00:00:00.000
Konbanwa! We made it—it’s the last talk of the day, and we can do this. My name is Thomas Enebo, and I'm from the United States. I live in Minnesota, about as far away from the ocean as one could be.
00:00:12.330
I co-lead the JRuby project and have been working at Red Hat for the last four years. JRuby has been my full-time job, and I’ve actually been working on JRuby full-time for ten years, including my time at Sun Microsystems and Engine Yard.
00:00:30.269
It feels like I just learned Ruby yesterday. I still remember getting Dave Thomas's Pickaxe book and really getting into it. I've been using Java for over 20 years, but it feels like 60 years. That's a joke, of course! If anyone knows of any good craft beer places in Kyoto or Tokyo, please let me know.
00:00:51.559
This is not me, but I love it when people walk up and say I don’t look much like my profile picture. For those who might not know what JRuby is, I had to throw this slide in: JRuby is a Ruby implementation that runs on the Java platform.
00:01:17.520
We have two major versions: JRuby 1.7, which supports both Ruby 1.8 and Ruby 1.9 modes. You can enable this by passing a command-line option, but it will only be supported until the end of the year. The version I’ll discuss today is JRuby 9000, which tracks the latest version of CRuby, although it is currently at 2.3.1.
00:01:43.979
JRuby is distributed under three different open-source licenses; you can pick which one to distribute JRuby under. Most people tend to choose the Eclipse Public License, as it is the most permissive. I'm not going to talk about this today, but JRuby interacts very well with the Java ecosystem, making it easy to call Java types from Ruby syntax.
00:02:31.120
You can pull in a Java library and interact with it, and you can also communicate with other JVM languages. Additionally, we offer native threads, providing a bunch of bonus features on top of being just Ruby implementation.
00:03:02.849
Today, I’ll share about JRuby 9000. This talk is a retrospective covering the good things that happened as well as the challenges we faced. The key points about JRuby 9000 include our plan to follow the latest CRuby releases. We also wanted to clean up some APIs.
00:03:29.019
It had been about seven years since our last major release, and we decided to bypass Java's IO APIs completely and just call into C for better compatibility. We also completely changed our runtime since 1.7.
00:04:13.870
Following the latest Ruby has been great, and I'll show you an example. Here’s some example Java code, and in JRuby 1.7, I'm showing the implementation of the spaceship operator and Ruby string. You can see the JRuby method annotation at the top that binds Ruby methods to the Java implementation.
00:04:56.269
There are two implementations: one for Ruby 1.8 and one for Ruby 1.9, both virtually identical. The semantic differences between versions are typically small. However, on rare occasions, we accidentally used the wrong version of a method, leading to tangled results, especially when using multibyte characters.
00:05:43.690
In JRuby 9000, we managed to remove a significant amount of Java code—about 10%—because we are no longer supporting multiple versions.
00:05:57.100
We also eliminated half of our Ruby code, which simplifies the codebase. However, breaking the APIs did not yield the results we expected. Initially, we removed methods that had '19' on the end, assuming it would create a cleaner API.
00:06:17.490
Some users of Java Native Extensions pointed out that removing those methods posed problems. These extensions are similar to C extensions in CRuby but are intended for Java interop. Many developers wanted to ensure compatibility with both JRuby 1.7 and JRuby 9000, so we ended up adding back those methods.
00:07:07.870
Now, we have a single implementation but two entry points to it. Looking forward, there’s an unexpected joke about JRuby 50,000.
00:07:22.889
It started as a humorous reference and evolved into a release plan. We will expand our embedding API, allowing for methods that enable the construction of core types like a new string.
00:07:49.389
These methods will be statically portable. We’ll also introduce a tool for linting code, helping users determine whether they are utilizing only endorsed APIs or whether changes are necessary. Furthermore, documentation will be provided to guide users on compatible usages.
00:09:14.440
We recognize that we need to prepare at least a year in advance to ensure that users can update all their native extensions for JRuby 9000. This proactive approach will benefit the transition to JRuby 50,000.
00:10:08.259
In our development process, we decided to bypass Java I/O for compatibility reasons. This approach has led us to develop a good enough performance level that we haven't even bothered tuning it yet.
00:10:48.660
There was a performance issue raised recently, and upon investigation, we realized we were performing some unnecessary copies.
00:11:60.580
However, we've made significant gains in this area.
00:12:00.100
Currently, Windows users may experience some limitations as we haven't ported C code for Windows yet. Instead, they will fall back onto pure Java mode.
00:12:55.130
We do still support pure Java mode for restricted environments, like Google App Engine, where you can’t call out to C code.
00:13:36.150
As we run on Windows, we revert to the pure Java code path, which indicates that it's an area we need to work on.
00:13:58.880
We also hope to make our pure Java mode more compatible with CRuby over time; this aspect is dependent on Java's release schedule.
00:14:29.930
Our new runtime, called IR, stands for Internal Representation. It's a complete replacement of our runtime from JRuby 1.7.
00:15:23.450
We wanted a traditional compiler architecture that anyone familiar with compiler courses would recognize—terms like control flow graph or basic block.
00:15:56.000
In previous JRuby versions, we would parse Ruby to generate an abstract syntax tree and then use an interpreter to process it. Now in JRuby 9000, we generate virtual machine instructions representing Ruby semantics.
00:16:39.680
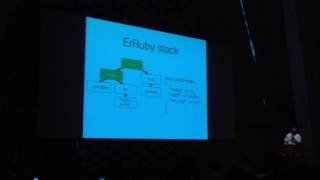
I've found this much more readable than our previous approach. Here’s an example of our instructions displayed in a tool called Ideal Graph Visualizer. The center shows a branch-not-equals instruction, and we see the control flow graph on the right.
00:17:36.830
The cool part is that after running a compiler pass, we can visualize how the instructions change, which helps us to understand the effects of optimizations better.
00:18:29.580
Software became famous with the term 'write once, run anywhere', and I want to make JRuby renowned for the phrase 'fix once, run anywhere.' In JRuby 17, if there was a bug with Ruby semantics, we had to fix it in two places: our interpreter and the IR.
00:19:39.070
In JRuby 9000, we essentially have to fix instructions rather than making multiple corrections in the interpreter and JIT.
00:20:34.220
This streamlining simplifies things. For instance, when we added a Ruby 2.3 feature, the frozen string literal pragma, we only needed to modify the IR to support it.
00:21:39.610
We optimized it with a quick change that checks if the node is frozen, creating a frozen string operand instead of just a string.
00:22:00.560
Now let’s talk about optimizing once, running anywhere. Any compiler passes or improvements we make benefit both the interpreter and the JIT.
00:22:43.090
In the past, optimizations did not effectively aid the interpreter since we would generate low Java bytecode. But now with the IR, we focus on the instructions we emit and that has improved debugging.
00:23:58.610
If we encounter issues, it's often easy to resolve by running JRuby in a pure interpreted mode while utilizing debugging tools.
00:24:20.330
Now, for a little joke: startup times in JRuby remain an area of concern, and we recognize that we have not resolved this completely.
00:25:02.160
In JRuby 17, we parsed Ruby source code to generate an abstract syntax tree, but JRuby 9000 adds a layer of instructions which results in more pre-execution processing.
00:25:49.500
We're hoping to optimize this further. We created a special interpreter that knows to navigate these instructions without further analysis.
00:26:49.080
Unfortunately, this ends up adding a 5-10% penalty, which we anticipated. We'd been exploring ways to address the slower startup, including the idea of reading and parsing Ruby source code into a stored intermediate representation.
00:27:39.930
The idea was that if the source code already existed, we could bypass parsing and build steps entirely.
00:28:46.560
However, results were not as favorable as hoped. Testing with a sample Rails application showed only a marginal improvement. While it may reduce some overhead, it didn’t yield substantial gains.
00:29:26.880
Moreover, the issue arises during development time when many associated methods are not executed immediately, which causes delays.
00:30:32.110
If our intermediate representations were more fixed-width, the execution could be executed directly. Our architect suggested implementing binary interpretation, which we might explore in the future.
00:31:19.840
We've also been able to compile Ruby to Java class files with ahead-of-time compilation. However, method size limitations have previously caused failures with large Ruby methods.
00:32:25.070
In JRuby 9000, we resolve this by only dumping persisted data into 32K chunks.
00:32:36.990
This way, we can load the interpreter efficiently and allow methods to be JIT-compiled if they are 'hot' enough.
00:33:12.300
We don't want to compile everything since it doesn't necessarily speed things up.
00:33:33.970
Regarding interpreter performance, we’ve noticed it running a bit slower in JRuby 9000. There’s a specific case where executing a source file doesn’t lead to enough JIT opportunities.
00:34:14.460
Despite initial assumptions, many applications utilize their libraries, which allows the JIT to activate; therefore, the performance impact is less severe.
00:34:58.710
We have one user where the slightly slower interpreter becomes a significant challenge, primarily due to the additional work we require to emulate a machine.
00:35:51.910
Since we're managing registers and advancing program counters, there’s overhead associated with the accesses.
00:36:35.620
Additionally, we initially designed everything to be mutable in the IR, thinking it would yield better performance by avoiding copies.
00:37:38.470
However, we’ve learned that this ineffective when modifications occur during execution. Hence, we’re gradually shifting towards immutability, which allows for better memory optimization.
00:38:50.141
Overall, my experience working with the IR has been overwhelmingly positive; it's simpler and faster to work on than previous iterations.
00:39:43.350
Adding new features is easier, and we’re streamlining our processes. Although interpreter performance may lag slightly, the benefits from JIT optimization are helping to counterbalance that.
00:40:31.410
Lastly, we're actively working on improving startup time. We've had discussions with Oracle regarding a product intended to improve Java applications, which has shown promising results with previous tests.
00:41:25.380
We are aware of startup speed being a major challenge, and we won't overlook it as we continue to refine JRuby. Thank you for your time!
00:42:18.510
If there are any questions, feel free to ask! I appreciate your interest.
00:43:27.780
I’m curious about the executable compiler you mentioned; could you elaborate on that?
00:44:37.010
The executable compiler product isn't open or public yet. They've recognized JRuby's startup time issues and understand we are a valid use case for improvements.
00:46:03.150
We are looking forward to our collaboration with them to see what improvements we can achieve as part of our project.
00:46:57.160
Any further questions? If not, thank you again! It's been a pleasure discussing JRuby with you.