00:00:00.900
Hello everyone! I'm excited to be here. The last time I was at RailsConf was in Phoenix in 2017. At that time, I was an editor for the newsletter called ‘This Week in Rails,’ which is still happening. If you are not a subscriber and you're interested, there are weekly updates about Ruby on Rails.
00:00:12.240
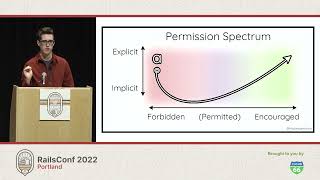
It's great that we are all able to get together in person again. The objectives of this talk are to review five types of database scaling challenges and solutions. Hopefully, you'll consider integrating the tools and techniques I'll present into your applications. So, I hope there's something new here for everyone.
00:00:24.300
The topics we’ll cover are: safe migrations on large, busy databases; maximizing performance of database connections; maintaining fast SQL queries; high-impact database maintenance; and implementing replication and partitioning. I work for Fountain, which is a high-volume hiring platform, and we're here at RailsConf as a sponsor. I encourage you to come check out our booth; a bunch of other Fountain engineers are up here at the front. Thank you all for coming!
00:01:01.020
We're a remote-first company, and you can check out our openings on fountain.com/careers. A little bit about me: I'm a Staff Software Engineer at Fountain. I mostly work with Rails, Postgres, and Elasticsearch. I'm also a dad of two young kids, so we talk about Paw Patrol a lot in my house. For those who are parents, you probably understand where I'm coming from. For those who don’t have kids, you might be wondering what I'm talking about.
00:01:23.940
Paw Patrol has been around for a long time in cartoon form, and last fall they released a feature-length movie titled ‘The Movie.’ I saw it with my daughters, and it was a lot of fun! When I had the opportunity to do this presentation, I thought it would be fun to have a theme and a story with some characters, so I looked around my house for inspiration.
00:02:23.100
However, rescues are down, so the Paw Patrol has more time on their hands and they've pivoted into startups. They built an app called “Pup Tracker” that tracks the pups' geolocation primarily to keep them safe. They've scaled their app, which of course was built with Ruby on Rails and Postgres, and it’s now used around the world. But as you might guess, they ran into scaling challenges.
00:02:54.840
Today, we’re going to learn about five pups and hear about their challenges and solutions. The pups are Liberty, Marshall, Chase, Rubble, and Skye. We'll start with Liberty, who is the newest Paw Patrol member and is eager to make an impact. She has a lot of experience with product development and has written many database migrations.
00:03:02.340
Liberty will discuss migrations on large busy tables. As these tables grew to millions of rows, making structural changes could take a long time and cause application errors. For example, introducing a check constraint—it’s similar to Rails Active Record model validations but done in the database—can block reads and writes, significantly impacting performance.
00:03:47.880
If we add a check constraint on the pups' table concerning birth dates to ensure that they are newer than 1990, the database will check all rows in this table. If there are hundreds of millions of rows, it will take a long time. This is why we want to avoid blocking reads and writes, which could lead to application errors.
00:04:10.920
To avoid issues when adding check constraints, we can use the ‘validate: false’ option, which means that while the constraint will be in place for new rows being inserted or updated, the existing rows won’t be checked right away. We can then create another migration to validate the existing rows later, which minimizes disruption during the process.
00:04:56.880
This validation phase causes less disruption compared to adding the constraint outright. For large tables with many rows of geolocation data, it's critical to ensure that changes do not block your application.
00:05:02.820
For adding columns, an exclusive lock is needed briefly. When we update thousands or millions of rows in a transaction, this lock could lead to downtime for applications accessing that data. Again, the strong migrations gem can be very helpful as it identifies potentially unsafe migrations and provides safe variations.
00:05:53.940
For a better strategy, create one migration to add a nullable column and then use a second migration with multiple batches to update existing rows. By using sleep to throttle the updates and running it outside of a transaction, you can avoid significant disruptions to your application. This strategy allows for smoother transitions during maintenance.
00:06:43.980
To summarize, Liberty has stressed the importance of using strong migrations to separate new row modifications from existing ones. It’s crucial to identify potentially unsafe migrations and utilize the guidance of strong migrations to avoid application errors. With that, I’ll pass this on to Marshall.
00:07:24.420
Marshall is the fire pup, responsible for extinguishing literal fires and database fires. He learned about database connections, which are a limited resource, and how they are used whenever an application or background workers interact with the database server.
00:07:49.920
In the Pup Tracker app, connections are managed by Puma and Sidekiq workers. We have ActiveRecord connection pooling that lets us set limits, ensuring we do not exhaust available database connections. Understanding how many workers we have and how they interact with the database is crucial for optimal performance.
00:08:17.520
For instance, if we have four application server processes, each connecting to the database and two background worker processes doing the same, we can calculate the available connections based on our connection pool configuration. Overall, it’s important to efficiently use connections to manage resource consumption effectively.
00:08:56.220
Marshall identifies the importance of scaling the database server either vertically by increasing instance class or by using available connections more efficiently. One solution he found useful is using a connection pooler, which operates alongside ActiveRecord connection pooling and efficiently manages connections.
00:09:39.060
Connection poolers eliminate the overhead of establishing new connections. After implementing a connection pooler like PG Bouncer for the Pup Tracker application, Marshall found that it provided performance improvements without needing to scale the database server vertically.
00:10:06.060
Moving on to Chase, he is another emergency responder who specializes in investigating slow queries. Let’s say we run a simple query like 'select * from locations where id equals one.' We may need to analyze its performance, which brings us to understanding query execution plans.
00:10:33.060
When examining query plans, we look to tools like ‘EXPLAIN’ in SQL to understand how Postgres is executing the query. Analyzing details can reveal how long a query takes to run and how it's structured, which can point out inefficiencies in our database design.
00:11:16.300
Imagine having a locations table with 10 million rows that lacks a primary key or an index. Notably, performing queries without an index can lead to significant slowdowns. Chase emphasizes the importance of adding indexes to improve query performance.
00:12:01.260
For example, once an index is established on the primary key, query performance can dramatically improve. Chase explores using extensions like PG Stat Statements, which helps gather statistics on query performance, enabling developers to focus on optimizing the highest resource-consuming queries.
00:12:49.560
PG Stat Statements normalizes queries, allowing for better visibility into performance metrics across different variations of a similar query. It helps teams identify which queries are causing the most stress on the database and allows for targeted optimization efforts.
00:13:23.520
Likewise, Chase finds tools like PG Hero to be helpful as they provide a performance dashboard that visualizes data collected from PG Stat Statements. Such tools show slow queries, unused indexes, high connection usage, and other performance-related metrics to assist in improving overall database performance.
00:14:00.780
Chase’s strategy involves getting the query plan, identifying the necessary changes, and sometimes rewriting queries to reduce complexity or improve selectivity. He also ensures that the analytics for the respective tables are kept up to date, which is critical for optimizer performance.
00:14:56.220
To support query performance, Chase continuously monitors the state of statistics collection and can add missing indexes when detecting inefficient scans. He understands that sometimes focusing on the actual database table statistics and correcting them can yield better results than merely optimizing the query plans.
00:15:32.940
Next, Rubble will discuss database maintenance. Activities include vacuuming, analyzing, and rebuilding bloated indexes. Maintenance is crucial as it keeps the database optimized and efficient. Auto vacuuming is a built-in mechanism in Postgres, but it is generally conservative.
00:16:35.220
As workloads increase, Rubble highlights the importance of potentially increasing resources for Auto vacuum to help it run more aggressively without affecting application performance. Additionally, he covers the topic of idle indexes and how they can negatively impact performance and resource usage.
00:17:10.620
The Postgres system catalogs track index usage, allowing teams to identify and remove indexes that are never used in query plans. This active management keeps the database performance-centric and can lead to significant resource savings.
00:17:58.140
Rubble leverages the 'REINDEX' command for bloated indexes, particularly in newer versions of Postgres, where this operation can be conducted concurrently, thereby minimizing downtime. He discusses setting up automated maintenance tasks through the PG Cron extension, providing timely updates without manual intervention.
00:18:37.080
Now, Skye steps in to address replication and partitioning. She underscores the importance of analyze and retention strategies in database management. Partitioning becomes critical when dealing with high-volume tables, and she highlights practical approaches for creating partitions to manage data effectively.
00:19:59.100
For example, Skye points out how most applications review the most recent data, making it sensible to use range partitioning based on created-at timestamps. This way, underutilized data can be detached or removed, helping to reduce resource loads and increase query performance.
00:21:03.720
She also notes the various types of partitioning available in Postgres and defines the benefits, such as faster maintenance and reduced application downtimes. However, there are challenges in implementing partitioning; it requires careful planning and understanding of data access patterns.
00:22:57.720
The KPIs established should hinge on query speed and resource consumption when deciding on partitioning strategies. Additionally, there is an operational component where partitions need to be created prior to writing to them. Skye emphasizes using tools like PG Slice to manage the transition to partitioned tables.
00:24:04.780
In conclusion, every pup has their lessons from scaling applications using PostgreSQL. Liberty reinforced the need for safe migrations, while Marshall highlighted the importance of connection pooling. Chase focused on optimizing slow queries, Rubble brought attention to essential maintenance practices, and Skye closed with the value of replication and partitioning.
00:25:43.920
In summary, utilize safe migrations, manage connection resources effectively, analyze and improve query performance, perform regular maintenance, and implement replication and partitioning solutions to ensure an efficient database environment.
00:26:05.700
I'd like to extend a special thank you to everyone who helped with the reviews for this talk. I appreciate your insights that helped focus the content down. Thank you all for attending! I'll be tweeting this out along with a brief summary of everything I discussed.
00:26:38.620
Now, I’d like to open the floor for any questions, particularly regarding Paw Patrol characters or the topics we covered. A question was asked about best practices for backfilling data during migrations. Yes, it's common to use scripts or rake tasks for large backfills outside of regular migrations to avoid locking issues.
00:28:06.780
Someone inquired about a heuristic for when to adopt partitioning. Well, although the docs hint towards partitioning for tables at scale, practical implementation is best assessed on a case-by-case basis. In many organizations, partitioning comes into play at various sizes, particularly for high write tables.
00:29:12.060
It's beneficial to monitor the largest tables and operations as they are the most likely candidates for the efficiencies gained through partitioning. However, not every table will benefit from it, so it's about striking that balance.
00:29:39.000
Thank you all for your insights and attention today. I hope you found this talk helpful!