Ten Unicode Characters You Should Know About as a Programmer
Ten Unicode Characters You Should Know About as a Programmer
by Jan LelisIn the talk titled "Ten Unicode Characters You Should Know About as a Programmer," Jan Lelis provides an insightful examination of Unicode, emphasizing its significance and complexities for programmers. The discussion is anchored in Ruby, showcasing how its robust support for Unicode facilitates the management of different characters and their corresponding code points.
Key Points Discussed:
- Unicode Overview: Unicode assigns a unique code point to every character, making it essential to understand that multiple code points can represent a single visual character. The Thai character is introduced as an example that illustrates this concept.
- Character Normalization: The demonstration of the character 'Ä' highlights issues with keyboard input and how Ruby's normalization feature allows for transforming characters composed of multiple code points into a single cohesive representation.
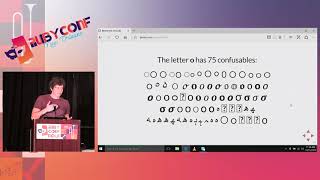
- Confusable Characters: Lelis discusses the confusion that arises between visually similar characters, like different versions of the letter 'I', especially in relation to Turkish capitalizing rules. Programmers face security risks due to these similarities, necessitating tools like the Unicode Confusable gem to identify and manage them effectively.
- Locale-aware Methods: Enhancements in Ruby (post-2.4) allow the use of locale-specific arguments in methods like 'upcase' and 'downcase', improving internationalization support for varying languages.
- Control Characters: The importance of understanding control characters such as newlines is emphasized, including how they behave differently in various operating systems and affect string manipulation in Ruby.
- Legal but Unassigned Code Points: Lelis explains the concept of non-assignable characters within Unicode, where certain code points, like 10FFFF, are legal but not assigned any character. Knowing this can help prevent potential application errors.
- Regular Expressions and Unicode Properties: The use of Unicode properties in Ruby's regular expressions enables developers to match unique and sometimes visually ambiguous characters effectively, enhancing string manipulation capabilities.
In conclusion, Jan Lelis highlights that understanding Unicode intricacies is crucial for programmers, especially when building robust applications. By recognizing confusable characters and learning how to handle them correctly in Ruby, developers can avoid potential pitfalls associated with Unicode data. This knowledge not only enriches a developer's toolkit but also enhances application performance across diverse linguistic settings.