00:00:00.900
I'm glad to be here in person! This is actually my first live conference talk. I did a pre-recorded one last year, and while that was useful, it's not quite the same. I'm really excited for the opportunity to be here with all of you in an actual room.
00:00:14.839
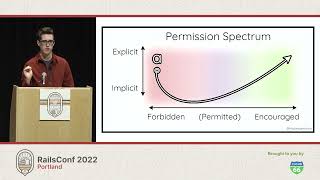
You might be here because you saw the title of this talk, "RAILS_ENV=demo," and something about it intrigued you. Or maybe you just picked a room at random! Either way, let’s unpack this title.
00:00:18.480
What this title refers to is the environment variable used to control the mode that your Rails app boots up in. By default, this is actually going to be development or test if you're running your tests. If you're deploying to production, hopefully you're using the production environment. Some companies actually have a staging environment, but that's not one of the built-ins. So what you get out of the box are the big three: development, production, and test.
00:00:48.420
These environments correspond to config files, which have actual config content in them that makes that environment unique. I mean, I’m talking to a room full of Rails engineers, but I want to ensure that we're all on the same page. Today, I’ll be discussing the idea of adding a new dedicated environment called "demo" for giving application demos.
00:01:06.360
This is the ability to step up in front of an audience and show off a live version of your product reliably, repeatedly, and consistently. The last thing you want is to get up there and have something go horribly wrong. So, think of this a little bit like a showroom floor model of your application or perhaps like the Walmart GameCube kiosk version of your app, but without the horrible neck strain.
00:01:45.180
And I wish I could say that it were as simple as just adding a new demo.rb file to your app, but that’s just the tip of the iceberg. Demo ability—the ability to quickly take something you’ve been building and show it off to the world—is about so much more than just how you boot up your application.
00:02:09.180
This is something my team and I have been thinking about and iterating on for nearly six years, exploring this iceberg of demo ability. So, who am I? Let me introduce myself. My name is Nathan. You can find me online in a few places, and I also exist in real life. I work at a company called Betterment. You might have heard of us; we offer financial advice, investing accounts, retirement, you name it.
00:02:28.920
I like to say that our top product is financial peace of mind, and I should mention that we’re hiring. I work on the application platform team at Betterment. We focus on a lot of cross-cutting concerns and provide our product teams with more day-to-day peace of mind.
00:02:55.140
But I haven’t always worked on this team. The story I want to tell starts in 2016 when I first joined Betterment. Back then, I was on a different team helping build Betterment's 401K offering, which is now part of Betterment at Work.
00:03:10.200
While most people think of Betterment as a B2C business—financial services for everyday people—the thing my team was building was actually a B2B product. Our customers were companies that wanted to offer 401K plans to their employees, who would then experience Betterment’s consumer product.
00:03:43.380
And look, I'm not on the business side of things; I'm just a software engineer. But if there's one thing I know about B2B businesses, it’s that they do a lot of product demos. We found ourselves needing to showcase Betterment's consumer product to all our new and prospective business clients.
00:03:58.380
So, how did we do that? Firstly, there's always the option to just use the production app. In our case, it’s a cluster of multiple relatively monolithic applications—not microservices, but also not one big Rails app.
00:04:11.160
However, since our app involves real money and real personal information, this didn’t feel right. So, we looked around and saw that Betterment also had a staging environment, which was deployed in the same overall configuration as production, except that the database was reset and repopulated nightly with some magical sanitized staging data.
00:04:32.040
We said, "Okay, what if we do something like that?" If this sounds a bit like the drawing owl step one, step two, you’re right, because that’s exactly what this was. You see, if what you need is a drawing of an owl, but somebody else is already drawing owls for you, then you don’t need to learn how to draw the owl.
00:04:54.840
The staging environment was our owl. Of course, we made a couple of modifications—like we didn’t need all that sanitized staging data. So, we added another process to just sort of populate the database with some demo accounts. As for the rest, we just copy-pasted the deployment scripts, the environment files, everything that made staging staging, and we deployed it.
00:05:27.060
And it worked—or so we thought. Fast forward a bit to 2017, and we were still working hard on our roadmap, but we sensed that the demo environment wasn’t reliable.
00:05:34.320
In fact, we were repeatedly told in no uncertain terms that the demo environment was often breaking for all kinds of reasons. Eventually, getting it working became too much, and we effectively gave up, which felt bad.
00:05:59.160
By 2018, we knew we had truly failed. Teams had found other ways to give product demos, and I saved this screenshot of our build history. It’s really old; we don’t use Jenkins anymore. If you look closely, it shows an entire year’s worth of broken builds, each one the result of a developer banging their head against their keyboard, trying to get this thing working.
00:06:12.600
Thinking back to that iceberg of demo ability, we had already made a big observation right beneath the surface: deploying a demo environment is not the same as maintaining one.
00:06:39.600
By 2019, the business needs had caught up with us again, and we needed our demo to succeed. However, we also finally had time in our roadmap, so this time we aimed to build something easier to maintain in the long run.
00:06:54.780
We started by writing down a list of things that the original demo environment had consisted of. First, what got deployed? Everything—all of our apps. Secondly, the database was populated up front with those demo accounts. I would call that seed or fixture data.
00:07:14.400
Then, to keep that data fresh, the entire database was reset with every deployment, so it relied on these short-lived databases. At first, we deployed this only on Sundays, but that got painful, leading us to switch to monthly deploys until we just started deploying only when needed, which I’d call "push button" but more accurately "push button and cross fingers".
00:07:39.180
Lastly, who owned it? We did—the engineering team closest to the need for its existence and most incentivized to do the work. Once we had this list, we began crossing things out, starting with this idea of deploying an entire cluster of services.
00:08:02.700
From a maintainability standpoint, why keep a bunch of apps running if what we really cared about was one app— the specific thing that we wanted to demo? At Betterment, we already have a way of running our Rails apps in isolation from one another, as we do on our local development laptops.
00:08:24.600
When we develop apps locally, we use a tool called WebValve. WebValve lets us define fake versions of all our collaborating services and automatically routes all web traffic to those fakes. It’s built on top of WebMock and Sinatra, if you’re familiar with those Ruby gems.
00:08:47.760
So, instead of running an entire cluster of applications locally and connecting to external sandbox APIs, we have these fakes that run inside the Ruby process itself. Therefore, it’s all one Rails app. These fake apps are quite simple; they don’t have to do everything a real app would. They just need to respond with some fake data so that your app doesn’t break.
00:09:13.619
Now there's a whole other talk on WebValve itself, and our VP of architecture, Sam, does a great job summarizing how it can be useful for local development and testing, so I won’t cover that here. If you're interested, you can find it on GitHub. What I will cover is how we got all of this working in our local demo environment.
00:09:43.140
First, it allowed us to deploy just a single app, basically for free, because it relied on all the fake services that our teams had already written in local development. Right off the bat, this was great! But remember, we were stubbing out all those collaborating services, which meant all outside HTTP requests.
00:10:19.920
I showed this to one of my colleagues who frequently gave client demos. He liked what he saw, but then he encountered a page supposed to show a graph of performance history for an account. He said, "Hold on! I can’t show this to clients!" I explained that we didn’t have any performance history because this was just a demo app and that the history comes from another backend service.
00:10:53.160
He replied, "It doesn’t matter. If a client has to ask why something looks broken, then the demo is already off track." After that meeting, I felt bummed because he was right, and I knew I was making excuses for technical shortcomings.
00:11:27.780
So, I wondered if this whole WebValve approach was the right idea. However, after thinking it over, I realized most of the application worked as intended. It was just some of these external service boundaries that didn’t make for a good demo.
00:11:56.640
I thought: Why not make the fake service a little more fake? By that, I mean why not write a fake stock market simulation with buys, sells, market changes, dividends, and fees? Of course, none of this is real, and you shouldn’t use it for anything significant. Still, it resulted in a graph that demonstrated activity.
00:12:26.940
Is this real? No, absolutely not. But is it demoable? Maybe! I went back to my colleague, and he said, "Sure, it looks great." At that point, I decided we could probably run with this, and so we did.
00:12:42.480
There were one or two other places we had to fill in the gaps, but one more significant issue remained. These fake services had no ability to remember anything. If you performed an action like making a deposit, the next time you fetched your balance through an external GET request, it showed your previous balance, breaking immersion.
00:13:10.680
This is where we came up with the idea of stateful fakes. A stateful fake is a WebValve fake that can remember things. It gets its database tables and ActiveRecord models, allowing it to read from those tables during GET requests and update those tables during POST requests.
00:13:32.579
Now it can remember things! You could deposit $123 into an account and see it reflected in the balance of that account. We could showcase our application in total isolation from any other apps and services.
00:14:01.680
Instead of deploying multiple apps, we had one app with stateful fakes. We also made our second observation in the iceberg of demo ability: an app should mostly work in isolation. It might need some adjustments at the system boundaries, but if we want an app to be easily demoable, it should mostly make sense on its own.
00:14:31.620
Fortunately, ours did. Next, we focused on how we populate the demo data and accounts, and we crossed that out too. Then we realized if we weren't using seeds or fixture data—meaning we weren’t populating user accounts ahead of time—then what do we do?
00:14:51.840
You'd be faced with a login form and need to enter something, right? The more we thought about this, the more awkward it became for our client-facing teams. Did they just keep a sticky note with demo logins? How did they know someone else wasn’t already using one of these accounts?
00:15:31.320
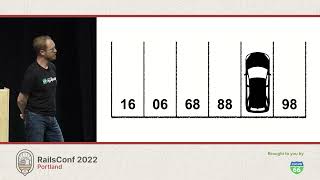
If it was so awkward, why were we using the login form at all? That was our ‘aha’ moment. We sketched out a different approach: a page where you see three user accounts, each with a sign-in button. When you click sign-in, instead of logging in as a specific user account, it spins up a background process to generate a new user for you on the fly.
00:15:51.960
So, you get a brief loading spinner, but then you’re dropped straight into a totally fresh dashboard. This felt way less awkward than the login page with sticky notes. We just needed to figure out how to dynamically create user accounts on the fly.
00:16:32.040
When looking at our local development environment, we found we already did this in our tests. We use a tool called FactoryBot by our friends at ThoughtBot, which allows you to define factories like a user factory to generate users as needed.
00:16:56.760
This was great! We could easily link this to our sign-in button. Moreover, we could define traits, such as a user with a Roth 401K account, applying those traits at creation. Each user type could get its own factory definition, and by changing traits, we could modify the actual dashboard into which users would be dropped.
00:17:21.060
To support this idea, we created a quick domain-specific language (DSL) for defining these, calling them personas. All you had to do was drop your factory code into that DSL, and it would take care of the rest.
00:17:43.920
We built this Persona Picker UI and made it replace the login page entirely. It worked! There’s the loading spinner, which takes you straight to the dashboard. Bingo!
00:18:06.840
However, there was a hiccup. After a while, we redeployed something, and suddenly it broke. We were getting flashbacks. Upon digging deeper, we saw that after the initial deployment, we could generate user one, user two, user three, and so on, but upon redeployment, the next user reset to user one.
00:18:27.960
This resulted in uniqueness constraints in our database being violated. For instance, the email of user one among others was already taken. The way that we defined factories relied on a 'sequence' feature to generate unique sequences for unique data.
00:18:51.240
The issue was again due to a lack of memory, no long-term memory, since the sequences reset every time the Ruby process or server restarts. Apologies to our friends at ThoughtBot, but we decided to patch FactoryBot so it could check the database to find the next sequence value.
00:19:16.560
First, we were like, okay, let’s find the maximum value in the table, selecting the max of the column name and adding one. This works for integer columns or strings in standard lexicographic order, but it can be flawed, especially with descending sequences or encrypted attributes.
00:19:39.600
We went with the best-worst option: an exponential search to find the next gap in the sequence. It was slower than ideal but not unbearably so since we only needed to find it once. After finding the starting value, the sequence could keep going from there.
00:20:13.020
We called it CleverSequence as a reminder that clever code isn’t necessarily good code, but it helped us reach a demoable state, and that’s what truly mattered.
00:20:37.440
Now it worked! We could actually use it in real product demos. This led to our next iceberg reveal: we realized we needed to start with user experience and work backward from there.
00:20:55.560
The initial demo environment was built on the faulty assumption that the login page was the right user experience. By rethinking that assumption, we did away with seeds and fixtures in favor of the new personas framework, powered by factories.
00:21:19.560
We could have stopped there; we had the whole thing working end-to-end. However, we weren’t done crossing things off our list, so we looked at the temporary database concept.
00:21:34.920
This one was easy to cross off since that process destroyed and recreated the demo database with every deploy. We needed this because of pre-populated seeds and fixtures, but now that we had personas, we could just keep the database around indefinitely.
00:21:53.760
So, if we don’t reset the database, all the demo functionality still works as intended and is easier to maintain because it has fewer moving parts. We just need to ensure that we run all the necessary schema migrations over time, just like in production.
00:22:12.300
Next, we crossed out the cadence of deployments. The longer the cadence, the more painful it became. If something goes wrong, you have to look into every change since the last successful deploy.
00:22:32.100
If you haven’t deployed in three months, you have to sift through three months of changes. But if you deploy all the time, then when something goes wrong, you only have one or two changes to investigate.
00:22:51.720
So, if it sounds like I’m arguing for continuous integration and continuous deployment, it’s because I am! This is how we build our production apps at Betterment, and it made sense to do the same for demos.
00:23:09.120
Of course, with continuous deployment, you need to operate and monitor things so you can know when something breaks. We enabled Slack alerts and ensured errors flowed into our bug tracker, which feeds into our team’s on-call processes.
00:23:27.600
The last bit we were missing was testing. We wrote tests and added them to our standard test suite, making it possible to toggle the personas mode on and off using an environment variable. These tests would click through an actual product demo starting with the personas page.
00:23:48.300
If a test failed, a developer would see a red PR build, indicating that they broke an actual customer demo or sales pitch, and they couldn’t merge until they made it green.
00:24:09.840
With this, we were running the entire CI/CD infinity loop with our demo application, and instead of push button deploys, we were deploying continuously and benefiting from it, just like in our production environment.
00:24:32.880
This leads to the next iceberg observation: I argue that the demo environment is a kind of production environment. If you’re running live sales demos in front of real audiences, that is a production app; it deserves production-like uptime guarantees.
00:25:01.920
Finally, let’s address the question of ownership. I think we can cross this out without any more slides because we can look at everything we’ve done above. We’re using stateful fakes, which teams already write when developing and testing apps locally.
00:25:19.020
For demo personas, we’re using factories that teams already produce when writing their tests. Then we have a long-lived database that relies on migrations teams are already writing as they build features.
00:25:38.040
Additionally, we’re following the CI/CD process that routes any build failures to the team closest to the change being made. So, the problem of ownership becomes immaterial. The real question is who maintains it?
00:25:53.880
It’s effectively maintained by everyone. The list has become a bit messy, so let’s rewrite it: now we have our demo environment 2.0—an isolated app centered around personas, utilizing a long-lived database and deployed continuously.
00:26:19.380
As a result of all the tools we do in our daily work, it is maintained by everyone. This brings us to our final observation: incentives matter.
00:26:36.540
I know it might sound a little obvious or cliché, but this talk has secretly been about that all along. In 2016, with that first demo environment, we had a team building Betterment's consumer-facing product, focused on their own roadmap and goals, with no reason to maintain a demo environment.
00:27:11.580
The B2B engineering team owned a demo environment for a consumer product they weren't building, and a non-engineering team desperately needed the demo environment but quickly learned that they shouldn't trust it.
00:27:53.820
So, we had three completely misaligned teams with misaligned incentives. But with this new demo environment, when we meet developers where they are with tools they use every day, like WebValve and FactoryBot, and when we codify the needs of our stakeholders with automated tests and alerting, we ensure they have reliable uptime guarantees.
00:28:32.160
We've created a cohesive understanding of ownership and agency among teams, fostering mutual trust and incentives to maintain this environment together. We shipped this in 2020, and as we know, it’s been some time since then.
00:29:02.160
I wanted to share what we’ve done in the years since this release. Firstly, we ended up launching versions of this for our three customer-facing products. Each is a different Rails app with its own set of stateful fakes and personas.
00:29:24.540
Secondly, we launched a version for internal testing purposes, so teams have added countless test personas that Betterment employees can access and use to test various scenarios.
00:29:50.640
We paired this with a developer CLI, allowing devs to generate personas in their local environments. This even replaced user seeds entirely, cutting down the time it takes to reset our local databases.
00:30:15.960
Lastly, we connected a test build of our mobile app to a Rails API backed by the same set of personas, complete with the same loading indicator that takes you straight into a dashboard.
00:30:43.680
Now, talk about aligning incentives! We’re joined by PMs, designers, mobile engineers, and many other stakeholders across the company, all relying on this new demo environment and a shared language of personas to collaborate and iterate on the Betterment product.
00:31:07.560
Internal usage of these demo apps has increased over time, and here we are in 2022. My disembodied face has made it all the way to RailsConf Portland!
00:31:22.680
Betterment still has our demo application, and as you can see, not much has changed. Wait a minute... Yep, that’s right! This is a real demo embedded in my slide deck. It would be ironic if I gave a talk about giving demos without giving at least a little demo.
00:31:49.680
So, we can click over here to view performance, and there’s our stock market simulator still running today. If I logout, we’re right back at our persona picker.
00:32:10.320
If this persona picker is something you'd want for your application, I’m excited to announce that we’ve actually open-sourced it along with our demo framework, called the Gem Demo Mode. It’s available on RubyGems and GitHub.
00:32:31.920
There, you’ll find instructions for setting it up. Basically, it’s a mountable Rails engine, so you just drop it into your app, define a couple of personas, and then launch your app in demo mode.
00:33:04.860
You can pair it with WebValve if you want, but it’s not necessary; you can use FactoryBot or other methods to generate user accounts, and you can utilize your own branding.
00:33:27.180
Before I finish, I’d like to give a shout out to all my teammates over the years who helped make everything you saw possible.
00:33:37.680
That’s all I have for you. I’ve posted a copy of these slides at the link on this slide. If you enjoyed this talk and want to chat more, or if you're interested in learning more about Demo Mode, WebValve, or any of our other open-source gems, come find me afterwards or reach out online.
00:33:56.760
It looks like I have a couple of minutes left for questions, so if anyone has a question, this is where I pause awkwardly and wait to see if you raise your hand.
00:34:08.520
Great question! The question pertains to the overhead of maintaining those fake services with WebValve. My answer is this: with WebValve, you don’t want to build a fully featured version of the collaborating service. Instead, focus on the actual API contract.
00:34:50.520
In practice, those API contracts don’t change much; often, they’re additive. As developers build new features locally, they might add new endpoints, which fits in perfectly with this setup.
00:35:06.480
Did we explore or think about taking the production stack and rerouting it to demo data at the data layer, or at the HTTP layer—this was also considered. Step one is getting to a point where you can test in production, which is something I’m interested in exploring further.
00:35:59.520
Once that’s achieved, demoing in production isn't that far off. However, when optimizing for demo ability, you’re optimizing for consistency in the experience of those giving the demos.
00:36:07.680
That takes careful consideration because I suspect that stubbing as close to that context as possible gives us more control over what sales people can present in a room.
00:36:27.960
I’m over time, so I’ll remain up here for any additional questions. But I don’t want to keep you from lunch, so thank you all, and enjoy the rest of the conference!