
00:08:23.000
A specific area of interest is working on the Iera algorithm, an improved version of the LLR algorithm.
00:08:30.000
I appreciate your attention, and I hope you found this presentation engaging.
00:08:38.000
Are there any questions about the implementation or the features discussed?
00:08:45.000
Thank you again for the opportunity to speak today.
00:08:52.560
If there's anything more you'd like to explore, I'm happy to discuss further!
00:08:58.560
I’m curious about how Llama and Prison will move forward, especially since they serve different purposes.
00:09:07.000
How can these generator systems work together to improve the Ruby ecosystem?
00:09:15.000
Your thoughts on the interaction between these approaches would be appreciated.
00:09:23.000
Thank you for your kind feedback and interest!
00:09:29.000
It’s certainly a fascinating area of discussion.
00:09:34.000
Are there any additional questions from the audience?
00:09:42.000
Thank you all so much for your attention and for participating today.
00:09:47.680
I look forward to engaging with everyone further during the event!
00:09:55.200
And enjoy the rest of the sessions planned for today.
00:10:02.000
Thanks again, and I hope everyone has a great time at the conference.