00:00:08.840
Well, can't they start? My name is Seyed Nasehi, and I work at Cisco. Today, I'll talk about why you should avoid identity sync like wildfire. This presentation is based on my experience building identity and authentication services at Cisco.
00:00:20.360
I'm going to give you a fictionalized version of what we learned. So, meet our heroes: Zoe and Chloe. Both are developers but they reside in two parallel universes.
00:00:36.140
They were tasked with creating authentication services for their respective companies. The requirements were the same, but they ended up building very different systems. Let's start with Zoe.
00:00:56.030
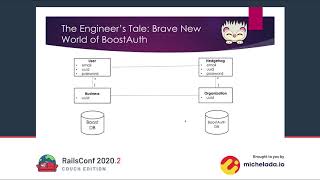
Once upon a time, there was a very smart developer named Zoe. She was working on a service called Boost that provided users with health and safety information. This service was built using Ruby on Rails.
00:01:05.560
Customers could buy licenses to have their information stored in Boost. When licensing was completed, a record of the business was created, allowing them to add multiple users who could log in and access the services of Boost.
00:01:18.860
Zoe was a happy developer, and over time, more customers joined Boost, leading to an increase in revenue and user engagement. However, some users began to ask why they needed to create yet another password in a different system.
00:01:45.079
Initially, users needed to create an account with their email as their user ID and save a password, which was securely stored in the database. However, many users already had existing accounts elsewhere, leading Zoe to question why they could not leverage those accounts.
00:02:22.450
Thus, Zoe decided to implement a service called Single Sign-On (SSO). This allowed Boost to either become its own identity provider or connect with another existing identity provider. Users would log in via Boost's login page, choose SSO login, and be redirected to the registered third-party IDP.
00:02:49.510
Once authenticated, the IDP returned a response in the form of an XML known as a SAML response, which Boost would process. If the SAML response was valid, users would be redirected to the main page of Boost.
00:03:10.310
This implementation was very successful. However, there were now more products and services under a larger company umbrella. The top management recognized a similar issue: each service had its own user accounts and passwords, requiring users to have separate logins.
00:03:47.390
The decision was made to create a centralized authentication service, and Zoe was tasked with developing this solution. The new service would act as an identity provider for multiple products and services, also referred to as service providers.
00:04:13.370
To begin, Zoe extracted all existing logic from Boost and implemented it in a new application called Boost Auth. In Boost, the main models included the user's email as the username and their encoded password, both linked to a business.
00:04:55.560
However, Zoe wanted to create a separate new database with a different password encoding scheme. Since passwords were encrypted in Boost and she could not read them, she developed an access system that could work with both databases.
00:05:17.590
While maintaining the models from Boost, she created new models for the new Boost Auth database. Additionally, she decided to rename the new user model to 'Hedgehog' and represented what was a business in Boost as 'Organization'.
00:06:10.000
When a user logged in to Boost Auth for the first time, if a record existed in the Boost database, they were authenticated against that, and a new record was created in the Boost Auth database with the same email, user ID, password, and organization. This established a one-to-one relationship between Hedgehog and the organization.
00:06:43.230
However, this was not Zoe's ultimate plan. She wanted to fully separate the new application from the old database. To achieve this, she needed to create services for Boost, as it still had its own user management pages.
00:07:38.520
Deep into her research, Zoe explored a standard called SCIM, or System for Cross-domain Identity Management, which had various RFCs. Upon discovering that there were no Ruby implementations, Zoe decided to build her own.
00:08:30.700
Phase one of her implementation was focused on the essential subset of SCIM that would allow Boost to communicate with the new service. After this implementation was in place, the architecture looked like this: Boost had access to both its own database and the Boost Auth database, along with the new SCIM API.
00:09:48.880
When attempting to add or remove users for different businesses, Boost called the SCIM API. This process allowed information to be retained in both databases, facilitating eventual removal of dependencies on the old database,
00:10:34.120
As developments progressed with Boost, the team faced new challenges. They received requests for additional functionalities but were also under pressure to integrate SCIM fully. This made them miss an opportunity to complete the integration with other services.
00:10:59.250
In the meantime, users were being created via Boost Graph, with their information pushed into the Boost Auth database without corresponding updates in Boost. This resulted in unique user IDs being generated in Boost Auth that did not align with user IDs in Boost.
00:12:21.110
Consequently, misunderstandings arose over user access permissions. Users who had accounts across services ended up being unable to log in or were denied access, leading to a lack of user satisfaction.
00:13:03.660
To remedy this, Zoe determined to ensure that a user’s email address, which served as their login ID, would apply to the same organization across services. Validation checks were introduced to verify whether users were existing in both databases.
00:13:47.720
However, upon releasing these changes, many users complained that they could no longer access either Boost or Boost Graph. Upon investigation, it became clear that Boost was not retrieving current user data from Boost Auth.
00:14:41.780
New user information was written into Boost Auth, but it was not communicated to Boost. Hence, when users were added through SCIM, it did not check the Boost database, contributing to the user login issues.
00:15:45.120
To resolve this, Zoe and her team decided to alter the logic for adding users in Boost so that they would access the SCIM API when users were added. If a user with the same email address existed but linked to a different organization, this violation would prevent them from being added.
00:16:39.140
Unfortunately, many customers did not understand why they could not add users due to mismatches across databases, leading to confusion and dissatisfaction.
00:17:40.520
Another disastrous scenario emerged when users attempted to change their email address, which served as their username. This created difficult synchronization problems across services since altering emails in one service required updates in others.
00:18:50.780
Zoe was frustrated and wanted to avoid such pitfalls, so she resolved to work smart with Chloe.
00:19:51.570
In the parallel universe, Chloe was also asked to build an identity provider. Unlike Zoe, Chloe had a secret weapon: a time travel device. She could see the consequences of her design decisions.
00:20:51.980
She envisioned similar requirements but wanted to adjust after seeing the future. Chloe traveled forward in time and saw a disastrous outcome with her identity provider. Users struggled to log in, and the overall experience was poor. This led her to reconsider her initial designs.
00:21:58.620
Chloe noted several key issues: first, the replication of identity information across multiple services was overly complicated and prone to errors. Second, maintaining synchronization between multiple databases created continuous problems.
00:23:10.560
She realized the updated user IDs across organizations created discrepancies and inefficiencies. Thirdly, she understood that relying solely on the SCIM standard was risky, as it added unnecessary complexity without adequate benefit.
00:24:06.470
From these observations, Chloe decided to change her approach, discarding the design that led Zoe to so many pitfalls.
00:24:46.340
She chose to extract the authentication logic from Boost entirely. She opted for one centralized database to avoid the pitfalls of double coding passwords and manage user names without synchronization issues.
00:25:54.080
Chloe also understood that allowing users to belong to multiple organizations could facilitate better access to services. Each organization could still register for various services without needing extensive UI elements.
00:27:18.220
Thus, during the authentication process, users would log into Boost or Boost Graph. The application would send a request to authenticate against Chloe's new service, which checked their credentials.
00:28:31.730
Successful authentication and authorization meant the user could access the requested services. The system efficiently utilized the unique user IDs to ensure proper authorizations and aided in checking existing users.
00:29:41.650
Chloe designed an endpoint for services to register and receive updates when any authentication-related information changed in Boost Auth. This approach simplified the user experience.
00:30:46.740
Everything was managed within a centralized system that avoided the need for constant synchronization across different services. This design led to a significantly improved user experience where users were happy and satisfied.
00:31:50.330
To summarize what they learned: sometimes, adopting standards blindly may not always yield positive outcomes, especially if not widely accepted. Additionally, syncing identity-related information among multiple services can create complications.
00:32:49.670
Centralizing authentication information in one system can considerably ease operations and enhance the overall user experience. At the end of this presentation, I wish to express my gratitude to my friends and coworkers at Cisco, particularly to the creative minds who contributed to this project.
00:34:55.210
If you have any questions, please feel free to contact me. Stay safe!