00:00:05.580
Hey there! My name is Martin. I’m from Uruguay and I’m a software engineer at Rootstrap. Today, I will be presenting a project that was assigned to our team and how Rails and its ecosystem helped us build it.
00:00:12.840
First, I'd like to go through the agenda. We will be talking about the New York Stock Exchange, then about the message-based architecture proposed to solve the problem, how I managed messages coming from it, and finally about risk mitigation techniques and tools for this kind of project.
00:00:16.800
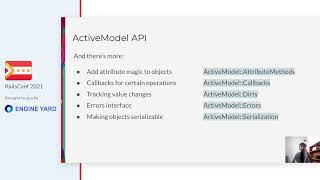
Key takeaways include message management introduction, an example of how to get the most out of ActiveModel validations, and the previously mentioned techniques and tools for risk mitigation.
00:00:35.219
A few months ago, our team was asked to create a mobile app that somehow connects to the New York Stock Exchange. For those who are not familiar with stock exchanges, we are essentially trading pieces of a company, called shares, each having its own price. The whole purpose of trading in the stock exchange is to buy shares of a certain stock at a given price, keep them, and then sell them at a higher price.
00:00:54.660
Pretty easy, right? Well, things can actually go south. Remember the news about GameStop? In that case, traders had to be fast enough to buy the GameStop shares before they kept going up. To achieve that, they needed a real-time application.
00:01:15.780
A real-time application, according to Wikipedia, is one that operates within a time frame perceived by the user as immediate or current. The latency must be less than a defined value, usually measured in seconds. This is what we were asked to build: a mobile app that could show the latest price at which a share was traded with as minimal latency as possible. Remember, this is the fastest-changing attribute of stocks; it can change up to ten times within a single second for each stock. Moreover, it should also be able to buy shares and display an updated chart of each stock's price history.
00:01:40.799
Then I asked one of the other developers how we were supposed to connect to one of the New York Stock Exchange servers. The answer was that they didn't want us to connect directly to the New York Stock Exchange servers. They informed me that they would be building middleware because they faced issues in the past with other third parties connecting directly.
00:02:06.420
When it came to the protocol we were going to use, they mentioned we should connect through TCP but not using HTTP. They had plenty of experience working on top of the TCP layer, which makes sense as it allows for a fast protocol, maximizing every single byte. They also informed us that we would need to connect through a VPN as all external services needed to follow that protocol as a security measure.
00:02:41.040
At first glance, we knew we had to communicate with open TCP threads to the middleware. So, first things first, we built an app responsible for managing the connection. It seemed to be working fine, but then we had to ensure that the app could manage models and relations pertaining to the domain we were dealing with. Furthermore, whatever we deployed should be able to handle HTTP and web connections from mobile devices.
00:03:08.880
That was the exact moment we said, 'Okay, no problems,' and we eventually added a Rails app that would also be connected to Redis, alongside other instances. The final question was: how do we communicate between the Rails app and the Ruby app? Our initial approach was to communicate both systems using HTTP— I mean, why not? But then, after some heavy thinking, we realized that may not be the best approach.
00:03:35.940
We figured that the middleware would send tons of messages to the Rails app, and it might not be able to handle that many requests at almost the same time. Additionally, what happens if we fail to process a request? If it were a price change for stocks, the user would end up with an outdated price on their app, which could lead to terrible results. We needed a way to declutter each message as fast and safely as possible.
00:04:00.600
Speaking about queues, we thought of using RabbitMQ. RabbitMQ is a message broker application that we can deploy anywhere, dedicated solely to managing messages. It's efficient enough that we can almost forget about performance, managing up to 44,000 messages per second.
00:04:28.620
Let’s walk through a use case. Suppose our Rails server starts receiving too many messages that it can’t return. We could add as many Rails instances as we want, and they would receive messages from RabbitMQ as well. All this can happen without informing the middleware that we are running another instance or, even better, if our Rails server goes down and we are unable to process any messages for a minute, RabbitMQ stores those messages until we can decode them as soon as resources allow.
00:05:20.320
Moreover, let’s say our Rails app becomes stuck while processing a message. In that case, we don’t want to lose that message as it wasn’t fully processed. RabbitMQ has another abstraction that will allow us to acknowledge that message. Only after we send that acknowledgment will it be discarded; otherwise, RabbitMQ will proceed to enqueue that message again until it is completely processed.
00:05:51.780
Now, let's overview a simple message flow to see how it all works together. First, we have incoming messages, those that come from the middleware—let’s say an update of a stock price. Remember that stock price reflects the last transaction price of its shares. This can change up to ten times within a single second. That message is received through an open connection of the Ruby app, which deposits the message in the RabbitMQ queue.
00:06:18.660
The Rails app then has tasks that pull from that queue, receive the message, and do what is necessary, like broadcasting the stock update message to all the WebSocket connections. We also have outgoing messages coming from the mobile app. When the Rails app receives one of these messages, it parses it, converts it into a protocol readable by the middleware, and enqueues it in RabbitMQ.
00:06:40.560
Meanwhile, the Ruby app is constantly polling that particular queue on RabbitMQ. As soon as a message is enqueued, it traverses through the TCP connection to the middleware. Thus, we have built a decent architecture for the communication flow.
00:07:03.060
Now concerning the messages sent to and from the middleware, we didn't have to worry about the security of the protocol since the communication with the middleware happened over a VPN. We only focused on the structure of each message. To achieve that, we suggested sending JSON over TCP.
00:07:27.700
We then agreed with the middleware developers that we would have different types of messages, for example, stock price updates, new orders, or even login messages. We needed to distinguish these messages. We added a filter in the JSON message called the 'action' field that would indicate the type of message we were sending. For example, the action for the stock update message would be labeled as 'stock update', while for the login request, we simply labeled it as 'login'.
00:07:51.660
For the login response, we decided to be a bit playful and called it 'login response'. Now let me share with you a full example of what a message looks like, specifically the stock update message. This is crucial for our application.
00:08:16.800
What about the logic inside the Rails application to manage these messages? We had to develop an easy-to-use abstraction to send messages to the middleware. And this is what we came up with; we just pass a message and that’s it! We’ll delve into the message class later, but first, let's look at the sender logic.
00:08:43.320
As you can see, the flow is pretty simple. We declare which queue will be used in the message and that’s it. I'm no wizard; I was able to accomplish this because Rails simplifies the process, and some brilliant developers created awesome gems for us to use.
00:09:06.720
Now, regarding receiving a message, let’s revisit the architecture. When the middleware sends a message to the Ruby app, it increases in RabbitMQ. What do you do with that message? First, we need a task that constantly pulls messages since we’ll be receiving messages all the time, many of which won’t even be requested, like stock updates.
00:09:30.240
After receiving a message, we will need to process it asynchronously since we must keep receiving messages. Furthermore, we need to handle each message depending on the action specified within. It’s not the same receiving a stock update as it is receiving a message indicating that a market has closed.
00:09:52.680
Similar to how Rails routes requests, when a new message arrives, we subscribe to that queue. Therefore, every time a new message arrives, it calls the router, which then takes care of it. If there is no route for that message, we raise an error.
00:10:19.620
The router defines a series of routes that map the messaging sections to the job that should handle them. When receiving a message, it retrieves the action and triggers the appropriate job to process it. For instance, if the incoming message is a stock update, the job could be called 'process Stock Update'. This job sends the stock update to all WebSocket connections subscribing to that stock.
00:10:44.520
As you can see, some messages are synchronous, and a slight delay can occur if several message instances are running at the same time. This can result in messages being processed incorrectly. For instance, it is crucial that a front-end receives a message indicating that a user has a new order to buy stocks before receiving a message saying the same order has been canceled; otherwise, the front-end might not even know which order is in play.
00:11:51.120
What we did may not be the best approach; however, it effectively solved our issues since the delay was minor and hadn’t impacted the stock updates—the messages that needed the minimum latency possible. So going back to our application, the mobile app connects to our Rails app using ActionCable and subscribes to certain stock channels so users can track real-time stock prices.
00:12:30.360
Every time we receive an updated stock price, we determine which connections are subscribed to that specific stock change and broadcast the message to all. This is done using ActionCable, which helps in managing WebSocket connections effectively.
00:12:55.620
Now let’s consider a user who notices GameStop shares are rising and wants to purchase some before it’s too late. We are now dealing with a different type of flow called a transaction. The user needs to buy shares and receive a response indicating whether the transaction was successful or if there were any errors.
00:13:24.000
At this point, the idea of using HTTP requests arises due to their transactional nature and reliability. However, we have to figure out how to inform the rest of the application of sending a message to the middleware while also mapping it back to our request.
00:13:46.920
One crucial point we needed to address was identifying whether a message from the middleware, indicating that an order was placed successfully or not, refers to the message we recently sent or another message entirely. Mistakenly, two users can place orders at the same time.
00:14:05.400
One option could involve having a field in the middleware messages to indicate the user to whom the message corresponds. However, this solution proves unreliable since other message types, like the login message, complicate the scenario. We need a reliable way to handle different messages simultaneously.
00:14:28.920
This was when we thought about using Remote Procedure Calls (RPC). RPC would allow a program to execute a procedure in a different address space as if it were a local call without the programmer explicitly managing remote interaction details. RabbitMQ manages this abstraction for us, allowing us to handle various scenarios.
00:14:59.520
After implementing the basic flow and working with real users, we encountered bugs in the communication between most of the services. Some messages we presumed would contain certain data didn’t, leading us to contact the middleware developers for documentation on the services.
00:15:35.760
They acknowledged that they didn’t have enough time for proper documentation but also highlighted various ongoing issues with bug-ridden messages, missing fields, and erroneous data. We suggested that they perform tests on their end, but they declined due to time constraints.
00:15:59.520
This left us in a challenging position. We needed to maintain documentation about a system we didn’t have access to while also figuring out how to mitigate risks before our front-end engineers flagged issues with our code.
00:16:20.280
When something went wrong, the front-end engineer would investigate the issue, and upon confirming the backend code was functioning correctly, they would ask us if we’d made any changes. This led us to reproduce the errors and, eventually, track middleware messages for discrepancies.
00:16:40.440
To keep track of all incoming and outgoing messages from the middleware, we logged each message. This record helped us establish solid proof when something from the middleware seemed incorrect. Once we collaborated with the middleware to fix their errors, our system stabilized.
00:17:01.920
We realized that it would be beneficial to document all messages, detailing what data we expected in each. After a considerable effort, we created a comprehensive document that aided new team members in understanding our protocol.
00:17:29.220
We still needed to keep updating this document whenever new messages were added or existing messages changed, which became increasingly frustrating and time-consuming. We then started implementing checks in the received messages.
00:17:47.640
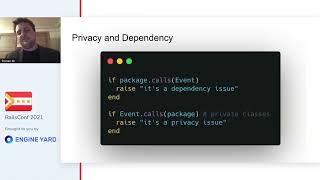
For instance, we expected the stock update message to contain a field called 'last' that should hold a number. While developing this solution, we found it mirrored our ActiveModel structure whereby we validate fields representing numbers, string values, or greater-than-zero constraints.
00:18:06.420
Instead of reinventing the wheel, we decided to utilize ActiveModel validations for our message validation. We created a new class called 'ReceiptMessage' for each message type. Upon initializing one of these messages, we proceed to validate each attribute using a designated validation class.
00:18:29.760
Let’s take a look at one specific class, for example, the Stock Update class. First, it maps the attributes to make them human-readable, akin to creating aliases, and then it applies the same validations familiar from ActiveModel.
00:18:59.760
As you can see, we insist on the presence of the action, alongside checks for presence and numericality on certain other attributes. In the background, it includes the model and validation models; thus, when it initializes, it maps each value for human readability and validates them via the valid method.
00:19:17.460
If validation fails, it raises an error with all relevant information attached. Once we integrated this logic, we reduced the time to identify issues significantly. We could know not just when but also what had gone wrong.
00:19:37.440
This approach proved so effective that we decided to apply the same concept to messages we send to the middleware with a class named 'SendableMessage'. Each time a sendable message was formed, we validated it before dispatching.
00:20:01.320
However, a key element was still missing: we required a tool to be notified about validation errors. This is where we integrated the Exception Hunter gem, akin to Sentry, but hosted on our Rails app. We linked it with our Slack platform for real-time notifications whenever an error was raised.
00:20:26.520
Now we have a fully integrated Rails application capable of managing both transactional and non-transactional messages effectively.
00:20:50.880
But what about performance? One major challenge for a real-time application was to manage stock updates. Hundreds of updates can occur in a single second, and we need to develop an algorithm to reduce the quantity of updates sent to the front-end.
00:21:06.840
The price changes occur so quickly that it can frustrate users. Hence, each time we receive an update for a particular stock, we maintain it in memory, waiting for additional updates before sending it out.
00:21:24.600
We decided to merge the previous update and only send this to the front end three seconds after the first update was received. This was facilitated with the help of Sidekiq.
00:21:56.760
Another challenge involved sending stock charts along with stock information. Often, users wanted to see both the current price and the historical chart to gauge the stock's behavior over time.
00:22:22.560
We discovered the excessive back-and-forth requests with the middleware and resolved to cache the chart data using Rails cache over Redis.
00:22:41.640
Regarding the project’s stability, we ensured the application was stable and devoid of downtime. One complexity was that the middleware only had a single production environment, meaning any changes made would require all environments to function without issue.
00:23:04.560
The developers of the middleware provided a set of users for testing, which was beneficial since all investments were returned at the end of the day. However, it limited our ability to test cases beyond daily resets of users.
00:23:26.040
It wasn’t until we pushed into production that we discovered flaws. And often, things didn’t work as intended, which necessitated rolling back changes.
00:23:46.740
What we were keen to avoid was deploying flawed code that could lead to significant costs. Finding a balance between mitigating that risk and delivering consistent value to users became imperative.
00:24:06.300
Often, we introduced new versions with fresh features, tested them in development without issues but faced unexpected problems upon production deployment. This demanded rollbacks, delaying new releases until we fixed every issue.
00:24:24.720
To handle these issues effectively, we utilized feature flags through a gem called Flipper, which managed feature status for us. Whenever we deployed, we kept all flags off, reserving them for quality assurance testing.
00:24:52.560
Only after receiving the necessary approvals did we activate the flags for a few beta testers and subsequently turn them on for all users. Thankfully, Flipper also allows us to manage user access, user groups, or even percentage-based activation.
00:25:15.720
This grants us full control over features while ensuring they can be deactivated at any moment. But Flipper’s most noteworthy feature is, without a doubt, its configuration for users versus non-users in our application.
00:25:39.840
Above all, when developing an application managing substantial financial operations, we have to sleep soundly. Beyond being programmers, we are still humans. Therefore, having effective testing is crucial for success.
00:26:00.960
I proudly report that 98% of our code is tested; however, having comprehensive tests alone isn’t enough. It may sound repetitive, but combining a robust test suite with reliable automated deployment practices creates a reliable approach.
00:26:18.720
If we aren’t cautious, things can take a turn for the worse. Allow me to summarize a similar app experience with nearly $400 million in assets that went bankrupt within 45 minutes due to a failed deployment.
00:26:37.560
In July 2012, engineers at a global trading financial services firm planned to deploy a new functionality for dividing large orders, termed 'parent' orders, into smaller 'child' orders that allowed users to buy from multiple providers.
00:26:56.760
While constructing this functionality, engineers inadvertently utilized an outdated block of code that hadn’t been active in eight years. They mistakenly leveraged a flag that was meant to be off.
00:27:10.200
When deploying to the production server, seven out of eight engineers updated their servers correctly, but the eighth engineer missed the update.
00:27:27.300
When the market opened, the server running old code started making endless new orders because the power-pivot functionality no longer worked as intended.
00:27:45.960
Within a minute, engineers sensed a significant malfunction but could not pinpoint the error. They ultimately redeployed the code across all servers, resulting in an even worse failure.
00:28:03.720
Within 45 minutes of the market opening, the firm lost $460 million and went bankrupt due to the unexpected success of the previous untested functionality.
00:28:27.120
So indeed, things can easily go wrong if we do not exploit the automation and tools at our disposal. Mitigating risk remains our primary responsibility.
00:28:56.520
In conclusion, we successfully managed the risks of a high-frequency trading platform by utilizing ActiveModel validations for every message entering and leaving the system, leveraging RabbitMQ for robust message delivery, ensuring high server availability, and effectively caching data to regulate update flows.
00:29:17.520
Moreover, we instituted active monitoring tools for real-time alerts about system failures and maintained a solid set of tests coupled with thorough quality assurance practices while implementing feature flags for safer continuous delivery.
00:29:37.920
Thank you so much for your time! I'm Martin Jaime, and this concludes my RailsConf 2021 talk.