00:00:00.160
Hi, everybody! My name is Maxime Chevalier Boisvert, and today I'll be telling you about YJIT, which is a new just-in-time compiler that we're building inside of CRuby.
00:00:06.720
So, on the agenda, first I'll tell you a little bit about the project: why we're building YJIT inside of CRuby, some technical details about how it works, current performance results, and finally, I'll conclude with a segment about what we can do to improve the performance of just-in-time compilers built inside of CRuby, including YJIT and MJIT.
00:00:16.400
Now, why JIT? Well, the name stands for "YARJIT" because we use YARV bytecode in our compilation process. You could also say it stands for "Yet Another Ruby JIT" because obviously, we're far from being the first just-in-time compiler for Ruby.
00:00:39.440
The primary goal of YJIT is to produce speedups for large-scale, real-world software. I work with Shopify, so we're primarily concerned with web workloads, particularly Ruby on Rails. The approach we've taken, due to the complexity of the CRuby codebase, is to build something incrementally.
00:01:00.799
We started by building a JIT compiler that doesn't support all of the Ruby bytecode, and incrementally, we've been adding support for more operations, falling back to the interpreter for anything that we don't currently support. So far, this has been working pretty well. The main benefit of this approach is that YJIT is highly compatible with all existing Ruby code and packages. You don't need to change your Ruby code at all, and it supports all of the latest Ruby features.
00:01:38.320
YJIT is built at Shopify, but it is fully open source under the same license as Ruby. We hope to eventually upstream YJIT into CRuby, but in the meantime, we want to find ways to help both YJIT and MJIT achieve better performance.
00:01:58.880
This project is a team effort being led at Shopify in the Ruby and Rails infrastructure group. We've also had multiple major contributions from GitHub over the last couple of months. YJIT is very far from being the first just-in-time compiler for Ruby; there have been multiple efforts to build JITs for Ruby. Most of them are no longer maintained, but a few, such as MJIT, JRuby, and Truffle Ruby, are still ongoing.
00:02:30.160
MJIT has been integrated into CRuby for a while now, and it is based on GCC. It essentially takes the source code of the interpreter and stitches it together into something that gets compiled by GCC into a module that can be linked at runtime.
00:03:03.360
The main strengths of MJIT are that it is already in CRuby, it's compatible with the latest Ruby features, it produces good speedups on smaller benchmarks, and it's officially supported on multiple platforms. However, some of the trade-offs include that it performs best on synthetic benchmarks with large methods but not as well on larger programs with many small methods, which is typical for web-based software.
00:03:39.360
We think that GCC is not well-equipped to optimize dynamically typed code, as it doesn't have the right optimizations and analyses, and because GCC is being used as a backend by this compiler, we have limited control over what it does and over the compilation pipeline.
00:04:12.560
Truffle Ruby is an alternative implementation of Ruby based on the Truffle and Graal platform. Its main strengths are that it is actively developed, features a powerful optimizer based on partial evaluation, produces significant speedups over CRuby on many benchmarks, and has good support for C extensions using an emulation mechanism.
00:04:58.960
However, the trade-offs include very long warm-up times, sometimes up to several minutes, greatly increased memory usage compared to CRuby, and it's not exactly a drop-in replacement as it doesn't have 100% compatibility.
00:05:24.720
This brings us to the reason why we chose to build YJIT inside of CRuby. Language compatibility is critical for most real-world users. This is not a problem specific to Truffle Ruby; I would say that most programming languages with alternate implementations face similar issues.
00:05:56.480
For example, JRuby is working towards Ruby 2.6 support, and Truffle Ruby is aiming for Ruby 2.7 compatibility. In the realm of other programming languages, such as Lua, we have Luajit, which is a very impressive just-in-time compiler that is well-loved by the community, but unfortunately, it's falling behind when it comes to supporting the latest Lua features, which limits its adoption.
00:06:18.640
The same problem applies to PyPy, which has done impressive work but is currently working on supporting Python 3.6, while CPython has already reached 3.9. By building YJIT inside of CRuby, we can easily stay up to date with the latest changes and support the newest language features.
00:06:42.560
Now, let's discuss how YJIT optimizes Ruby code. Ruby's language is notoriously difficult to optimize. There is a blog post published back in 2012 that addresses many challenges, including the fact that every operation on every basic type can be redefined, methods can be refined, constants are not actual constants, and callable functions can write into the local variables of their callers. The method call logic is very complex, and real-world code has many small methods, making it hard to apply compiler optimizations without significant inlining.
00:07:12.560
Ruby is also a language where inlining can be tricky. There's also the C extensions API, which comes with its own challenges for compiler optimizations.
00:07:31.920
The approach we've taken for YJIT is to build a compiler based on lazy basic block versioning. This is rooted in research that I started during my PhD work on just-in-time conversion for JavaScript. My focus was on optimizing dynamic languages and eliminating dynamic type checks.
00:08:01.600
Basic block versioning allows us to specialize machine code types without costly type analyses by leveraging the fact that within a JIT compiler, we can observe the program while it's running. This is essentially a reimagined take on what a JIT compiler can do.
00:08:35.440
Most conventional just-in-time compilers are method-based, compiling entire methods at once. However, basic block versioning operates at a low-level granularity, allowing us to compile individual basic blocks as units. This means we can compile just parts of methods, leading to more flexibility in optimization.
00:09:08.680
There is a relatively small but growing body of literature on this technique. I published two papers during my PhD, and others have adapted it for functional programming languages like Scheme and for use with gradual typing.
00:09:43.920
Two key components of lazy basic block versioning are: first, the versioning of basic blocks, which allows us to accumulate and propagate type information while specializing different versions of basic blocks based on context, and secondly, lazy code generation. This is a kind of lazy evaluation for code, where we generate code only when required, just before execution.
00:10:05.280
Now, let’s look at a small example. Suppose we have an if statement that checks if a value n is a fixed number. If so, we proceed to block B; otherwise, we go to block C, followed by block D.
00:10:38.200
In terms of control flow, this looks quite structured. Inside block B, we establish that n is indeed a fixed number. Conversely, when in block C, n is known not to be a fixed number. However, upon merging into block D, we lose this specificity, and n could be either.
00:11:10.080
With basic block versioning, we can split block D into two distinct versions, D' and D''. In D', we preserve the information that n is a fixed number, while in D'', we retain that n is not a fixed number. This nuanced handling is quite clever.
00:11:39.920
When considering more significant control flow graphs with numerous nested if statements, we can't simply duplicate everything to preserve types. Here, laziness comes into play—if we know that certain branches of logic are never taken, we don’t need to generate that code, thus avoiding an expansion of our generated machine code.
00:12:06.800
In YJIT, we use lazy block versioning to implement some innovative techniques. Typically, JIT compilers want to specialize code based on runtime values. Conventional methods involve a profiling phase followed by code generation, but in YJIT, we utilize a technique borrowed from the context operator in Psycho, termed deferred compilation and type capture.
00:12:39.760
This means that for bytecode operations we wish to compile, we delay the compilation until we can ascertain the values that occur at runtime. Only then do we generate the code based on what we've observed.
00:13:10.000
Let’s illustrate this with an example. Here, we have a method that indexes into either an array or a hash. Disassembling this yields a concise bytecode instruction sequence: it begins with two local get operations, followed by a call to the indexing operation, and ends with a return.
00:13:47.920
When generating the corresponding machine code, we first produce code for the get local operations and install a stub for deferring compilation until we identify the values encountered during execution.
00:14:22.480
When this method is first called with an array and an integer, we generate optimized code for array operations, following checks that validate the types we see at runtime. If the method is invoked again with a hash, we hit the stub, which calls back to the compiler for specialized code generation for hashes.
00:14:52.960
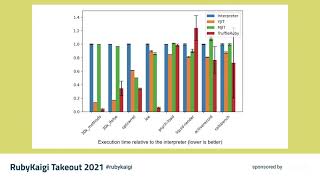
Now, onto some early performance results. We've tested YJIT against the CRuby interpreter, MJIT, and Truffle Ruby across various benchmarks. The benchmarks on the left represent synthetic tests we've implemented ourselves, while those on the right are based on real-world software and Ruby packages.
00:15:25.600
The benchmarks with 30,000 methods and if-else structures were designed to compel YJIT to generate substantial code, revealing insight into effective code size against performance measures.
00:15:53.040
The results were conclusive: as long as we compile the code effectively, YJIT can deliver considerable speed enhancements over the interpreter, outperforming MJIT on these benchmarks.
00:16:20.880
In terms of warm-up performance during benchmarking, YJIT demonstrates sustainable speedup relatively quickly, whereas Truffle Ruby requires over two minutes to reach comparable performance due to latency challenges with de-optimizations.
00:16:57.440
The most significant finding, however, is how compatible YJIT is. We have recently integrated tracepoint support and are passing all CRuby tests through make check. We match the performance of Ruby head within the Shopify core and GitHub back-end stability testing environments.
00:17:31.040
Moreover, YJIT runs the Shopify storefront renderer software in production outperforming the CRuby interpreter.
00:17:54.080
While this all sounds promising, we must recognize there are performance bottlenecks within CRuby inhibiting our target performance levels. These limitations are not merely solved by enhancing YJIT's sophistication.
00:18:19.680
Common misconceptions exist around just-in-time compilers being sophisticated technologies that automatically yield great speeds when integrated into existing language implementations, which is not the entire reality. YJIT efforts reflect that seeking performance usually necessitates focused design alterations.
00:18:51.760
Various structures miss the complexity required to maximize performance beyond what a simple interpreter can provide, focusing instead on trade-offs that a robust JIT implementation must address.
00:19:12.560
We must examine performance bottlenecks in CRuby, including its object-oriented nature characterized by short methods and a high frequency of method calls, along with instance variable accesses.
00:19:35.360
The bulk of machine code we generate often centers around method calls and instance variable accesses, which currently necessitate multiple steps. Yet, JIT compilers cannot eliminate the complexities due to constraints defined by the interpreter.
00:20:00.880
Examining how instance variable reads are implemented in YJIT shows they entail complex methodologies due to pointers and flags within the Ruby object model, which leads to multiple levels of indirection that degrade CPU cache efficiency.
00:20:30.560
Efforts are underway to improve object representation efficiency through variable-width allocation, potentially addressing these inefficiencies.
00:21:01.440
We are evaluating the use of object shapes as a means to facilitate improved instance variable access, which would eliminate many of the current computational inefficiencies reflected in standard methods.
00:21:35.040
For example, refactoring checks within the code could reduce the necessity for multiple comparative operations and guards significantly.
00:22:13.680
From here, I will express the direction we are heading. We are targeting a more sophisticated backend while aiming to decouple type specialization logic from code generation to allow for optimizations.
00:22:34.160
Our intention includes expanding support for ARM 64 CPUs as they become more prevalent in laptops and servers, along with the need to integrate object shapes into CRuby.
00:23:15.840
We anticipate that various optimizations could benefit both YJIT and MJIT. We hope for collaboration with core Ruby developers to ensure JIT implementations receive stability and optimization.
00:23:39.040
In summary, we are still in the early stages of the YJIT project, which has been developing for about a year. Our results thus far are modest, but we see enough potential to believe clearer paths towards notable speed increase. Building this new JIT inside of CRuby leverages compatibility advantages, and YJIT behaves closely to a drop-in replacement for existing Ruby binaries.
00:25:01.680
Lazy basic block versioning captures type information late, maintaining precise optimizations compared to conventional type analyses. For anyone interested in delving deeper into the technologies behind YJIT, we have published papers on lazy basic block versioning at ECOOP in 2015 and 2016.
00:25:26.560
If anyone wants to connect with me to discuss compilers or YJIT's functionalities, feel free to reach out via my Shopify email or through Twitter. Finally, YJIT is open source and available on GitHub at Shopify/YJIT. Thank you for your time!