00:00:00
Let's see, our next speaker is Kevin Menard. He works for Oracle, which makes a database that I have used before. Maybe some of you have used it too. He is going to talk to us about "A Tale of Two String Representations," and I think that this will be a very interesting tale. Everybody, please welcome Kevin.
00:00:38
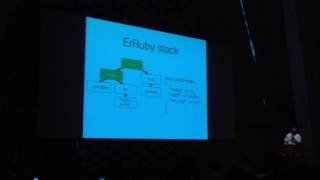
All right, hi everybody! My name is Kevin, and I'm a principal member of the technical staff at Oracle Labs, where I work on JRuby plus Truffle.
00:00:45
For those of you who aren't familiar with it, it's a new implementation of Ruby using the Truffle self-optimizing AST interpreter, which is used in conjunction with the Graal virtual machine. I realize it's a mouthful, but basically, we're trying to build a new high-speed implementation of Ruby, and we ship it with JRuby as an alternative back-end.
00:01:14
Before I get started, I do need to inform you that what I'm presenting today is research work out of a research group. It's not a product announcement, and you should not buy or sell stock in Oracle based on anything you hear today. All right, with that out of the way, let's tell the tale of two string representations.
00:01:35
Fittingly enough, it makes sense to start our tale with the string. Now we can move into representations. The first representation here is our string, which is basically how MRI internally represents strings. It's the way all Ruby implementations implement strings.
00:01:54
JRuby uses a very direct port of MRI C code to Java. Rubinius, I believe, just takes the MRI code entirely. Our strings are structured very similarly to how strings in C are structured. So what we have is a byte array, and then we have a length field to know how far to look into that byte array.
00:02:18
We have an encoding because Ruby strings are encoding-aware, and we associate encoding with the strings to know how to interpret the byte sequence. Then there's this code range field, which is used as a sort of cache of information we know about the underlying byte array given the current encoding. There are some additional fields here that I'm not representing; this is mostly just for simplification.
00:02:42
I do have a reference slide later on that lets you see all the gory details of our string if you're interested. The key features of our strings are that they have a mutable flat representation. When we want to represent a string, we need to be able to allocate a contiguous region of memory to represent the contents. Operations with our strings are essentially byte-oriented.
00:03:01
Nearly everything we want to do requires reading from that byte array or directly manipulating it. Now, Ruby strings are mutable, but our strings are immutable. In practice, many Ruby strings are effectively immutable throughout their lifecycle and never actually change. It would be a shame if we had to waste all these bytes trying to represent the contents of two identical strings that never change.
00:03:30
So our string has a mechanism for sharing the underlying byte array using copy-on-write. The second representation is ropes. Ropes are an immutable tree structure, and what we have is, at the leaves, these string fragments.
00:03:55
Underneath the covers, they are very similar to our strings; we still have a byte array, we still have encoding, and we still have a code range. However, the leaves are immutable. The byte array can never change, they can neither grow nor shrink, and their contents can never change.
00:04:16
If we want to manipulate a rope, we need to build on top of it, so we have a persistent data structure, and we do this by using operation-labeled nodes. This means that ropes are immutable, and they have a tree representation.
00:04:37
An interesting side effect of this is that we don't need contiguous memory to allocate them. So if you wanted to allocate a 1-gigabyte string with our strings, you would need to have that available in your heap. With ropes, you can do this by having multiple different leaves, each allocated individually.
00:04:58
You might be wondering why you would ever want to do that. Well, strings in Ruby are used for more than just sequences of characters; they're also used as a general byte buffer data type. If you're dealing with binary data or working with I/O operations, you may very well need to allocate a large string.
00:05:25
By having this tree structure with each of the leaves immutable, it shapes the way we think about operations. Instead of always looking at the underlying byte array, we think more in terms of logical string fragments.
00:05:45
Because each of the levels of the tree is immutable, we reduce memory consumption by allowing nodes to appear in multiple trees. Ropes are an older idea. They were originally proposed as an alternative to strings in an environment called Cedar.
00:06:05
However, with Ruby, we already have a string type. We don't want to introduce another new type; we want to work with code that's already out there. So our idea is to change the representation for strings with ropes.
00:06:29
But ropes needed to be modernized for Ruby. Ropes, as they were originally proposed, modeled C strings very closely—they were byte-oriented and weren't aware of encodings. All the methods called on them were done through library functions.
00:06:47
With our ropes, we've updated them, so we have operations that correspond to Ruby semantics, and each of the leaves is encoding-aware. The values you see roughly match the code range information.
00:07:03
So we have our two representations, and we can see that they're laid out differently in memory, but what does this practically mean operation-wise? I'm going to run through some operations here. The first one is string concatenation.
00:07:32
I do apologize for the slightly confusing terminology I'm using, so in the string documentation, concatenation is the immutable version with the + operator, and 'append' is the mutable version with the shovel (<<) operator.
00:07:46
I've included code samples for both so you can hopefully follow along. The operation starts with x and y, where we want to concatenate them to get a new copy, z. On the right is the byte array for x and the byte array for y.
00:08:01
The first thing we need to do is allocate a new buffer large enough to hold both contents. This buffer is as big as x and y together. Then, we copy over x and then y, and we're done. This is a linear time operation. We had to do a single memory allocation—one large enough to hold the contents of x and y, and then two memory copies.
00:08:19
At the end of this process, we have two copies of x and y in memory because x and y still exist as variables themselves, but their contents now appear in z. In contrast, this is how concatenation would look with ropes.
00:08:42
We have our immutable leaf ropes, which are the encoding-aware leaves I had mentioned previously. These do have their byte arrays, but we want to concatenate them. We simply allocate a 'concat' node and point it to the two leaves, so this is a constant-time operation.
00:09:03
What we needed to allocate was memory for that node—we didn't need to allocate a new buffer, and we didn't have to copy any memory. At the end of this process, we still only have a single copy of x and y in memory.
00:09:22
I ran a benchmark that was intended to emulate what one would do with ERB. It did a tight loop of concatenations of HTML, and at the end of the process, wrote the bytes out to the network to simulate a web server response.
00:09:49
The way to understand this graph is that all values are relative to MRI, which appears on the left. MRI is as fast as it is itself—a 1.0x speed. JRuby is about 20% faster.
00:10:09
Then I ran the numbers two ways with JRuby plus Truffle—one using our string implementation and one using ropes. The reason to do both is that each of these language implementations has a different underlying runtime and a different compiler.
00:10:27
So I didn't want to attribute things to ropes that could easily be attributed to the differences in just the compilers. What we can see here is that ropes vastly outperform the others. I reran the same benchmark using string append, which is the mutable version.
00:10:50
Now we see that the numbers collapse because other implementations get a lot faster. JRuby is about twice as fast as MRI. Keep in mind they're running almost identical code, so this speed up is basically due to having an optimizing compiler in play.
00:11:06
Then, we have the JRuby plus Truffle, our string, which is about three times as fast as MRI, and then we have our ropes, which are about twice as fast. So in this situation, ropes are a little bit slower than our strings—at least as they are implemented in Truffle.
00:11:20
This slowdown can be attributed to Truffle's object model, which is optimized for reads rather than writes. Ropes are immutable, so with each of these append operations, we still need to allocate a new node and update the reference to that rope in the corresponding Ruby object.
00:11:36
Those updates can be somewhat slow. I believe this is something we can fix in Truffle. As we can see, there’s a bit of an improvement for ropes, but we're still faster than our strings with other implementations.
00:12:05
What's really interesting is to compare how the different implementations perform for concatenation versus append. There's a big gap here. For this particular benchmark, using string append, it's about 40 times faster in MRI.
00:12:27
It's about 65 times faster in JRuby and 138 times faster with our strings in Truffle. When we get to ropes, the performance difference is negligible. I think this is important; we shouldn't have these wide performance gaps. They create issues for you in production. On small enough data, you might not see it.
00:13:00
But when you get into larger streams of data, suddenly, the choice of using the + operator rather than the shovel operator presents itself as a performance issue—one that you'd not have anticipated.
00:13:32
Another reason this is problematic is that the notion of mutability for an object is behavioral. You shouldn't pick a mutable or immutable version of something just for performance because mutability conveys something about your code's intent.
00:13:54
Likewise, as Rubyists, we like to write code that looks nice. For many people, using the plus operator to add two strings together is a natural thing to do. We shouldn't penalize people for doing this.
00:14:11
With ropes, we see a slight dip in performance over our strings, but I think it's made up for by the fact that you can choose either version of concatenation and get roughly equal performance.
00:14:33
If we want to abstract the notion of concatenation, these are the set of string methods that can be implemented using ropes. Now I'm just going to go through some other operations we handle, such as substring.
00:14:53
With our strings, we have our 'hello' string. We wish to get the middle three bytes. From the byte array, the first thing we do is allocate a new output buffer and copy the data—then we’re done.
00:15:09
With ropes, again we don't need to do a buffer allocation or a memory copy; we just create a new substring rope and set some metadata fields to indicate the offset and the byte length. Here's the set of operations that can be represented using substrings.
00:15:23
There’s a prevailing theme here where we can generalize actions for many of these different methods. If we can make those generalized actions fast, we can have wide-reaching consequences.
00:15:36
Another operation is multiplication—here we want to triplicate the string x. The steps include allocating a new buffer for nine bytes, which will require a copy, but with ropes, we simply have a repeating rope node.
00:15:54
In this case, we just allocate the repeating rope node, indicate that it's multiplied three times, and point to the original rope. These are all lazy operations; we don't need to materialize the underlying byte array until we actually need it.
00:16:21
This is why the concatenation operation was so much faster for ropes. If you’re doing 10,000 concatenations and you only need the bytes at the end, all those intermediary buffer allocations are unnecessary. By deferring the operation, we're able to limit the memory allocations until we actually need it—and using ropes, we might not even need to allocate at all.
00:16:55
For instance, with a repeating rope, if you want the fourth character, we can take that x value in the underlying byte length and just offset into the child without materializing the array at all.
00:17:12
So let’s step back again. We have our 'hello' string, and we can query it. Ruby has a very rich string API. Here we can see that 'hello' is made up of five bytes and we can also see that it's made up of five characters.
00:17:34
In this case, the 'hello' string is UTF-8 encoded, and UTF-8 is ASCII compatible. So 'hello' here is made up of only ASCII characters, and in ASCII, each character can be represented by a single byte.
00:17:50
The number of bytes and the number of characters line up, and this is nice. We can do some nice optimizations in Ruby based on that.
00:18:03
I ran a little benchmark where I took the size of the 'hello' string and multiplied 'hello' 100 times and took its size. We can see that the performance is essentially the same; this is a constant-time operation.
00:18:18
Our strings already have that byte length field, and they can just return it. Ropes have something very similar. JRuby again is about twice as fast as MRI in these particular benchmarks. Truffle is about 17 times faster.
00:18:40
This is because Truffle can optimize very well in conjunction with Graal—lots of constant folding and similar techniques. I looked at another string from Ruby spec, which presumably means something like 'ignorant' in English. It's made up of 12 bytes but only four characters.
00:19:02
This introduces our first mismatch. The thing to note about UTF-8 is that it's variable-width encoding. You might be tempted to think that you could take the 12 bytes, divide it by three, and say each character is three bytes wide, but that's not how UTF-8 works.
00:19:18
Characters can be anywhere between one and six bytes, so now when we do that same string length calculation, we see a much bigger gap. I took the string, computed its size, multiplied it by 100 and then computed its size again.
00:19:42
We can see another benefit of ropes here. Because ropes are immutable, we're able to cache the character length inside the rope itself. Thus, the benchmarks have been unfair; for ropes, it's a constant-time operation, while for our strings, we have to do a full byte scan.
00:19:59
I wanted to see what the relative performance difference was in each of the implementations. Taking these strings, I did the 100 multiplied time case—MRI is about four times faster on ASCII-only data versus non-ASCII data. JRuby is about seven or eight times faster.
00:20:21
With ropes, we have no performance difference whatsoever. I think this is important; we shouldn't have hidden performance pitfalls.
00:20:36
Where this issue might come up is if you're doing a web application, and you've written your templates all in ASCII, but you allow user-supplied data—maybe their name, their address, or their company name—that has a non-ASCII character in it.
00:20:54
The performance profile for your application can change drastically. Suddenly, things that were constant time become linear time. If you're simply taking the mean of your performance values, you're not likely to notice that there's a problem.
00:21:09
You could have a bimodal distribution, and it gets washed over by just taking the mean. You may now be thinking, "Well, who cares about string length? How often do I do that?" However, string length is actually invoked repeatedly within the core implementation.
00:21:24
Anytime you want to get something by index, you need to know the string length for bounds-checking. So if you want to get a character at position -1, you need to know that that’s actually the last character and work your way back.
00:21:41
There's no reason we couldn't do this with our strings, but it gets a lot more difficult because their underlying byte array can be invalidated at any point. When it's invalidated, you need to be able to update the character length efficiently. Whereas with ropes, we're able to propagate the value upward.
00:22:00
For the leaves, we might need to do a full linear scan, but once we do it, we never have to do it again. If we take the repeating rope example, if we know the character length is 4 and we're multiplying it by 100, then we can just say that the character length from that rope is 400.
00:22:21
If you do this with our strings, you'd end up creating a completely new memory buffer of 400 bytes, and you'd have to scan through it all.
00:22:36
I just want to wrap up a bit here—there are other benefits to ropes. There are a lot of operations that we've modeled in JRuby plus Truffle. Basically, we have replaced our strings throughout the entire implementation, except in places where we allow switching back and forth to maintain compatibility.
00:22:55
But we've defaulted to using ropes now, and what it has allowed us to do is reduce memory consumption generally. When we have different strings that are logically equivalent, we can unite them, meaning we can use the same rope repeatedly throughout.
00:23:12
This is really important for metaprogramming. Last year, I gave a talk on metaprogramming and mentioned that we use a cache for method names or variable names to do fast lookups. But this is problematic if you can't have referential equality.
00:23:31
We want the ability to say that a method name and a string supplied by user code are the exact same rope. If we can perform a reference check, it allows us to do that very quickly with simple integer comparisons.
00:23:47
If we don’t know they are equal like that, we need to do linear scans and byte-wise comparisons between both. While that works, having this guard takes too long and basically eliminates any value we would have gained by caching it.
00:24:04
Having immutable values is also really nice for optimizing compilers, especially things like Graal which use partial evaluation, aggressive inlining, and constant folding. Having constant values really aids that process.
00:24:20
A recurring theme throughout this conference has been concurrency. Ropes are implicitly thread-safe—while we still have a reference from our Ruby string to a rope, and you could have two threads read from that, you'll never see mysterious byte updates because the byte array for each level of a rope can't change.
00:24:39
There are some deficiencies, though. I mentioned that Ruby strings basically have dual functions: one is as a sequence of characters, which is essentially how I've been talking about ropes, but they can also be used as a byte buffer.
00:25:04
In this case, ropes aren't really a great fit, particularly if you have a stream of binary data and you need to call set byte. If you’re updating a single byte at a time, these rope nodes end up dominating the cost of what you want to update.
00:25:21
So I think we can come up with better ways of doing that, but that will be future work.
00:25:41
I like ropes because they make some key operations in Ruby much faster, but if you have experience doing performance work at all in Ruby, particularly if you came from a C background, you may find that changing the asymptotic complexity of operations in a certain way can make things a little harder.
00:26:08
The performance is often much more normalized across the various encodings. If you take that same Ruby string and add non-ASCII data into it when fetching a character, you're now back to linear time.
00:26:27
What we need to do is try and smooth over these differences between encodings so that developers can think more reasonably about how their strings will perform. There are some quick references I want to point out.
00:26:49
Pat Shaughnessy, who wrote "Ruby Under a Microscope," has a great set of blog posts that investigate strings and their performance characteristics. There was actually a Google Summer of Code project for MRI to add ropes, which I just learned about recently.
00:27:09
The student wrote a very nice write-up about applying ropes to a different Ruby implementation, and all the benchmark code I used here is publicly available.
00:27:35
To recap, ropes are an alternative way to represent strings. They present an interesting bridge between Ruby strings, which are mutable, and the way they're actually used—most of the time Ruby strings are effectively immutable. Ropes, being an immutable data type, take advantage of the fact that Ruby strings frequently are not changed.
00:27:58
This experiment has worked out quite well with JRuby plus Truffle and Graal, and I believe it would work out nicely for other implementations as well. The fact that fields are final works very nicely for our compiler, but I think it can bring benefits to both MRI and JRuby.
00:28:14
As language implementers, I think we need to make these core operations fast and compact. It’s easy to think that our current approach is the only way to implement something.
00:28:35
When we profile it and find that we can make things marginally faster, we may be stuck in a local maximum. Ropes are a novel approach. The idea has been around for 30 years, but it's a new way for us to represent string data and something I think we should explore for other core data types as well.
00:28:53
I want to thank a bunch of people. I didn't do all this work myself. The folks mentioned on the left, bolded, are from the JRuby and Truffle team, and our Ruby implementations come from their work.
00:29:14
Here's my contact information. Please feel free to email me or tweet me or reach out on GitHub if you have any questions about this. I love talking about it.
00:29:29
Now, I believe we have time for questions.
00:29:41
Any questions? Yes? Oh, good luck Kevin, I'm.
00:30:01
Speaking of Google Summer of Code projects, he mentioned a project related to the rope structure on MRI.
00:30:10
So the results may be similar, but our approach also has two questions. So the first question is: are we using practical applications? Most people use append, so concatenation. Are there huge improvements on such practical applications?
00:30:28
What do you think about that? The benchmark I used was actually extracted from ERB. If that is no longer the case, I guess I need to update it. However, I tried to pick something that was representative of how people write code.
00:30:45
I did a kind of soft survey of code on GitHub, and there seems to be plenty of Ruby code out there that does use the plus operator; perhaps it's not performance critical.
00:31:05
The other question is that such a structural change would add complexity. The source code could get much larger due to the use of ropes. What do you think about the trade-offs between complexity and performance?
00:31:25
The complication you've mentioned is very subjective. For us, I found it interesting because we can model many operations using a core set of nodes.
00:31:37
Taking a substring, getting a character out of it, and using slice—there are multiple operations we can model through a simple substring node. Doing this helps us find more efficient representations.
00:31:58
I agree that when looking at the underlying representation, it can get much larger because now you have a tree. If you want to print a tree, that can be challenging. However, I find that helpful.
00:32:12
If you see a lot of concatenates back-to-back, it suggests that something isn't being done efficiently with your strings.
00:32:27
In some cases with strings, you wouldn't have all those concatenates, but with string append, you could be repeatedly reallocating buffers.
00:32:49
If the underlying buffer doesn't have spare capacity for rewriting, the long tree can indicate there's a possibility of optimizing something.
00:33:01
I think a lot of this is also just unfamiliarity.
00:33:13
We're not used to thinking in terms of trees when it comes to string representation. When you see it, it looks foreign.
00:33:29
As we gain experience with it, it becomes less intimidating. Does that answer your question?
00:33:44
Yes, but please discuss that further.
00:34:03
Of course. I'm not trying to misrepresent anything—does anyone else have questions?
00:34:25
Oh! Here we go!
00:34:34
So, at Truffle, everything is ropes, right?
00:34:50
Yes, and—but in my understanding, the current patch is essentially a mix of buffered strings and ropes. Do you think it would be interesting to preserve both?
00:35:05
To make concat as efficient as possible with a buffer, recognizing that ropes are adequate for operations involving characters?
00:35:20
I think having ropes is generally good enough for us; there are certainly edge cases that require further investigation.
00:35:45
One particular instance is when a string only wants to append a few bytes.
00:35:52
In that case, you would have allocated a rope node that might dominate the cost of adding those few bytes. Traditionally, ropes accommodate these small concatenations.
00:36:06
As you append small byte values, the implementation combines them rather than repetitively allocating new rope nodes.
00:36:17
Currently, we don’t perform that optimization, but I think it's an easy extension to look into.
00:36:35
Thank you for your questions!
00:36:50
My question is whether instances of strings share pointers to ropes.
00:37:01
Yes, they do. But could you find yourself in a situation where you have to copy an entire subsection of a tree?
00:37:14
For example, if you have two string instances that point to the same rope but one starts in the middle of it, do you have to copy that subtree?
00:37:31
That makes sense; copy operations are avoided and instead, the substring rope with metadata is utilized.
00:37:49
The underlying string can belong to multiple trees.
00:38:05
In the rope model, it allows us to utilize multiple references.
00:38:16
Consider the example: if one case of a string is included, then two or more can reference it.
00:38:30
Thus, my ropes are essentially optimized for this aspect.
00:38:51
Multiple references would potentially allow flexibility without redundancy.
00:39:02
One last question about the ropes' implementation: would you consider it more complex than the buffered?
00:39:12
In my view, it is clearer!
00:39:28
If you’ve looked closely, the string code is complex and difficult to understand.
00:39:41
Since the character length isn’t cached, every operation adds considerable complexity. Ropes, being immutable, simplify this by pre-calculating the necessary metrics.
00:39:57
Hence, all operations don’t require individual lookups anymore.
00:40:01
That allows us simpler operations based on knowledge of structure from the start.