00:00:10.880
Hello everyone! Today, I want to share a real-life experience of rewriting a product four times. My name is Leon Hu, co-founder and CTO at Dockable.
00:00:15.120
There’s often a short answer to any trivial question. Perhaps it’s similar to the answers I give my non-engineering wife before bedtime or what I tell my nerdy friends over beer. But certainly, none of these explanations would suffice in an investor meeting, as any of those answers would likely get me fired. Let me give you some background about Dockable.
00:00:37.040
We deal with software that was developed in the early 2000s, striving to extract as much data as possible for automation. This allows care providers, like your average dentist, to avoid playing phone tag with their patients by handling appointment reminders seamlessly. We are headquartered in San Diego and have customers spanning all 50 states. Although our customers love us, sometimes they forget that Dockable exists, and why. This is because our automation solution works silently in the background—confirming and reminding patients about their upcoming appointments, and checking in patients as they arrive.
00:01:10.240
Our team is small, consisting of six individuals with two to three developers. Everything we build comes from a place of love and extreme care. Now, let's dive into what has turned out to be a seemingly trivial product that we ended up rewriting four times.
00:01:38.000
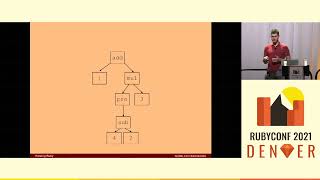
I'm sure all of you have received text messages reminding you of upcoming appointments. For example, a simple message might say, 'Hi Sarah, just a reminder that you have an appointment at 3 PM tomorrow. Sincerely, Smile Dental.' Our initial approach to the appointment reminder system involved roughly 15 lines of code, which most developers can easily understand. All you need to do is ensure that each appointment is linked to a patient, who is in turn linked to a practice. When it's a day before the appointment, you simply call `appointment.remind`. It's almost a plug-and-play solution if you integrate it with an SMS vendor like Twilio.
00:02:05.200
However, this is where things start to get complicated. Based on customer requests and issues, we encountered several challenges over the past three to four years. For instance, some customers wanted different scheduling intervals for their reminders. What if patients want to be reminded multiple times before their appointments? Or, what if multiple family members share a phone number with their guarantors? Do they get spammed by multiple texts? It's important to consider additional complexities like special instructions that need to be embedded in the reminder messages or the scenario where a patient cancels right before their appointment.
00:02:29.280
We also experienced a good problem to have: what if your product starts gaining traction and you need to scale quickly? Initially, our MVP was just that—an MVP consisting of about 15 lines of code. Still, it took about a week of work to complete. We pushed the system to production and celebrated with high fives, looking forward to the sales that would roll in. But that calm lasted only about five days before we realized that many families share phone numbers and appointments, leading to confusion for our customers.
00:02:51.680
Our first data model was naive; we assumed each patient would have their own phone number and that they wouldn't mind receiving multiple reminders in a day. We soon found it was essential to separate appointments for different dental professionals, like hygienists and doctors, as they are distinct entities within their own databases. Consequently, we had to redo our data modeling and migrations, which turned out to be significantly more challenging than anticipated.
00:03:14.320
Thus began our first rewrite, which was undoubtedly a major improvement over our initial experience. The simplicity of a single message ensured that patients thought, 'Hey, that's a pretty clean solution!' However, our second rewrite came with even more pressure as sales picked up and customers praised the user-friendliness and accuracy of our reminder software. Just as we began building another product, performance bottlenecks started to emerge.
00:03:35.520
At that point, our performance monitoring tools were minimal. We were overloaded with requests as we attempted to pull all future appointments needing reminders every five minutes. Consequently, our job server reached memory stress, and our database was overworked, blocking other important operations. We even missed traffic, which was a significant concern for us. It was a wake-up call. After addressing a few immediate bottlenecks and scaling back some features, we bought ourselves a couple of weeks during which we examined every possible approach.
00:04:06.080
During that time, we set up our Datadog monitoring on our big screen TV alerts dashboard and tackled the challenges of our second rewrite. Fast forward a year or so—we thought we were in a good place, only to face our final rewrite. The goal at this stage was to create a comprehensive reminder system that could accommodate multiple reminder schedules and adjust messages based on the attributes of each appointment.
00:04:29.200
The challenge was that it needed to be fast and accurate since we were dealing with about half a million patient messages daily—a pretty tall task. So, we took the necessary time to explore options related to architecture, data modeling, migration, and executing customer migrations in batches with additional tools. We incorporated many tests and iterations to prepare the system for high performance.
00:04:49.200
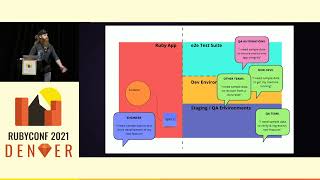
Ultimately, we settled on using an event-driven architecture. This design pattern leverages the production environment to detect and react to events that occur in real time. It enables minimal coupling, making it an excellent fit for modern distributed application architectures. This method focuses on generating and handling event notifications, which is ideal for our use case, where knowing about appointments and their details is crucial.
00:05:12.240
The event manager is responsible for organizing all the information into a processable entity ready for the event consumer. Since our services are decoupled in an event-driven architecture and each service typically performs one task, identifying bottlenecks becomes straightforward. This leads to efficient scalability of our services when needed.
00:05:35.040
This model achieves high performance through its asynchronous capabilities. It allows for parallel operations, thus reducing the polling cost for information. That being said, I want to share some key lessons we've learned and a few tools we've utilized along this journey.
00:05:58.960
With numerous time-based use cases, we have found that test-driven development truly benefits our work. However, visualizing all the complex use cases in our specs can be challenging. We explored several options and adopted Fitness, a wiki-based testing tool which our QA testers can utilize to create test cases effectively. Additionally, don't make language a barrier to project success. It's essential to remain open to different languages and tools, ensuring that they serve the project's needs.
00:06:18.080
One significant lesson we learned was to be willing to invest in APM (Application Performance Monitoring) software. Initially, I tried to save costs, but once we encountered performance bottlenecks, I realized that these tools proved their worth immediately. Simple log tracking isn’t enough; they become invaluable when identifying deeper issues before they escalate.
00:06:39.680
We also had to improve our awareness of memory usage. While Ruby is not known for low memory usage, we quickly discovered that our Ruby on Rails applications could suffer from substantial memory consumption. Sidekiq, a popular Ruby background job processor, can also lead to significant memory growth, which is why we began paying closer attention to our memory usage.
00:07:03.680
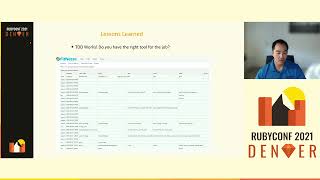
By experimenting with different allocators, like Jemalloc, we managed to contain our memory growth significantly. Alongside that, we also learned to monitor our top ten poorly performing queries consistently. This should become a habit and a regular review point with your team. We utilized free tools like PG Hero, a performance dashboard that works smoothly with PostgreSQL, to help monitor database performance.
00:07:29.280
It’s essential to have routine reviews of your database and adjust your volume to enhance IOPS accordingly. Also, when discussing job processing, it’s crucial to spread non-critical background tasks throughout scheduled intervals to minimize concentrated loads on the database, while improving overall performance.
00:07:49.760
In our case, we developed a simple module to scatter jobs across a defined time frame, which proved to be incredibly beneficial. Additionally, we began paying more attention to our outbound API requests. When unable to spread background jobs effectively, optimizing API requests via parallelization became another focus area. We found the Typhoeus library, which wraps around libcurl, helpful. This allows us to retain open TCP connections, significantly improving performance.
00:08:15.280
Moreover, defining clear timeouts for external API calls is crucial to prevent resource exhaustion caused by potentially misbehaving third-party APIs. If such APIs time out unexpectedly, they can consume all available resources, blocking all traffic. When it comes to our database, if you have a master-slave database setup, leverage replica databases for read-only endpoints. Reading from replica databases can significantly alleviate load on your primary database.
00:08:38.160
We created wrapper modules to incorporate relevant read endpoints into our application while ensuring that monitoring tools oversee database performance. It is equally important to reduce stress across the platform, utilizing pushing mechanisms instead of pulling wherever possible. These tools allowed us to develop a high-performance real-time application with Ruby.
00:09:05.920
We achieved this by offloading low-level responsibilities such as handling sockets and broadcasting data to other languages. While we typically lean towards the microservices pattern, we highly recommend not confining low-level workload to Ruby.
00:09:32.720
As we approach the conclusion of this talk, I want to share several considerations and principles which have been valuable throughout our journey. These tips aren’t universal for everyone present but reflect best practices we adopted along the way. Don't give up; keep seeking the right tools to provide performance insights. Achieving enduring performance is a laborious process, requiring significant effort from various expertise within your team.
00:10:13.720
The challenges of performance are always present and impactful. It's critical to understand your scaling needs. Sharing this knowledge with your leadership and business teams fosters what could be a successful, scalable product. I extend my thanks to the talented team at Dockable who contributed their efforts to this project and to the compilation of these slides. We couldn't have done this without their dedication.
00:10:53.560
Before I conclude, I would like to share a personal note: we are hiring. We have multiple engineering positions open, and we’d love to hear from potential candidates eager to join our team at dockable.com/careers. Thank you for your time.