00:00:00.900
foreign
00:00:13.280
How's it going? It's almost over. I know you've heard this a lot over the past couple of days, but I just wanted to acknowledge how nice it is to be all in the same room together again.
00:00:19.199
Of course, there's no guarantee that things might stay like this, but look at us, we're all here. This is great, right? Come on!
00:00:25.019
Because we're physically here in the same space, I can do things I couldn't do at home. Like, I can do this.
00:00:36.440
Well, I guess I probably could have just done that at home, but I can do this. Come on, give it to me!
00:00:43.140
For those of you that I haven't met, my name is John Crepezzi. I am a longtime Ruby developer.
00:00:49.260
I'd love to tell you more about myself, but I needed to cut some content from this talk, and I'm just so excited about the work I'm going to show you today that it didn't feel right to cut anything else. So, if you want to get to know me, you can find me after the talk or you can find me on Twitter.
00:01:06.420
In reflection, right now, this kind of looks like I died, but it is what it is. I've been working at GitHub for the past five years, and for most of that time, I've been working very closely with our large monolithic Rails application, which we call GitHub.com.
00:01:18.659
Affectionately, internally, we call it GitHub GitHub. We've had multiple large Slack conversations about what does that mean—Is it the monolith? Is it the website? But in the end, is it going to change? No.
00:01:38.400
It's been covered a lot in our talks by developers over the years, but GitHub's monolithic Rails application is definitely operating at or near the largest scaled Rails applications of all time, scaled in terms of traffic for sure, but also in terms of size, and likely also the number of contributors. After 14 years, we've racked up 400 models, many regular active developers, and we've even presently sharded our data across 17 separate database clusters, each of which we also run replicas for.
00:02:06.360
I joined Eileen in her keynote last year, which was great. Did everyone see the keynote? We did this great green screen execution and we talked about changes that we made Upstream to support granular sharding and roll swapping. The database connection management work that we talked about last year is just part of a never-ending series of threads that we're pulling on to expand the boundaries of Rails as a framework.
00:02:35.340
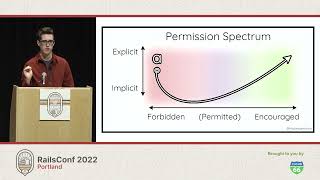
In this talk, I'll be going through a few other threads that I've been pulling on, particularly some things that we've noticed as our application continues to scale. These are things, mind you, that are present in pretty much every ORM that implements the ActiveRecord pattern and some experiments that I've been developing on top of ActiveRecord to tinker with ways to solve these pain points.
00:03:04.739
Upfront, it's worth covering the distinction between the ActiveRecord pattern and ActiveRecord the library. ActiveRecord, the Rails ORM that we kind of know and love, is a Ruby implementation of a design pattern outlined in the book 'Patterns of Enterprise Application Architecture' by Martin Fowler.
00:03:15.420
I keep trying to get my kids to read this, but they haven't. ActiveRecord is not the most creative name for a library implementing the ActiveRecord pattern, I’ll admit, but it seems to be pretty par for the course. Martin, in that book, also talks about the Data Mapper pattern, which was implemented in the popular Ruby ORM known as DataMapper.
00:03:33.420
So what do we mean when we talk about the ActiveRecord pattern? The pattern at its core is the idea that you can take a class that represents a table in a database and interact with individual instances of that class, each representing a row from the owning table. By interacting with these models, we largely don’t have to worry about the underlying SQL, and we can execute database calls.
00:03:58.799
In Rails' implementation of ActiveRecord, these classes are defined and owned as part of your application code, so the methods you’re defining on your models live right alongside the methods that are automatically created by the framework for dealing with the database. When I create a new user, I can access the implicitly created login or name methods, or I can access my own methods, in this case, `display_name`, which are defined right alongside them.
00:04:34.259
This is really powerful for a few reasons. The first is that the ORM pattern takes something that’s really familiar to us—the idea of classes and instances—and lets us reason about databases in the same way. While I definitely still think developers should know SQL for performance implications, it is reasonable with ActiveRecord not to write even a single line of SQL and still implement an application.
00:05:03.060
Next, there are fewer moving pieces in ActiveRecord. We've combined essentially the data layer and our application code into one, so there's less surface area, fewer files, and fewer interactions between different parts of our application that we need to write tests for. Lastly, we don’t have to write a lot of repetitive code to accomplish standard tasks, as inheriting from ActiveRecord::Base provides us with a ton of functionality for free.
00:05:51.840
On the other hand, there are some drawbacks to this. First, not all the concepts that we want to represent in our application strictly map to a single table. We often end up testing with our database in place because our application and data layers are so tightly coupled.
00:06:02.100
Next, our objects unintentionally expose a bunch of extra surface area. We typically only test the methods that we expect to be used, but what about all those other methods that are defined by ActiveRecord? What's to tell future developers on your application that those methods shouldn't be used, and how does that scale when you add more developers?
00:06:50.880
Lastly, it’s really easy to write inefficient code, particularly concerning relations and column over-fetching, both of which I'll cover in a moment. If you notice that a lot of the drawbacks I just described are kind of the inverse of the pros, that's definitely not an accident. It kind of highlights that most of the decisions we have to make as software developers are about trade-offs.
00:07:30.240
Most of the time, something like terseness can breed ambiguity. Things like normalization can lead to code sprawl. What you're feeling when you use Rails—and a lot of the reason that most of us are in this room right now—is a set of decisions that lean into the expressiveness of Ruby, with the expectation that most applications built on Rails will have a similar general structure. To tip the scales on some of these decisions in favor of more compact code without losing readability, ideally we want to stick with that theme when we introduce newer and more advanced ways to interact with our databases.
00:08:43.140
It's okay to acknowledge that ActiveRecord, as a pattern and as a framework, is tightly coupled because that's a design choice made by the library and by the pattern. With that lens, I've been looking at two problems that we've been encountering more and more at GitHub with ActiveRecord—batch loading and code ownership in applications shared by many teams.
00:09:26.460
So let's just jump right in. We’ll start with batch loading. In web applications, a common pattern is fetching and iterating over a collection and then doing something with each of the records.
00:09:50.760
In Rails applications, this is normally done in the views, and it looks something like this. This is all well and good, as long as the method we're calling is cheap to execute, like in this case when we're calling `title`, which is cheap because it’s already been loaded into memory by the call that retrieved all the posts.
00:10:44.279
There’s one query here for all the posts. Sometimes, though, the things we’re doing within the methods aren’t cheap. We may be loading another association within each iteration.
00:11:19.980
This is known as an anti-pattern, called N+1. It's N+1 because there is one query for the base set of records at the top, and then there are n queries, one for each thing we need to load—in this case, the comments. Given the way the ActiveRecord pattern is structured, it’s easy to automatically introduce these N+1 queries into your application if you're not intentionally looking for them.
00:12:45.660
Typically, the answer to resolving this is to use something like `includes` to pre-fill associations for all of the given records. With `includes`, you call `includes` and pass a symbol representing the association you need to load.
00:13:34.980
Once you do this in the view, you won’t have any more N+1 queries. Instead, it will just execute two queries—one for the base collection to get all the posts, and then one for all the associations.
00:14:07.740
This is a great feature of Rails. Without ActiveRecord handling this for us, it would be quite complicated. This is an example of implementing includes without using them, and it gets even more complicated when you consider that `includes` calls can contain nested associations.
00:14:42.780
One thing that's really neat about `includes` is that it keeps developers from having to maintain two separate implementations for batch and non-batch uses. Let me explain. A lot of times we have data that we need to use in multiple contexts. For instance, in the case of a comment count, we might want to include that on the list of posts, and then when we go to the display page, we also want to have the comment count there.
00:15:34.440
`Includes` lets us write one implementation that transparently handles the batch loading details under the hood. We write the single version, and we get the batch version for free as long as we stick to Rails conventions.
00:16:34.080
However, a few questions arise when you start using it. For example, how do we know if we’re missing `includes`? Has anyone ever seen anything like this in their application logs? The default answer is that for missing includes, we're relying on developer diligence.
00:16:56.100
A lot of the times, we spot these in our query logs as they go by, and we put effort into removing N+1 issues from our hot paths, but we often don’t pay enough attention to other actions within our applications. There are solutions to this, one of which is a gem called Bullet that can help by detecting N+1s in development.
00:17:39.960
Who has used Bullet? Nice! A lot of people! Also, last year, I think Eileen and Aaron in Rails 6.1 introduced a feature called strict mode or strict loading. Essentially, this feature prevents developers from mistakenly loading more associations than they expected to.
00:18:09.240
What happens if you have an extra includes? It turns out that the data still gets loaded. This can make it hard to keep two things in sync and prevent over-fetching, which is one of the other ergonomic issues with `includes`. Consider especially that things needing to be loaded upfront don't actually correspond to the name of the association needed for performance.
00:18:49.740
There are no clear ways currently to discover or remove includes that aren’t needed, leading to over-fetching in our applications. You have a choice: make it efficient by adding includes and risk doing too much work, or what if the thing you’re loading isn't a direct association but has extra conditions?
00:19:37.260
What if the thing you’re loading is a count, and that's an N+1 situation too? There are solutions for a couple of these things, but what if the thing you’re loading is calling an external service that's not even related to the database? Then `includes` can’t help us anymore.
00:20:20.760
So where do you put the `includes`? You need to put it somewhere and be able to keep it in sync with the rest of the code. There are two approaches: the first is to put it in the view.
00:20:36.900
This seems tempting because it puts the includes next to the method that's being called, so you can try to keep them in sync due to proximity. However, in views, we often use partials, and things start to diverge. Suddenly, you have the includes being called at a different spot than the thing potentially adding more things that need to be loaded.
00:21:04.800
The other option, other than the view, is to put it inside the controller. This is the standard approach a lot of people use, but it has problems too. First, keeping the controller in sync with every change in the view comes with the same issues as with partials.
00:21:43.680
Moreover, even if one method is added to an iteration, you might feel tempted to add the appropriate includes, but what do you do when you want to remove the use of a method? Now you have to figure out which includes correspond to that method you removed, and whether that include is still used in other places for other methods.
00:22:29.760
Lastly, what do you do about things like conditional access? If something is used conditionally, say to show things only to admin users, how do you split off those concerns cleanly from the main includes? In this case, you would need two separate includes, and you'd also need to mirror the same logic within your view.
00:23:00.000
Clearly, while a great tool, includes has issues that makes it really hard for developers to use and maintain consistently.
00:23:43.440
Around the time that GraphQL started to become popular for us at GitHub, these problems really boiled over. We were creating a GraphQL API, and for the reasons I just mentioned, it's hard to maintain `includes` when operating within a normal application.
00:24:01.920
But how do you safely preload data for a query that's arbitrarily nested? You must fix the N+1 issues here because failing to do so exposes your application to denial of service or very slow requests. You can’t just write in includes because they need to be dynamic based on the fields being requested.
00:24:43.680
Shopify came up with a neat library for batch loading called GraphQL Batch, which you can read more about on the Shopify blog. Here’s a basic overview of how it works: you define loaders by creating a perform method, and within that method, you call fulfill for each of the IDs passed in. Essentially, you’re creating a mapping between the requested things and the things that are output.
00:25:24.180
Someone at GitHub, when implementing the internal GraphQL batch that we use, changed how the perform method works. Instead of using `fulfill`, all perform methods should be implemented in terms of a particular signature.
00:25:57.120
This signature represents an array of IDs to a hash from ID to value. It’s essential because it summarizes the generic idea of what a batch method is. The collection of items for which I want to load some data is passed in, and the batch method is essentially a method returning a hash of ID to value.
00:26:39.300
By using this library effectively, you can avoid asking developers to think in terms of includes, and you can successfully implement a GraphQL API that doesn’t suffer from most types of N+1 problems. The includes are built into the implementation, freeing developers from needing to write them.
00:27:16.920
However, we still face issues. First, we don't want to use this solely in GraphQL; we want this concept everywhere. Second, defining loaders for a platform in a separate file from our model is good for separation of concerns, but it doesn’t feel very Rails-like.
00:27:53.760
Lastly, promises can be awkward for Ruby developers. In fact, promises are awkward in general, and they're definitely not part of the toolkit for most Ruby developers.
00:28:26.520
The more I thought about the generic representation of what it means to be a batch method—the hash of ID to value—the more I started experimenting with the same idea inside a library that we began using internally at GitHub called Prelude.
00:29:10.620
In Prelude, you define a batch method on your model using the Define Prelude method, which conforms to the same signature we discussed. You can call it like a regular method, and when the view requests a certain piece of information for the first time, it runs the batch method, loading all of them.
00:29:43.320
We no longer need includes, as we’ve tightly bound the includes to the implementation inside the model, resulting in no more N+1 issues. It's pretty cool!
00:30:05.700
In essence, it’s the inverse of includes. Here, we define the batch version, and we get the single version for free. Similar to GraphQL Batch, this library allows us to interact with private data APIs while only yielding objects of the same type.
00:30:25.320
This library is still in the early stages of development, and if you're interested in finding out more, the implementation is more complicated than many of the other solutions and is available at this link.
00:31:01.020
Let me recap. We talked about N+1 issues, how they’re typically solved, and a new library called Prelude that we've been using at GitHub to manage these challenges.
00:31:05.220
We also discussed code ownership in Rails applications and how we can ensure that we’re only exposing the APIs we intend to others across our application and among teams.
00:31:24.120
These topics are interconnected, typically becoming meaningful issues in more evolved codebases, and we tend to solve them with workarounds. In both cases, I propose that we can address these issues through the introduction or modification of APIs within ActiveRecord to guide developers toward best practices.
00:32:19.320
I hope this talk and my experiments have given you something to think about. If you don't agree with me, that’s fine, but maybe they spark something in your mind. Just remember, I drank a smart water this morning, so there’s a pretty good chance I’m right.
00:32:28.640
I hope I've inspired everyone to see ActiveRecord as a library we can mold and evolve to suit the next generation of Rails developers.
00:32:34.500
Thank you to the countless people who helped provide feedback on these ideas, some of whom are in this room. Thank you for having me speak here this year, and thank you for being a part of this amazing community that I love.
00:32:57.840
Have a great rest of your conference!