Background jobs
Growing Your Background Job Knowledge
Growing Your Background Job Knowledge
by Jake AndersonIn the video titled "Growing Your Background Job Knowledge," presented by Jake Anderson at RailsConf 2022, the main focus is on understanding background jobs in Rails and their significance in web application development. Jake begins with a relatable analogy centered around brewing coffee to introduce the concept of background processing, highlighting how waiting for tasks can hinder user experience. The talk unfolds through several key points:
- Understanding Background Jobs: Jake emphasizes that background jobs allow certain tasks in web applications to process asynchronously, improving user experience by not blocking requests.
- Problem Simulation: Starting with the example of a Rails request, he explains how each step in the request must be completed sequentially, thereby illustrating the potential for delays when intense logic is involved.
- Introduction to Background Jobs: By drawing a parallel to waiting for coffee to brew, he illustrates the advantage of using background jobs, which can perform tasks like sending emails or processing data without forcing users to wait.
- Active Job in Rails: Jake delves into how Rails provides a streamlined implementation of background jobs through Active Job. He explains the three basic steps: creating a job class, adding it to the queue, and letting Rails manage processing the job.
- Job Management and Queueing: The importance of queues for managing concurrent tasks is discussed, highlighting how they help prevent system overload and provide visibility on task statuses.
- Practical Features of Active Job: Jake touches on how Active Job supports features like job delays, prioritization, and error handling, enabling automatic retries and logging.
- Conclusion and Takeaways: Using the coffee analogy, he reiterates that while some tasks require immediate attention, others can and should be processed in the background, allowing developers to optimize workflows and improve application performance.
In summary, the important takeaways emphasize the functionality and benefits of background job processing in Rails to enhance user experiences and manage system resources efficiently. For those interested, Jake encourages questions and further discussions at the Weedmaps booth.
00:00:00.900
Hello, everyone!
00:00:12.679
Are there any coffee drinkers in the house? Yes! I'm not addicted to coffee, but if I don't have it, my day is ruined.
00:00:18.660
I always start my day by going downstairs and getting the coffee maker going. This entails grabbing the filter, throwing that in the maker, grinding up some beans, and putting those beans in the filter. Then, I press that button and walk away to do something else, like feed the baby or have some food myself. I come back 10 to 15 minutes later, grab my coffee, drink it, and now the day isn't so bad. You might be wondering what this has to do with background jobs, and hopefully, by the end of this talk, you'll understand exactly what I mean. I'm Jake, and I'm a software engineer at Weedmaps.
00:01:02.640
If you're not familiar with Weedmaps, we are the leading technology and software infrastructure provider for the cannabis industry. We are also a sponsor here, so definitely come check out our booth; we've got some great swag to give away. We are also hiring, so if you're interested in working with us, please take a look at our careers page to see some job postings.
00:01:28.979
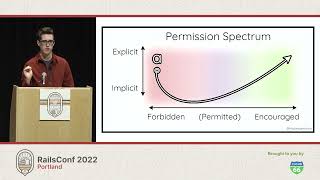
Today's talk outline includes five main topics that I want to cover. First, we will gain an understanding of what background jobs are. I want to preface this by stating that this is meant for people who are just getting into background jobs. If you're already very familiar with them and need help, come talk to me after the talk; I'd be happy to assist. This talk will cater more toward understanding what background jobs are, why they are important, and some cool features that Active Job provides. We will run through this in five steps.
00:02:10.619
First, we'll simulate a problem to establish a starting point to build from. Then, we will dig deeper into that problem and ask some leading questions. We will investigate whether there are existing solutions for this problem. Next, we'll fill in our knowledge gaps with Rails and explore if it has an implementation for any solution we find. Last but not least, we will expand our knowledge and try to learn as much as we can about anything related to Rails.
00:02:36.120
Coincidentally, this process spells 'SPIKE.' This has nothing to do with the agile term 'Spike,' but I thought of it similarly. Fun fact: 'spike' is not actually an acronym.
00:03:05.099
So, what is the problem? Where is our starting point? Let's start with a Rails request. I'll have some diagrams on the side with little animations to provide some context. You've got a router that determines a controller and an action to render, which goes to the controller. The controller then requests data from the model, which talks to the database and returns data back to the controller.
00:03:28.740
The controller sends that information back to the visitor of the site. The most important thing to highlight here is that we need each of these steps to complete before moving onto the next one. We can't go to the controller if the router hasn't instructed us to go there; we must wait for each of these things to complete. This is by no means a complete overview of what a full request is in Rails. If you want to learn more, Skylight did a RailsConf talk on this, and they have some accompanying blog posts.
00:04:11.760
Now, imagine we have a new product request. Surprise, surprise! This request requires more logic in the controller. We're going to simulate this with a service class. For those who aren’t familiar, think of a service as a regular Ruby object that takes in some input, does something fancy with it, and outputs something else. Examples include sending an email, updating a counter, or performing account setup like integrating with Stripe.
00:04:49.199
The important thing here is that we've added another step to our request chain. We are now reliant on whatever this service is doing, and our visitor is dependent on that as well. What if the service takes too long? Maybe it involves sending an HTTP request, and that email server is down, or the database is overwhelmed on a busy day. The visitor is still there waiting, perhaps growing impatient because we're taking too long to fulfill this product request.
00:05:29.880
So, what might this look like in Rails? For this example, let's say we have a Pages controller with an index action. Imagine this is a home page where we call a service that prints a message to the screen. This service is our plain Ruby object with a perform method that sleeps for five seconds to simulate work before printing a message.
00:06:34.560
The terminal output takes over five seconds to complete the request, and all we did was print something to the screen. The question is: did the user need to wait for that? Let's dig a little deeper. Let’s revisit the coffee maker example. Here's a similar chart using coffee terminology. Imagine an uncaffeinated person desperately placing the filter in the machine, grinding the beans, and starting the coffee maker but then waiting eagerly for the coffee to brew.
00:07:24.960
Once the coffee is ready, they grab their cup, drink, and move on. Just like a hanging request, they don't want to wait for the coffee to finish brewing. In the same vein of a Rails request, there are other processes it wants to execute too. If we don't have to wait while the coffee is brewing, do we need to wait for the server call? In some cases, yes, we have to wait; we can't start making coffee until we have the beans ground.
00:08:20.220
But if we don't need to wait—like in our puts example—then the user doesn't care about logging information. Can we press the button and come back to it later? Let's explore this idea. Surely someone has thought of this, and they have—this is background jobs and async processing. Welcome to my talk! In a nutshell, that's what background job processing is.
00:09:16.380
So, what does this look like at a high level? You'll have a service that gets added to a list—we'll call that list a queue—with any associated arguments. In this case, the queue will contain a class—let's call it SomeService—and we’ll add a message to that queue, such as 'Hello, RailsConf.' This adds it to the queue, which may look something like a list of items where we’ve got a couple of tasks already in line.
00:09:54.480
Next, there needs to be something that runs and pulls these items off the list. We'll refer to this as a job. The job will grab the first item off the list, which is the class of our service, along with its arguments. To turn our string class into a Ruby class, we can utilize the constantize method. We'll then create a new instance of this class and call the perform method, passing in the arguments.
00:10:59.280
So, why does this matter? What does it help us with? One benefit is that it prevents too many things from running at the same time. For example, in the controller scenario, if we had a hundred thousand people visiting our page at once and triggered that many background tasks simultaneously, we could bring down our system. By using a queue, we can manage how many tasks are processed concurrently.
00:11:57.500
We can say, for instance, to pull one item off the queue at a time or have a few different processes pulling from the same queue. Additionally, the queue gives us visibility into the tasks that are running or waiting. We can monitor jobs that have succeeded, but more importantly, we can see jobs that have failed, which allows us to retry those tasks if necessary.
00:12:55.120
While we've identified the blocking request problem, we also realize that we don't need to block it if we can place jobs on a queue. For those unfamiliar, Rails has a feature called Active Job for managing and processing queues. It requires three basic steps to get up and running: first, create your job class; second, tell that job class to add itself to the queue; and finally, Rails handles the rest.
00:14:07.800
To create a job, you typically create a new class that inherits from ActiveJob::Base, similar to how a Rails model might inherit from ActiveRecord::Base. This pattern is already established with models, and ActiveJob follows suit. Once the job class is set up, you create a perform method that gets called with your arguments when the job runs.
00:14:47.820
You might also specify which queue the job should run on. Rails provides a default queue, but you can name additional queues according to your needs. To enqueue the job, we simply call the perform_later method on our job class and provide any arguments we wish to send.
00:15:38.160
When the job runs, Rails will automatically take the string class and its arguments from the queue and perform the specified action. An important note on enqueuing is that ActiveJob allows you to dictate when a job should run. For instance, you might want to delay a task, such as sending a feedback email 24 hours after a sign-up, or schedule it to run during off-peak hours.
00:16:39.720
You can also adjust the priority of the job within the queue, ensuring urgent tasks execute before less critical ones. Now let’s discuss how Rails processes the job once it's added to the queue. By default, Rails keeps jobs in memory, which means that you don't necessarily need additional infrastructure to run jobs using ActiveJob. However, there is a potential drawback—the jobs will disappear if the server restarts or crashes.
00:17:35.760
For example, anyone here use Heroku? If so, every 24 hours, your dynos restart, and all jobs in the queue during that restart are lost. Essentially, ActiveJob provides us with building blocks for queue management but isn't enough on its own to prevent losing jobs during restarts.
00:18:29.460
That said, Rails has out-of-the-box solutions for a variety of backends, allowing you to choose the one that matches your application's needs. Whether you need to leverage databases, in-memory solutions, or message brokers like Redis and RabbitMQ, tons of options exist. It’s important to keep in mind that this is not an exhaustive list of available backends and that the Rails team has opted to have libraries manage their own adapters moving forward.
00:19:42.240
Many developers may wonder why they would use ActiveJob when they could simply utilize these libraries directly. The answer lies in the global IDs feature, which gives you unique URLs that point to models. For example, instead of separately sending an ID and model name, you can send a global ID, simplifying the job's process in tracking the model.
00:20:27.030
ActiveJob also supports serialization options for objects that lack global IDs, making it easier to handle different input types. Additionally, it offers automatic localization for jobs, allowing them to maintain the user's language context—even if a job runs much later.
00:21:07.440
Callbacks are a useful feature in ActiveJob that allows developers to define actions that should occur before or after enqueueing or executing a job. For instance, you can log meaningful messages or capture runtime duration.
00:21:59.640
ActiveJob also features built-in error handling, enabling retries for failed jobs based on specified conditions. This means if, for example, you encounter a rate limiting error with an API call, you can instruct ActiveJob to retry the job automatically at progressively longer intervals until it succeeds.
00:22:51.480
The main advantage of using ActiveJob is that you gain a unified API for job management, regardless of which backend you opt for. This abstraction allows developers to move between different Rails applications seamlessly without needing to relearn job management.
00:24:03.240
As I wrap up, let's return to the coffee analogy. We will always need to perform some synchronous tasks, like grinding beans and putting them in the filter, which we cannot avoid—in writing software, some tasks require immediate attention.
00:24:59.640
However, we can press the start button on certain jobs and return to them later, as we don't need to stick around waiting for coffee or other tasks to finish. Similarly, in our coding, it is often possible to re-architect tasks for asynchronous processing.
00:25:45.240
Thank you all for attending this talk! If you have further questions about background jobs, feel free to visit our booth. I'm also happy to dive deeper into any low-level queries you might have. Thank you!