00:00:00.480
Hi, hello everyone! Thank you for coming to this session. Today, I'll talk about how to create a multiprocess server on Windows with Ruby, and I'll show you some basic knowledge and functional Ruby specific to Windows programming.
00:00:07.399
Before starting the presentation, let me introduce myself. My name is Ritta Narita. I graduated from university last September and after that, I joined Treasure Data.
00:00:14.000
Treasure Data is a data management platform service that allows you to easily store and manage your data.
00:00:21.080
Let me briefly introduce the architecture of Treasure Data. Using Treasure Data, you can easily store your data and then analyze that data. For example, if you want to store log data in real time—like server logs or IoT sensor data—you can import this data using a tool called the Fluentd agent.
00:00:39.879
If you already have a large dataset on your storage or database, you can execute a parallel approach using Bulk Input. After importing data, you can query the data using SQL or other APIs.
00:00:58.320
Also, you can output the data to various databases or storage options like Amazon S3 or MySQL. For importing streaming data, we use the open-source software called Fluentd.
00:01:11.280
Fluentd is a data collector for streaming data. With Fluentd, you can easily collect streaming data, and after filtering, referring, or routing, you can output it to your desired destination.
00:01:21.040
In Fluentd, you can set up input and output programs. With these programs, you can connect to your data source and specify where you want to output data. For example, if you want to store access logs from your server into MySQL, you can use an HTTP input program and connect it with an output program for MySQL.
00:01:30.479
Let me show you an example. If you want to input HTTP requests on port 8000 and output these logs to the console, you can use the HTTP input program and an output program.
00:01:42.840
To configure this program, you need to write the input type as HTTP and specify the port number (8000) in the input configuration file. For the output configuration, you only need to match the pattern and set the output type.
00:02:04.640
After executing Fluentd with the correct configuration, you can send a POST request with JSON and output the results to the console.
00:02:17.519
As I mentioned before, you can set various plugins in the Fluentd configuration.
00:02:25.519
Let me show you another example. In Fluentd, there is a command called 'fluentcut.' This tool is used to send JSON to a specific port via TCP.
00:02:38.240
If you'd like to use Fluentd to send data, you can use an input program and set it up just like you would with an HTTP input, along with an output.
00:02:56.639
Let me demonstrate this process. Once the code is executed, you can send JSON data with Fluentd and output it to the console.
00:03:10.240
As I mentioned earlier, you can set up plugins in your Fluentd configuration.
00:03:26.960
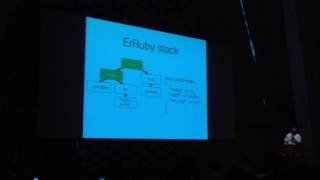
Fluentd utilizes ServerEngine, which is a multiprocess server framework. This is also an open-source software project, and you can check it out on GitHub.
00:03:39.280
Now let me introduce ServerEngine. ServerEngine is a robust framework for implementing multiprocess servers. It functions similarly to Unicorn, allowing you to daemonize and supervise processes and create worker tasks.
00:03:56.480
In this framework, each process is connected via pipes. If ever a worker stops, ServerEngine can automatically reset the process.
00:04:10.840
You can configure it to run with a supervisor or directly with the server.
00:04:24.360
With ServerEngine, you can implement robust multiprocess servers quite easily.
00:04:39.960
Let me show you one function of ServerEngine: automatic restart.
00:04:47.239
If a worker is detected as not running, ServerEngine can automatically restart the process. After executing, you'll see that when you kill a process, the Supervisor will automatically restart it, demonstrating the Auto Restart function.
00:05:12.840
Using Windows, you can enable the Auto Restart feature the same way as you would with Unicorn. After executing the code, you will see it under supervision, and after killing this process, it will be restarted automatically.
00:05:39.560
This is the ease of using ServerEngine; it's quite similar to Unicorn. If you've tried using Unicorn, you should find ServerEngine easy to navigate.
00:06:02.560
First, you'll write the server module and the worker module in the submodule. This is where you define the functionality before launching the worker or after launching it.
00:06:14.960
For instance, if you want to pass a TCP socket to the worker, you'll need to create the socket here. Then, in the worker module, you should define the process in methods like run or stop. For example, you can write the process that manages the accepted socket in the run function.
00:06:39.440
After defining the necessary code, you need to write the configuration for ServerEngine. This includes defining whether to create a daemon or not, specifying log file paths, and setting the worker type and number.
00:06:49.080
Once you've finished writing your code and configuration, running it is a straightforward process. This allows you to learn how to manage robust multiprocess workers with ease.
00:07:07.880
When choosing the worker type, you can select from three options: thread, process, or spawn. If you want to use threads as the worker type, specify 'thread' in the ServerEngine config. For using processes, write 'process,' and for spawn, simply write 'spawn'.
00:07:20.520
The SP (spawn) type is typically used in Fluentd. In Fluentd, you need to use a multiprocess plugin. This entails writing separate commands for each worker.
00:07:32.880
If you want to listen socket for each worker, you would need different port numbers. However, with ServerEngine, you can share one socket among each worker from the parent process.
00:07:44.240
This approach allows for a more efficient handling of TCP requests without the hassle of managing different socket assignments.
00:08:01.600
ServerEngine is often referred to as a prefork server. This differs from traditional prefork servers like Unicorn or NGINX, where the server only shares a socket when it forks. In these cases, the server knows which parts need to be opened beforehand.
00:08:16.640
In contrast with ServerEngine, it's assumed that processes won't know the port in advance. If the worker is given the port information in the configuration file, the worker itself will manage the socket connection.
00:08:30.240
ServerEngine's model requires the worker to send a request for connection first, ensuring a unique connection flow compared to traditional servers.
00:08:44.720
Now, let's discuss how to create a multiprocess server for Windows using Ruby step by step. I'll introduce essential Ruby functions and provide tips for developing on Windows.
00:08:55.680
In Unix, there is a fork function that is typically used to create a worker process. However, Windows lacks this function, so I am utilizing the spawn function, which is widely known.
00:09:07.680
The spawn function executes a specified command for a new process and allows you to obtain information about that process.
00:09:22.799
In a typical scenario, ServerEngine would manage the work by passing command parameters. In the application code, utilize the method to execute based on server configurations.
00:09:35.360
For handling socket requests from a worker in Unix, sharing the file descriptor is simple. However, in Windows, the file descriptor is treated differently.
00:09:48.560
Each process in Windows has independent file descriptors. As such, sharing a socket between parent and child processes requires using specific Windows API methods.
00:10:09.560
To send a socket in Windows, utilize the Windows API for socket management. This involves duplicating the socket and attaching it to the intended worker process.
00:10:20.639
The challenge with Windows API is that it's typically more compatible with C programming than with Ruby. Thus, to handle API calls from Ruby, use either C extensions or Foreign Function Interfaces (FFI).
00:10:34.799
Using FFI allows you to call C functions directly from Ruby without needing a specific C extension.
00:10:45.480
To achieve this with the FFI in Ruby, you will need to define struct types and proceed to attach necessary functions for socket duplication.
00:10:58.320
While using FFI is a viable solution, it does introduce additional gem dependencies. Hence, I have sought alternative methods to minimize this dependency.
00:11:09.440
Another solution is to use the built-in method called 'FFI,' which allows you to call shared libraries without the necessity for external gems.
00:11:21.680
After defining external function calls, you still need to structure the information you want to process.
00:11:31.520
In order to duplicate the socket and get the desired protocol information, you'll do the necessary conversions from binary to struct.
00:11:43.760
After passing the protocol information, you'd then create a socket from this information using designated function calls.
00:11:58.240
With the handle created, you can manage TCP communications using methods tailored for socket handling.
00:12:10.080
As I mentioned, Ruby does not directly support native TCP server functionalities through its standard libraries.
00:12:22.560
Therefore, you would need to rely on either FFI or the aforementioned function to handle socket connections.
00:12:33.760
Once the TCP connection is established, the server can send and receive requests efficiently, utilizing the direct communication capabilities provided by the Windows API.
00:12:43.440
In previous scenarios, I utilized DRb (Distributed Ruby) for socket communications since there are no Unix domain sockets in Windows.
00:12:54.960
With DRb, the server can create sockets and relay them back to workers. However, there are race condition risks where workers could incorrectly access each other's sockets.
00:13:05.760
I refined the model to use TCP servers that create connections based on worker requests. Each worker will receive a socket corresponding to its request.
00:13:18.960
Employing TCP in place of Unix domain sockets significantly enhances the interaction between the server and workers.
00:13:30.320
However, you need to be mindful of the port distribution to avoid conflicts, which may require implementing a more sophisticated way of handling available ports.
00:13:42.320
Another challenge involves managing HTTP requests efficiently. In situations where there are blocking calls, you need to handle requests without using non-blocking reads due to Windows limitations.
00:14:00.720
You can use read-polling methods as an alternative, which waits until data is available instead of raising exceptions when no data is present.
00:14:17.440
It's crucial to adapt your reads based on the specific expectations of the data flow to optimize performance.
00:14:35.840
Now, consider if you're unsure whether your implementation requires additional optimizations, especially in handling connection headers for Windows.
00:14:54.560
I discovered through benchmarking that handling request headers in Windows doesn't lead to significant overhead, unlike in Unix.
00:15:08.840
Even so, I implemented an accept-mutex to manage workers evenly as they share the load of incoming requests.
00:15:23.760
This is my current implementation of the accept-mutex, which allows workers to process connections sequentially.
00:15:39.360
This approach is not perfect, but it presents a workable solution that can be improved further using the I/O Completion Ports (IOCP) available in the Windows API.
00:16:02.240
To take advantage of IOCP, you must first create a completion port and attach working threads to manage socket communications effectively.
00:16:18.960
When a worker accepts a connection, it can retrieve the completion status and handle requests accordingly.
00:16:31.840
While using IOCP may require a learning curve, it's beneficial for implementing synchronous I/O on Windows.
00:16:42.880
To use IOCP, you have a couple of options: create a centralized completion port that all servers and workers use or have separate completion ports for each worker.
00:16:59.120
Here's a demonstration of listening with a multiprocess approach using Fluentd again.
00:17:10.240
After execution, you can see multiple worker processes under supervision, demonstrating efficient management.
00:17:23.040
Sending requests will yield different outputs based on the worker processing them, showcasing effective routing and handling.
00:17:36.400
Benchmark results illustrate that with multiprocess architecture, performance can improve significantly, showcasing the viability of this approach.
00:17:48.160
The results showed about a twofold performance increase, which is a clear demonstration of efficiency with multiprocess design.
00:18:02.720
While it's natural to expect performance improvements, I still see opportunities for enhancements and optimization.
00:18:15.840
To summarize, developing for Windows requires careful consideration of Windows-specific APIs and how they interact with Ruby's capabilities.
00:18:30.560
Ruby offers powerful and niche functions for dealing with cross-platform differences, making it an excellent choice for development.
00:18:42.440
Thank you for listening!