00:00:10.800
Thank you so much for coming. A bit about me: my name is Jade.
00:00:16.320
I'm a software engineer from London. I got really interested in optimizing code during my second development job, and that interest has continued ever since.
00:00:23.359
This is me at home with my dog, Cubby. She is a Shiba Inu.
00:00:31.279
I'm going to start off with some background for this workshop. We will first look at how to find slow pages, then investigate why they are slow. At this point, we will also have some exercises.
00:00:37.760
This workshop is called 'How to Use Flame Graphs to Find Performance Problems.' But first, let's discuss some background.
00:00:43.440
Let's think about why we actually care about the performance of our applications. Firstly, a website that loads quickly offers a better user experience.
00:00:50.160
You don't want users waiting around forever for something to load. The impact of slow loading times on customer-facing pages can decrease conversion rates.
00:01:04.000
A straightforward way to assess this is to look at the drop-off rates on pages that are slow within your sales funnel or sign-up process.
00:01:10.799
Another reason performance is important is due to server costs. If you have slow code in heavily used parts of your site, it will naturally lead to higher server costs.
00:01:18.000
If you can optimize that code to be faster, it will help lower those costs.
00:01:31.920
Additionally, if there are performance problems in your system, you can expect errors to arise during peak traffic. I will talk more about this in the second half of this workshop. For now, let's keep this in mind.
00:01:44.960
So, this is my dog in profile.
00:01:51.119
Now, let's talk about why we need to profile applications. We need to get a realistic view of what is causing slowness. Speed intuition can fail; you may have experienced reading some code and thinking it would be slow, only to find it actually isn’t.
00:02:09.200
Similarly, we may not catch slowness in code reviews. Additionally, as products grow in success, they may slow down over time. You might not realize code becomes slow until a later stage.
00:02:26.800
You could deploy something that performs well with a few thousand rows in your database but starts to crawl when scaled up to 100,000 or even a million rows.
00:02:39.519
Therefore, we want to gather data on what aspects of the page load are causing slowness.
00:03:05.840
Having briefly covered why we need to profile applications, let’s delve into the tools. Many of you will already know that we use a profiler to collect data on all the code executed when loading a page or calling an endpoint.
00:03:19.519
The profiler interrupts the process momentarily to report what it is currently doing. For example, it may tell you, 'I’m currently in the middle of initializing a method,' or 'I am executing a database query right now.'
00:03:31.519
This information is collected over time and compiled into what we call the profile, which we can then visualize using flame graph tools.
00:03:58.319
Some common Ruby profilers include RBSpy (by Julia Evans), Ruby Prof, Stack Prof, and Rack Mini Profiler, which is what we'll be using throughout this workshop.
00:04:10.480
So we’ve covered the 'why;' let’s look at the 'how.' This is what you’re here for, essentially. First of all, it's crucial to be realistic about the time you have for performance work. You want to focus your efforts on areas that will yield the most benefits.
00:04:36.639
You can follow an elimination process to identify slow code. Any changes you make should be tested on your local machine to see if they improve performance, have no effect, or – in some cases – worsen performance.
00:05:00.000
If that's the case, please avoid merging those changes.
00:05:10.720
When prioritizing areas to speed up, focus on pages that are both heavily utilized and slow.
00:05:30.000
Imagine you've already raised a pull request to speed up a page. You'll want to clarify in that pull request not just what you did, but why you did it.
00:05:55.120
It’s important for those who may not have recognized the significance of page load speed, which should be a priority for everyone.
00:06:07.680
I mention this because you'll likely have other demands on your time; so, it’s better to focus on optimizing areas that are heavily used and taking more time than they should.
00:06:20.639
Consider the impact efficiency will have: for example, if you find that an internal report takes 100 seconds to run once per month for one person, that’s not the best place to start.
00:06:40.639
On the other hand, if vital pages like your homepage or payments pages are taking 100 seconds to load, optimizing those is certainly critical.
00:06:56.919
Also, consider the business context you're operating in to make better decisions.
00:07:13.920
For example, certain key pages will generate business problems if they are slow. This should not only be seen as inconvenient; it’s a real business issue.
00:07:30.000
You should also consider your user base. For instance, can you rely on one type of user to continue engaging with the site while others could easily switch to a competitor?
00:07:46.800
Take internal applications as an example – internal users may tolerate slower load times more so than potential customers. But if this happens during key processes like sign-ups or conversions, then it’s problematic.
00:08:06.080
These considerations will guide your prioritization decisions. Much of this is dependent on your specific business environment, yet the goal of identifying the slowest pages will remain consistent.
00:08:26.400
Now, let's talk about how to identify those slow pages. You will want to compile an ordered list of your worst offenders.
00:08:39.999
To accomplish this, look at real user results using a tool like New Relic. You should analyze web transactions that take the longest time.
00:08:58.240
I advise looking at web transactions and not non-web transactions because if you've decided to process something in the background, you likely do not need that process to complete immediately.
00:09:15.480
Instead, focus on immediate user interaction where they require a response.
00:09:30.640
I’m not going to go into the specifics of New Relic at this moment. Instead, I’ve selected examples of the most time-consuming endpoints, ranked relative to each other.
00:09:47.760
It’s important to realize that while one action may rank higher in resource time, that does not necessarily mean that it is slower than another.
00:10:03.200
You may find that the average response times are not exceptionally slow; they’re just very frequently called, which can compound the perceived slowdown.
00:10:21.600
You also want to think about which issues will have the highest impact from your product's perspective. Use that to guide your investigations.
00:10:41.919
Consider architectural elements that may play a role if relevant; for example, if some services are tied to an upstream application or sales processes.
00:11:01.920
Now that you have your list, you will want to drill down to figure out where time is being spent. If you’re using New Relic, it’s relatively straightforward.
00:11:19.040
Scout APM is also effective and free for open-source projects, so if you have a public GitHub repo, it is worth investigating.
00:11:30.640
As for front-end time spent, I won't cover every framework in detail here. However, it’s possible to find backend processes running quickly while frontend performance lags. Recognizing this gap is vital.
00:11:43.920
I’ll be sharing resources at the end to help you navigate performance issues with your specific framework. Flame graphs can also be utilized in backend languages beyond Ruby.
00:12:04.400
While flame graphs originated with Ruby, I will be providing resources for exploring those avenues further.
00:12:20.480
Now, let’s look at how to identify what backend processes are responsible for slowdowns. We’re going to use Rack Mini Profiler for this.
00:12:35.120
So, the first exercise is to check that it's properly installed and functional.
00:12:45.040
If you followed the setup, you should be ready to proceed. If not, it may be wise to consult someone who has completed the process.
00:13:00.640
To begin, start your server and navigate to localhost:3000 in your browser.
00:13:21.680
Once you access that, can anyone see something extra on the page that you wouldn't normally expect?
00:13:32.720
Has anyone got it running? Great! Can you identify anything on the page that seems out of place?
00:13:41.920
You should see a little badge at the top left of your browser with several boxes displaying millisecond values.
00:13:54.800
To demonstrate, if you have Rack Mini Profiler turned on while running your app, that badge will indicate where time is allocated within your page and any database operations being executed.
00:14:07.680
This badge may indicate SQL calls, but please note that it actually works for all Active Record queries.
00:14:23.840
This diagram is an example showing MongoDB queries; it just remains labeled as SQL due to historical reasons.
00:14:39.680
Next, let's examine the flame graph tool offered by Rack Mini Profiler.
00:14:53.040
Rack Mini Profiler features a flame graph tool that you can access by adding the query parameter "?wpp=flamegraph" to your URL.
00:15:14.560
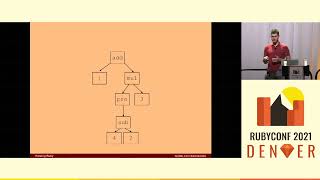
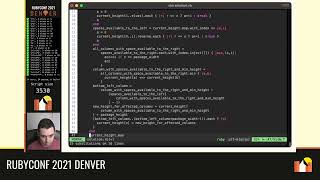
The flame graph visualizes what occurs when you load your page. Similar to how profilers work, it interrupts the Ruby process periodically to capture the current stack.
00:15:36.880
It consolidates this data into a flame graph, where the height represents the stack depth, while the x-axis shows the time spent.
00:15:48.000
You can also click on any part of the graph to view the particular line of code that has been reached and all code that was called.
00:16:01.600
Next, we are going to work on making Rack Mini Profiler produce a flame graph for your specific page.
00:16:14.000
Follow the provided link and make sure to specify the query parameter at the end.
00:16:25.440
Let me know if you can see it and how it appears.
00:16:35.520
Okay, great! It's working. You should see a pretty visualization, but it may not be entirely clear what you can do from there.
00:16:46.480
Now, let’s explore how to identify patterns in a flame graph. If you see a large horizontal section that shares the same color occupying considerable space, it indicates the code is spending lots of time in one method.
00:17:02.440
If you observe a pattern resembling a hedgehog spike, primarily of the same color, that indicates a loop.
00:17:15.200
On the contrary, a random peak with a different color signifies a call to a dependency.
00:17:27.440
Lastly, if a substantial chunk is removed from the flame graph with a flat line at the bottom, it points to garbage collection activity.
00:17:40.560
For example, here is a representation of a significant horizontal section, highlighted within a rectangle at the top. This section indicates extensive time spent in a particular method.
00:17:55.680
If you see something like this, it prompts a discussion about its necessity given the significant time investment.
00:18:07.520
You can also visualize garbage collection, which is typically represented by a light green line at the bottom, indicating that no other processes are running in the center.
00:18:21.520
Let’s take a moment to distribute mics. For the upcoming exercise, I would like you to examine the flame graph at the provided address. Try to identify what kind of patterns you can see.
00:18:39.920
If you have an idea, please raise your hand, and we’ll get a mic to you.
00:18:56.400
Let’s see if anyone would like to share their observations.
00:19:06.320
I noticed a significant horizontal section, indicating focus on one method. Thank you for sharing!
00:19:14.560
Let’s try another example. Please navigate to '/animals' with the specified query parameter.
00:19:33.680
When you have found a pattern there, raise your hand again.
00:19:52.080
I see lots of garbage collection with the sections cut out. Well done!
00:20:04.000
Refreshing a couple of times can show variations, and you may notice hedgehog spikes suggestive of loops. It's worth exploring more effective approaches.
00:20:20.080
Next, take a look at the root route (just '/') and see what you observe. Are there any patterns?
00:20:37.200
It appears there are many gaps and interruptions, likely due to garbage collection.
00:20:56.480
There may also be dependency calls that aren't very prominent but could affect loading times.
00:21:12.000
It's important to note that the colors in flame graphs will vary with each page load, and this shouldn't be taken as significant.
00:21:29.440
This example illustrates a call to a dependency, which isn't inherently an issue unless it occurs repeatedly.
00:21:50.400
You can also interact with the flame graph to view stack traces from individual frames, showcasing all the code in play.
00:22:06.080
An additional feature is a table displaying the percentage of time spent in each gem, helping identify any excessive usage.
00:22:23.680
Now, let’s discuss further investigation. The demo app I provided is not necessarily slow. However, it serves as a good example.
00:22:38.240
You may also engage by contributing to it as an open-source project, although that isn’t mandatory for this workshop.
00:22:57.280
Here’s an example from work involving a show action that was recognized as the third slowest controller action in our main application.
00:23:10.560
Via the flame graph, I identified a long chunk indicating significant time spent in a specific method.
00:23:25.920
What followed was inserting a binding within the method, leading me to observe consistent values being returned.
00:23:42.400
The same parameters were passed into the method every time, leading to unnecessary calls.
00:23:59.360
In total, the method was called 176 times, despite only needing to be called once.
00:24:15.920
I could optimize this by memoizing the result on the first call to prevent unnecessary repetitions.
00:24:31.440
Here is the flame graph before optimization: a large persistent chunk that we want to eliminate.
00:24:47.920
And here is what it looks like after the changes: the long horizontal section is gone, indicating that unnecessary method calls have been removed.
00:25:01.920
At this point, after successfully modifying your local environment, you'll want to think about deploying your changes.
00:25:17.440
Certainly, you will need to raise a pull request, but you cannot simply state it is faster in the description.
00:25:31.040
To support your change, you need to demonstrate that it improves performance through testing it locally.
00:25:44.960
Consider using Apache Bench to run tests. I have included an example for how to use it.
00:26:04.960
If you're having trouble, please reach out to me.
00:26:24.000
You may need to grab cookies or make a request from your browser to run tests.
00:26:42.400
The results will come from continually making the same requests for 30 seconds and recording the average time per request, which is known as load testing.
00:27:00.480
You’ll want to present your results before and after your changes. You can also include flame graphs and describe the differences evident in them.
00:27:16.320
Welcome, everyone! I hope you had a good break. It’s the last day of the conference, so expect quite a few pictures of my dog in this second part.
00:27:32.480
In the second part, I will first discuss adapting your approach beyond simply getting your pull request into production.
00:27:49.920
Then we will conduct a deeper exploration of flame graphs.
00:28:05.839
We’ve already discussed how to identify slow code and successfully raise a pull request to improve performance.
00:28:22.399
Now we will learn how to adapt our approach depending on product stages to enhance performance.
00:28:40.320
Based on my experience, there are three stages organizations go through concerning performance.
00:28:58.720
I’ll elaborate on these stages and the slightly different tactics that may be required, where you can recognize your current stage and adapt accordingly.
00:29:16.640
The three stages I will cover are: early stage, rapid growth stage, and stabilization phase.
00:29:35.920
Starting with the early stage product, you may still be seeking product-market fit. It's unlikely that you will experience slow pages unless there are heavy computational demands.
00:29:53.920
During this time, establishing performance targets is critical, especially because performance issues have yet to arise. By setting these goals, you can better assess when things begin to deteriorate.
00:30:15.360
In the rapid growth stage, you may know how many unique users to expect but can struggle to maintain ideal performance. This time can be both exciting and challenging.
00:30:34.560
Many users may visit due to in-store marketing or word-of-mouth recommendations, but if your site isn't ready to handle the increased volume, you're risking lost sales.
00:30:54.160
Ensuring site reliability becomes paramount now; you need to focus on maintaining performance during peak demand.
00:31:12.320
Finally, when growth stabilizes, you might be positioned well within your market, but you could also face pressure from competition.
00:31:32.720
For performance benchmarks, review your competitors’ products to understand their loading speeds and user processes.
00:31:52.479
Additionally, consider how slight improvements can help your product stand out from others—because being faster than your competitors could be a critical differentiator.
00:32:12.720
Once you've raised your pull request, I’d like to delve into the concept of marginal gains while keeping your team engaged.
00:32:32.080
Through optimization work, one engineer can create impactful changes, but eventually, their influence will plateau.
00:32:50.720
Thus, bringing in more team members to make incremental improvements across pages will yield a more significant overall impact.
00:33:10.720
To summarize this segment, we'll look closely at flame graphs and explore how they were created, plus alternatives to their visualizations.
00:33:30.720
Finally, we will engage in an exercise, allowing you to start profiling your own applications.
00:33:49.920
To understand the need for flame graphs, it’s essential to consider the challenges presented by traditional stack traces.
00:34:09.360
Each stack trace output can be verbose to the point of being nearly impossible to analyze in an organized manner.
00:34:28.320
This complexity is why Brendan Gregg invented flame graphs, as they enable a more efficient visual representation of performance profiles.
00:34:46.880
Through this method, stacks can be displayed for quick assessments of time spent effectively.
00:35:09.120
While flame graphs are commonly associated with Rack Mini Profiler, the term was originally used differently.
00:35:27.600
Prior to their association with Ruby, 'flame charts' were utilized to represent profiles sorted alphabetically. Now, we commonly refer to our variant as flame graphs.
00:35:46.320
Sunburst charts are another alternative way to visualize performance data. These present similar profile data in a circular format, but can be more difficult to derive insight from.
00:36:06.400
Alternatively, icicle charts flip the layout, displaying data in a stacked format hanging from the top edge, presenting another view.
00:36:25.920
The newer visualization method in Rack Mini Profiler now uses an icicle layout, which was developed to render more complex graphs without crashing.
00:36:46.320
Your next task involves stopping your Rails server, checking out the branch to run speed scope renderer, and running the bundle install again.
00:37:01.920
Once this is done, restart the server and observe any new features of the performance profiling.
00:37:17.520
Pay attention specifically to the layout—it may differ significantly, offering additional insights into your application.
00:37:36.320
If new vulnerabilities appear with information overload, try zooming in for clearer perspectives.
00:37:54.320
Speed scope will show various performance metrics while maintaining user experience.
00:38:10.480
Note that this new layout will alter how you interpret graphs, but you'll find it has many advantages.
00:38:28.400
Finding the slowest methods within code execution becomes easier as you filter data points effectively.
00:38:49.120
With speed scope, explore the left heavy view, which groups similar stacks together, helping to pinpoint bottlenecks.
00:39:07.720
Following this, the sandwich view can allow you to see performance over individual methods, aiding in rapid changes to speed enhancements.
00:39:25.840
Speed scope also includes seamless options for importing and exporting profiles, enhancing versatility.
00:39:45.920
Ultimately, through experimentation within speed scope, users can learn which methods provide the most significant optimization opportunities.
00:40:05.120
Finally, let’s recap what we’ve covered so far: reasons to prioritize performance, how to find slow code, how to read flame graphs, and how you can make improvements.
00:40:26.200
As you seek to enhance application speeds, consider installations for Rack Mini Profiler within your projects.
00:40:44.200
I will share slides afterward, offering a guide to help you identify areas for improvement.
00:41:03.120
I encourage everyone to reach out for assistance as you begin this journey. Thank you!
00:41:19.400
References and additional readings will be shared for further exploration.
00:41:29.200
If you wish to discuss findings or share experiences, I am available.
00:41:46.640
Engaging with the community around these techniques can yield valuable insights.
00:42:03.760
A friend of mine authored an article on generating artificial traffic for testing performance, which could be very beneficial.
00:42:21.040
If you’re interested in learning about 'umbra,' it’s a cool approach that makes use of actual traffic data.
00:42:36.680
I can provide more details on that approach if you’d like! Thank you very much!
00:42:53.320
I hope you enjoyed today's workshop!
00:43:06.560
Now, let’s get started with the next section.