00:00:00.000
Ohayo gozaimasu! So before I begin, I just wanted to say that I feel deeply honored to be here speaking at RubyKaigi. This is my first time in Kyoto, my first time in Japan.
00:00:10.950
Actually, I asked Jounin if I needed to wear a special gaijin hat to identify myself easily, but he assured me for some reason I wouldn't need it. I've always wanted to visit here and attend this great conference, let alone be welcomed to speak at it. So, thank you to a month of the song and the rest of the RubyKaigi organizers, and my employer for giving me the time to come here.
00:00:25.109
So, who am I? My name is Chris Arcand, and I look like that on Twitter and GitHub. My username is the same everywhere. I'm from Minnesota in the United States, next to the Canadian border.
00:00:41.820
Minnesota is lovely, it looks a lot like that. I live in the metropolitan center of it, the Twin Cities. The Twin Cities are two major U.S. cities called Minneapolis and St. Paul. They are about 13 kilometers apart, which isn't very common in the U.S., as downtown areas are usually far apart.
00:01:03.090
We have absolutely gorgeous summers there and beautiful forests and lakes to enjoy. In the winter, we love playing ice hockey. The winters always look as beautiful as the picture down here at the bottom, except if you've been there, you know that I'm actually lying. Winters look a lot like this: that's a man on a snow bicycle with big fat tires to get traction riding through a blizzard.
00:01:22.460
After such a blizzard, sometimes things will look a lot like this. This is a street of cars parked that are completely buried in snow. But I'm just going to repeat that the summers are lovely, and you should at least come visit during the summertime if you're nearby.
00:01:38.990
I'm a Ruby developer at what Aaron Patterson has always described as a small startup you might have heard of: we're called Red Hat. I work remotely out of Minnesota; there's no engineering office there at Red Hat. I work on ManageIQ.
00:01:57.770
ManageIQ is an open-source cloud management platform that powers Red Hat platforms. It basically aggregates all of your enterprise infrastructure into one place and adds a bunch of functionality on top of it. The codebase is hosted on GitHub; it's really easy to find and learn more about it. If you want to chat with me afterward or visit manageiq.org, we're always on the lookout for good developers.
00:02:10.810
So why am I here? I am here because I love programming. As you can bet, that means I love writing code. However, there's something else that I love even more: I love deleting code. Ruby has been a successful programming language for some time now, and we as Ruby developers might now maintain legacy applications that have been developed for many years. A consequence of our long-term success is that these applications may contain unused, obsolete, and unnecessary code.
00:02:44.269
I'm going to tackle a very specific case today. I'm going to talk about methods that stand worthless and dead, unused by any callers in the application. This might be fine for frameworks where the public API is never called within the framework itself, but in terms of an application, it just adds cruft.
00:03:02.570
Now, how does code like this end up in our projects? A couple of reasons come to mind. I think of a developer at the very beginning of a project. They might add a bunch of methods that they think will be useful someday but actually aren't, and they never get used. The implementation might change underneath and they don't actually work anymore—this is a type of over-engineering.
00:03:21.500
Another reason is just poorly written code. Imagine a brand new inexperienced developer joins your project. They might write a very specific method that isn't very flexible and is completely unhelpful beyond that one single spot; maybe it's for one tiny bug, one tiny case. Hopefully, these two examples are caught in code review, but sometimes they aren't.
00:03:38.540
It could also be that things have just been refactored over time and the methods just aren't needed anymore. You might ask, who cares? The short answer is that unnecessary code is confusing. It adds complexity where there shouldn't be any and creates an unnecessary maintenance burden on future developers. It makes you scroll more in your text editor, which is really annoying.
00:04:08.550
But don't take my word for it; other people think so too. There's a great post by Ned Batchelder called "Deleting Code" from 2002. In this post, there's a snippet that I'd like to share: if you have a chunk of code you don't need anymore, there's one big reason to delete it for real rather than leaving it in a disabled state: to reduce noise and uncertainty. Some of the worst enemies a developer has are noise and uncertainty in code, because they prevent them from working effectively with it in the future.
00:04:39.930
So before we get wound up trying to implement a feature and already lost in the noise and uncertainty, I ask: what if we could programmatically find unused code to delete ahead of time before we're trying to implement something else in that area of the code? Well, it turns out we can, to an extent.
00:05:02.820
Today, I'm going to describe how a static code analyzer can be built to find potentially uncalled methods. Now, because Ruby is a dynamic, duck-typed language and this analyzer is only static, it's not going to be hundred percent accurate, but it has the potential to point out some areas in our code that we can clear out and add a bunch of deletions to our GitHub stats.
00:05:23.630
We start with some Ruby code that we want to analyze. The first thing we need to do is transform the code into some data structure that we can reason with, which brings us to Part One: Parsing the Code. Now, some of you here know very well how language parsing works and are very aware of how Ruby works.
00:05:44.880
Some of you might not be so familiar, so I think it's important for everyone to understand how things work from the ground up. So this is a really high-level overview of how general language parsing works from a grammar. For example, can you understand the following sequences of characters: "The boy owns a dog"? You could also see: "The dog loves the boy". Now, how could you programmatically determine which of those are correct and which are not? Well, there's a way to do it.
00:06:18.190
I'm going to throw a couple of definitions that may be very familiar to you. The first is a context-free grammar or CFG. It's basically a set of rules that describe all the possible strings within the language. It answers the question: which sentences are in the language and which are not? The other one is Backus-Naur Form (BNF). This is just one of the two main notation techniques for notating that context-free grammar.
00:06:36.190
Here is a BNF grammar for some of the sentences we just saw. It might look a little confusing, but it's not very easy to understand. Every word you see up here is a symbol divided into two groups: the non-terminals, which are denoted by the brackets, and the terminals, which are the actual words. The way it works is that a symbol on the left is replaced with an expression on the right.
00:06:59.360
An expression can be a combination of non-terminals and terminals. A non-terminal is always replaced via some rule, and terminals are the actual tokens found within the language. They terminate at that point, hence they're called terminals. So let's try that first example: let's look at the sequence of characters. Notice I didn't say sentences before; I just said sequence of characters. We don't actually know if this is a sentence.
00:07:29.840
If this is truly a sentence, it must have a subject followed by a predicate. We can pick "The boy" as a subject and "owns the dog" as a predicate. If "The boy" is a subject, it must be an article followed by a noun. We try "The" as an article and "boy" as a noun. We can see that there are rules for articles and nouns.
00:08:02.740
If this is truly an article, it has to be either "the" or "a," which it is! We found it! If this is a noun, it has to be "boy" or "dog"—we found it! You can also parse out the other side until you find the terminals as well. In the end, we've identified every part of what we call a sentence. If you do a little rearranging, you'll see that it creates a tree. This is a parse tree—it's a discrete representation of our language that can be used to reason about the sentence.
00:08:24.479
Let's try the other one: "The dog loves the boy." I'm not going to parse it all out for you, but if you notice, the sentence structure is exactly the same, so it works out well. Now what about "loves boy," though? As you might imagine, it doesn't work. The reason why is that if that's a sentence and it begins with the subject, a subject must begin with an article, and an article is either "the" or "a" in our grammar. At least—"loves" is not a correct article.
00:08:57.120
This is a syntax error; it's not found within the language! So in programming terms, the first two work, and the third one is an error—it doesn't make sense and is not found within the language—there's no meaning. So what does this have to do with Ruby? You can ask Ruby the same question: how does Ruby know the meaning of these characters? How does Ruby know that this is a class definition with two method definitions in it, the initialize method with a name parameter?
00:09:30.580
My English examples were easy because we skipped lexing, tokenization, and actual programmatic parsing, but hopefully, it captured the high-level essence of parse trees for you. It's a bit more complex how Ruby accomplishes it, but this is what Ruby does: it takes in the parse.y grammar file, puts it into Bison, which is the parser generator, and the resulting parsed code is used to take your Ruby code, tokenizing it into tokens, parsing that into an abstract syntax tree, and that's eventually compiled into virtual machine instructions.
00:10:13.690
The parser generator from Bison has what's called an LALR(1) parser. I'm not going to describe how an LALR parser really works today because it's a bit out of scope, but I'm going to plug this excellent book. The diagram I just showed you is from the book called "Ruby Under a Microscope," written by a fantastic human being named Pat Shaughnessy. In it, he explains all about Ruby internals. The first chapter is all about tokenization and parsing, and it includes an in-depth explanation of the LALR parser algorithm, so you should definitely go check it out.
00:10:31.460
So that's how Ruby does it. How are we going to do it? We're going to do it a little differently. We're going to make use of a gem that you might have heard of called Ruby Parser. It is a Ruby parser written in Ruby, and it uses a Rack under the covers as a dependency. The dependency, Rack, is an LALR(1) parser generator just like what Ruby does. Let's look at an example.
00:11:02.540
We have a class called Person with one method definition that takes in a name and says hello. You can initialize a new person, and you can say hello Ruby. If we throw that example in a terminal, we can call Ruby Parser's `current_ruby_method`, which returns an instance of Ruby Parser for the particular grammar of the version of Ruby you are currently running.
00:11:16.490
The instance has a `parse` method, which can read a file and parse it. The output is an S-expression or a sexp; it's a notation for nested list data, originally coming from Lisp. Nested list data is tree-structured, and this is perfect notation for describing parse trees. This data contains the structure of our code.
00:11:40.380
You can see the block up there is the top-level context; there's a class definition called Person that has a method definition node called greet with an argument called name—a call to puts, etc. Now that we have a parser to put our code into a format we can work with, we need a way to process it. This brings us to Part 2: Processing the S-expression.
00:12:13.140
Before we do something really useful with our sexp, we need a way to easily manipulate it and start getting some general information that we care about: information like finding where methods are defined and in which classes. So we're going to begin to process everything by building a very minimal, tiny class called Minimal S-exp Processor.
00:12:35.430
The goal of this class is simply to run dispatch, calling a method given a node type in the S-expression if it exists. In our initialization method, we'll build a sort of dispatch hash. We'll take the public methods in this interface, find all of those that start with the prefix `process_`, and then key them within a hash according to their suffix. So for instance, if we had a method named `process_definition`, we would seek out the method, take the suffix, and place the method name as a symbol within the processor's hash key to that suffix.
00:13:07.160
Next, we'll write the main method for our processor called `process`—every node in the tree will be passed into this method. It simply looks into the processor hash to call the correct processor method given the current expression's node type. If there isn't one, we just call a default method, which can be passed in as an option. If we don't have a method to call and didn't set a default, we return nil. We'll also put a cute little warning output to say that if we didn't recognize the node type being processed, we'll call this default.
00:13:32.870
If we didn't recognize the node type being processed, we're going to warn that we're calling a default method if that's really what we're doing. This class, by itself, is pretty worthless without any processors, but this is meant to be a base class.
00:13:57.270
To demonstrate an example of a processor subclass, I'm going to define a subclass called Silly Processor. Within our Silly Processor, we'll define two process methods: if we encounter a method definition in the expression, `process_definition` will be called, and `process_not_definition` will be the method that we will set as a default for all other node types. Now, the methods just call puts to tell us some information about the node.
00:14:30.099
If we encounter a method definition, we'll say, "Processing a method definition node with the method name," and for everything else, we will just say, "We are processing this node with this particular node type." Both of these methods call some method called `process_until_empty`. I'm going to look at that one now.
00:14:56.200
`Process_until_empty` iteratively shifts and calls `process` on the next node in the expression until the expression is empty. Every processor method calls this in the end to start parsing the next node. Lastly, we'll fill out our `initialize` method to call super and the parent first, and then set some options that we want.
00:15:23.940
So in this case, we're going to say, "Hey, if you don't know how to process a particular node, you're going to call `process_not_definition`, and we're going to turn off the warning about calling that because most of them will probably call that anyway." There is our Silly Processor.
00:15:50.400
If we put that in an example, we can get an instance of Ruby Parser, make a sexy, and then process that. It outputs pretty much what you would expect—it's just calling 'I see the block node, I see the class, now oh here's a method definition node, it's called greet.' Then it processes everything else.
00:16:17.000
Now, this might seem rather pointless—and that's because it is. But it demonstrates that we've now added the next tool to our toolbox. We are at the point where we can run whatever code we want at a given node, allowing us to build more complex things, like a method tracking processor.
00:16:31.390
Using some information from Ruby Parser, we can now record where we see method definitions in their classes and their line numbers. Setting this up, we're going to use the same options as our Silly Processor, but there are a few new things.
00:16:49.070
You can see there's a class stack and a method stack, which are just initialized as empty arrays. There's also a method locations hash that we will populate with the method signature as keys and the filename and line number as values, taken directly from Ruby Parser.
00:17:13.050
Next, we'll write out our process methods. The first one `process_definition` is just going to shift the node type off the expression and find the name. It's going to call something called the 'in_method' that we'll show in a minute.
00:17:32.550
Then, just process everything in that definition until empty. `Process_class` follows the same sort of thing—it’s just going to call `in_class` and then lastly that `process_until_empty` I showed you earlier.
00:17:59.310
The two location methods that actually do the work, as I said, are `method_in` and `class_in`. Hopefully you can see that they are very simple; they both just add the current method or class to their respective stacks and pop them off once we yield to the block passed in.
00:18:15.850
With `in_method`, we also record the current method signature in our method locations hash along with its location. When entering a new class, that’s a new method space, right? You might have methods defined in and out of that class.
00:18:44.290
When we enter a new class, we give it a new method stack, saving the old stack, using the new one for that class context, and then reverting back to the old stack when we're done processing.
00:19:07.170
Lastly, we have a couple of little helper methods: the current class name is just the first class name in the stack, and the current method name is just the first method name in the stack. The signature we are going to say is the signature that you are seeing: class with the little hash symbol and the method name.
00:19:32.630
So there we go! Let's give that a try. We will expand on our example a little bit. Our person class will now add little say goodbye, which is pretty much the same thing we have, and we will add a new class called Dog with a method called bark—that’s it.
00:19:50.580
As far as what yet, the things to pay attention to are where the method definitions are. So, there's a method on line two, six, and twelve. If we throw that in a demo and pretty print the method locations after processing, we look like this: person greet is in example 2.rb line 2; say goodbye is on line 6; and bark is on line 12.
00:20:10.280
Awesome! We now have where methods are defined. The generic processors that we've built so far to process the S-expression tree and record method locations provide the footing with which we can build our tool. The only thing we need to do now is call and process the call nodes within the tree, see what's being called, and then line them up with what we're now tracking.
00:20:27.569
This brings us to Part 3: Building the Dead Method Finder. Okay, so we finally reach the point where we can build the dead method finder we've been working towards. Let’s create a class called Dead Method Finder that will subclass our method tracking processor that we just built.
00:20:54.259
We're going to maintain two very important collections. First, `known` will be a hash containing sets; we will use this to maintain a mapping of method names to the set of classes that define them. Secondly, we'll call `called`—it's just a set of methods that were called.
00:21:12.840
We'll write our two processor methods. For `process_definition`, we will key into the `known` hash, adding the current class name being processed to the set of classes that call this method. Then we'll call `process_until_empty` on the remaining S-exp nodes.
00:21:36.740
For `process_call`, we're just going to add the method being called to the set of called methods.
00:21:40.700
Next, we'll define an `uncalled_method` method—this is where we will take the difference between known and called methods, in other words, the ones that aren't being called. For each uncalled method, we then key into the known hash to find where a method by that name is defined—by class and line number.
00:22:08.070
We also have a little helper method called `plain_method_name`, and that's just because the method name for the Ruby parser is a string in a certain format, but we're going to use symbols for comparisons.
00:22:22.740
Let’s give that a try! We're going to expand our example just a little bit further. Instead of greet and say goodbye just calling puts, let’s have it use a helper called speak. We're going to add a pet dog that takes in a supposed dog object and sends it the method pet.
00:22:41.110
With our dog class, we're going to add an accessor called fed because if you need a bulldog, you need to know whether you fed the dog, and also another method called pet in Dog to add a little bit of realism. Our story goes: I have a dog named Ruben, who is the dog.
00:23:03.820
Ruben will bark, and then Ruben will say goodbye at the end. Notice that say goodbye is never used down here, and neither is fed—the getter or the writer are not used.
00:23:18.990
If we put the processor on the called methods after processing, we get this little hash: it tells us that okay, say goodbye in the person class and pet in the dog class are not used. Well, this is not right!
00:23:40.430
Remember we said, "Hey, I have a method called pet dog, where I pet the dog? It's used in there, it's being used by another method somewhere—not a dead method, right?" Well, if we look at the S-expression, we can see what the issue is. So this is saying, hey, method call to send on the dog is sending to a string, or a literal symbol, of pet.
00:24:00.420
The problem with this is that our `process_call` is using send as the method being called, which it is. The thing is, we want to take into account that sending implies a method call directly. In other words, we’ve hit an edge case!
00:24:16.600
Looking at the expression, we can find where the actual method being called is, which is the argument, and add some logic to say that that is indeed the method being called. We will say that when we process a call, if the method name is `send` or `__send__`, we're going to just add that argument to the called hash instead and process until empty.
00:24:32.290
Alright, we give it a try again, and it turns out it’s being used as a call node, so it doesn't show up in our output. So that's great, but it's still not correct. This guy up here, our accessor 'fed', is never actually used.
00:24:48.310
If we look at the S-expression, we can realize that a direct accessor is itself a method call that defines methods for the getter and setter, which is why our method tracking processor didn't find them. So we add another edge case in our processor.
00:25:11.969
When the method name is an accessor, we can go through and record that method name and the name equals as a known method. So 'record_known_method' is just a little abstraction that we made as a helper method that does the same thing we were doing in our process definition method.
00:25:34.680
Let’s also pretty up that output into something a little more readable. Let's define a method called report that looks through the uncalled methods for each of them, looks up the location of that method via the method locations hash in our parent class, and throws all of that into pretty formatted lines to report compacted for posterity.
00:25:54.580
We skip this class if there are no uncalled methods. If there are, we join it all together and print it out. Processing the code now is just getting the S-expression, processing it, and calling reports.
00:26:14.380
Here's what the output looks like after we fixed the accessor case and prettied up our output. So awesome! We have person say goodbye in example 2.rb, line 7; and dog, fed, and fed equals both defined right there.
00:26:41.960
Remember that this static analysis tool is not always one-hundred percent accurate, and these are potentially uncalled methods, so we should still do some manual checking ourselves to be a little more certain that these really are deletable, as suspected. It looks like they are deletable in this very easy example.
00:27:08.330
Doesn't it feel great? Isn't deleting code fun?
00:27:25.650
So we're done, right? We made a dead method finder, and now we can start finding code to potentially delete left and right! It's time to open a dozen new pull requests and add a bunch of deletions. Are we truly done?
00:27:41.700
No, we're not. Ruby is complex to parse, at least! The good news is that adding edge cases is easy. Let’s look at that accessor `fed` again. If I say `Ruben.fed = true`, Ruben is my dog, and if we add that to the code here, you'll notice that it's still marked as being called.
00:27:57.770
Now, if my dog were here and saw that him being fed was an issue, he would probably just say, "Deal with it!" That's an actual picture of my dog wearing sunglasses. I sometimes call him Ruby.
00:28:18.640
Let's fix that edge case! So this is an attribute assignment node, right? It's just a node that we haven't parsed yet; we haven't processed it. It's easy: if it's an attribute assignment of Ruben, and the method name being called is right there, we will add it to the called set.
00:28:35.210
Now we run it again, and we find out that it does actually work. Perfect! Well, there are so many more edge cases. What about Rails methods? Every bit of Rails DSL in controllers and models that you're used to using would create edge cases, and there are many of them.
00:29:01.060
Think about it! There’s after_commit, before_create, after_update, before_destroy, before_filter; it’s not called before_filter, it’s called for action! Now there’s around, validations, validates length of, validates format of, validates cuteness of, validates confirmation of, and there’s a lot of stuff to go over.
00:29:17.560
What about my own DSL? In ManageIQ, we actually have our own virtual column implementation for Active Record. This digs deep into Active Record internals to allow us to treat any method as a database column, amongst other things. It’s mainly used for reporting purposes, reporting attributes of entire tables with extra attributes sprinkled in.
00:29:41.490
We actually have a DSL in Rails models in the form of virtual column calls. Let's take for example a class called Disk that might have many partitions. We can say that a virtual column called allocated_space of type integer uses all of those partitions.
00:30:00.730
My point here is just that this DSL and Rails DSL calls aren't that difficult to handle; they're just another edge case. All of these methods look essentially the same, right? Most of the time, it's just arguments of symbols naming methods to be called.
00:30:15.237
I’m not going to go over it each little thing, but it's the same sort of thing. We can keep a collection of everything that we would expect, take all those symbols and put them into the call set. My point is just that, as with most things, with the right tools, the job is not very difficult; customization is easy.
00:30:33.675
Another thing that’s really easy is that you can execute this code on your project right now! There’s a Ruby gem called DeBride, which helps find dead contaminated or adhering tissue or foreign material.
00:30:50.370
When I first thought of programmatically finding dead code, I went down the same path that we just went, starting with Rack and Ruby Parser. I then discovered the lovely simplicity of processing S-expressions with a gem called SexpProcessor. It was created to easily do generic processing of the S-expressions given by Ruby Parser. It also provides a method-based S-exp processor to do the method and class tracking.
00:31:10.810
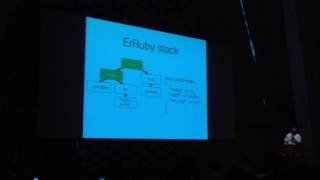
I then, to my great delight, stumbled onto DeBride, which does exactly what we just did today with our dead method finder. What’s more is that everything you see here on this stack for Ruby Parser is written by the same person—Ryan Davis and the Seattle Ruby Brigade.
00:31:31.640
Some of whom I know are back there! I’ve been hacking on DeBride for the past several months, customizing it for ManageIQ, and finding cruft to delete in a project that started in Rails 1.2.3 nearly a decade ago. I thought it would be fun to rebuild the basic concepts for you today.
00:31:51.300
So what does DeBride provide for you that we haven't covered today? Well, it covers more edge cases! First of all, our simple method tracking processor and dead method finder are the core of what DeBride does, but there’s much more to consider.
00:32:04.560
What about class methods with def self.method_name? What about defining methods on singleton classes? There are many cases yet to be handled. It also adds all sorts of options, like 'hey, I want to exclude certain files,' or 'I want to whitelist a particular pattern for methods that I know are definitely called.' Maybe you want to focus on a particular path or enable Rails mode, which looks like what you just saw.
00:32:25.170
I mentioned that I've been hacking on DeBride to find even more dead code. Besides adding your own DSL, whitelisting patterns, and all that, you can easily do something like this to find other criteria for what might be deleted code.
00:32:49.920
Remember what I said about methods that might be much too context-specific that only have one particular caller? Here’s a hack to find those methods. Instead of a set, we will say that called is a hash keeping track of method names with a particular counter. Each time we process a call node, we will just increment that counter.
00:33:05.050
So, all the ones that are called once are just all of the called methods with only one call. It could be that a method is totally fine having only one call to properly written, but I found it's easy to look through these and find ones that might be too specific and can potentially be rewritten or just deleted.
00:33:21.420
Some future considerations: I've been busy enough hacking and deleting code that I haven’t refined it enough to push it upstream. Some work I’ve done includes finding a couple of bugs and clean-ups, but wait there’s more!
00:33:43.630
Remember, tools like this are but one tool in the toolbox when finding ways to clean up your codebase. Today we looked at one way to parse and statically analyze Ruby to find potentially uncalled code. There are so many awesome tools to be used in combination.
00:34:01.670
For example, Tom Copeland has a project called Old Code Finder which looks through code content line by line by date and authorship. It tries to find patterns, and say, 'Hey, this chunk of code is really old; you should maybe take a look at it.' If a chunk of code is written by someone named Fred who left the company six years ago, maybe you should look at those particular bits of code.
00:34:19.860
It was also unused by Josh Clinton, a project that I haven't even looked at yet. It’s written in Haskell and utilizes ctags to find statically unused code and it can use anything because it’s implemented with ctags. I love ctags, so I'm excited to dig into that myself.
00:34:47.037
So before I go, here’s a parting message for you: if you remember mer before it was merged into Rails, you might recognize this: no code is faster, has fewer bugs, is easier to understand, and is more maintainable than no code at all! So when you go home, delete some code; it feels wonderful!
00:35:18.999
Thank you!
00:35:36.599
Thank you, Chris! I am sure that people have lots of questions for you. As it turns out, we have time even though it seems we may not—
00:35:58.700
The other room is about ten minutes late, so we're going to add some questions if that's alright with you.
00:36:06.650
Thank you for a great hook and talk; let’s go on to the questions.
00:36:14.480
So from current architecture, is it possible to detect a coding cycle? This means if `method_a` calls `method_b`, and `method_b` calls `method_a`, but no other methods have called them at all, is it possible to take a picture and detect this case? Should we spend more time on that? I think Amelia's—
00:36:42.080
But I want to make sure that I got it right. I'll say it again: if method A calls method B, but no other methods call it, can we identify such a case? So, the question is if you have a couple of things: where there might be like two methods that don't actually do anything in the project that call each other that would be counted as used methods? The answer is no right now.
00:37:12.570
It might be the kind of one of the things I’m pointing out with the call tracking I showed at the very end; an example would be found in that hack. You would see, "Hey, this is only called once, and when you actually looked at it, you can see, ‘Oh, that thing is also only one call away!' You can find that case.
00:37:30.930
So I think it would be really interesting if we added the ability to find those cases separately. You might have uncalled methods and then ones that have a certain factor of like a certain grade for whether or not that might be uncalled.
00:37:54.290
So yes, very cool! Thank you!
00:38:04.430
So how are you doing with the action methods in controllers? Generally, there are usually no explicit calls to the actions, but they are usually used or maybe not used.
00:38:27.019
Sorry, I could be more timely! Go ahead!
00:38:43.230
Yeah, and how do you find unused methods in controllers? Well, it's the same sort of thing, right? You have a node call, so you would find that with the DSL example I gave earlier. You would see something like before_filter in some method and register that as an actual method call.
00:39:06.030
You can see that the method name passed to before_filter is a called method, and that would flag it as to whether or not it is actually called. I hope this answers your question! If I could be of any more help—
00:39:30.050
I think it's working okay. There's a gem called TraceRoute, which looks at whether there’s a one-to-one mapping between routing declared in the routes.rb file and the actions in the controller file.
00:39:54.480
So the question that you asked is basically, hey can we find out if a controller method is uncalled based on a routes file? The answer is I don’t actually know. I don’t think route parsers do that, but it’s the same sort of thing.
00:40:15.922
You could theoretically do that; I believe you can do that with a gem that might exist for that.
00:40:40.700
So there’s a potential for how to do that! When it comes to uncalled code, often what happens is that there’s an existing method that used to be called by other methods, and then after a while we deleted the code without deleting the method itself.
00:41:01.300
By the way, are you familiar with git bisect?
00:41:28.490
Yes! Is there any way of combining git bisect with the class and method name you're interested in, and try to get git bisect to identify for you the commits that caused it to fail the analysis?
00:41:50.153
Yeah, I don’t see why not! The way I look back at the history is with ManageIQ. It's a very old Rails app with a huge amount of code, and I’m deleting methods that might be eight years old. If you can look back through the history, there are a couple of little git aliases that I use.
00:42:06.590
There's a log has AG option for bringing in regular expressions, so you can look back at the history and have a nice scrolled output of how that method call might have changed over time.
00:42:22.800
If you keep scrolling down, you can see that as you go through the history, you can read what methods were created and when they were removed.
00:42:37.250
I don't actually see why you couldn't do that to find a method definition that was deleted and to go through the history and see if there weren't a certain number of calls to that method or if they were removed.
00:42:56.670
So yes, it's quite possible!
00:43:13.299
I think I’ve explained it. Thank you!
00:43:25.130
So you used the gem for your production code, right?
00:43:41.240
Yes! How many times did you delete code that should not have been deleted?
00:43:55.660
How do you think that the tool helped you to avoid that?
00:44:13.210
The answer is maybe more times than people would like!
00:44:30.350
Actually, it’s not too hard. Because of the edge cases, I said that Ruby, as you know, is a very dynamic language. You can call methods in really weird ways.
00:44:53.300
It's possible that you can interpolate a string and send it to send and such.
00:45:10.500
Fortunately, using some of the tools I just explained with my git aliases, I can look through history and see that this method was created here and removed here.
00:45:25.420
Most of the time in code review, my coworkers can look through, and when they bring up, 'Oh, it's actually used here; you don't want to remove that.'
00:45:40.420
So it hasn't become a problem where we merge something and everything breaks due to deleted methods.
00:45:59.120
So was there another potentially good question?
00:46:12.140
Thank you! Oh, Tatsu, good! I shikari muscat all of my gosh.
00:46:30.390
She’s falling on us in cotton!