00:00:12.360
My name is Maeve Revels, and this is my very first time speaking at a conference of any kind. Thank you, that actually helps.
00:00:19.920
I'm here today to talk about testing legacy code, and I promise you that it's going to be more fun than it sounds. That's why I made the title boring — so I can set achievable goals for myself.
00:00:32.040
Personally, I only touch legacy code when it's absolutely necessary, which turns out to be basically all the time. I'll be honest: I don't enjoy supporting legacy code, but I really enjoy getting rid of it. It's one of the things that I absolutely love about my job.
00:00:47.579
I use testing to help me do that. So, this talk is going to be very heavy on concepts and light on code. I'm not going to make you read any legacy code today; I'm not even going to make you read hardly any test code. I actually had to cut out most of my code examples for time, but that's okay because the concepts are really the important takeaways here.
00:01:08.880
There are lots and lots of resources out there that can teach you how to write tests. I want to cover how to create the right tests for the right code at the right time when you're working under less than ideal conditions.
00:01:25.920
Let's start with some definitions, because in some ways, legacy code is a little bit like that famous description of obscenity: it's hard to define, but we all know it when we see it. A legacy is something that's handed down from one person to another, and by default, we assume it's something positive. It could be the key to future success, but it’s possible to leave a different kind of legacy—a legacy of pain and suffering.
00:01:50.399
These are some of the words developers use when we talk to each other about legacy code: it's old, outdated, confusing, complicated, brittle, broken, and just plain bad. I created a slide from the text of blog posts that talked about legacy code, and I also asked people for their own definitions. My favorite was: 'Code originally written by someone else that is currently broken in production.'
00:02:09.539
This is fair; a lot of us encounter legacy code for the first time this way. And if you work somewhere long enough, one day, that someone else is going to be you, and you're going to feel terrible about the fact that you don't want to get involved. So, let's talk about how I overcome that impulse.
00:02:39.480
My name is Maeve Revels, and I've been creating new legacy code for 20 years, most of it in Rails. This is my first time speaking at RailsConf, and my first time attending was in 2007. For the past three years, I've been working at Aha, where we have lots of different engineering roles, and they’re hiring for most of them. I'm on the platform team, which is responsible for system infrastructure.
00:03:10.440
In the world of DevOps, I tend to land much more on the dev side. I did feature development for many years before I ended up here, and my specialty is refactoring or replacing parts of the system where we've encountered scalability problems. So, there's a term that describes exactly what I do for a living: Brownfield Development. The first time I heard it, I thought, 'Well, I stepped in some brownfields.'
00:03:53.280
But in reality, just like Greenfield Development, it comes from urban planning. A brownfield is any previously developed land that’s now contaminated with hazardous waste. Any new development on the land must address that contamination and also integrate into the existing environment. So all of that sounds a lot like legacy code.
00:04:25.139
But there's one crucial difference: you can actually see it in this picture of an old rail yard. If you look closely, you can see all that leafy green stuff growing up between the tracks. That's because there are no trains running here anymore. In urban planning, a brownfield property is no longer in use; it's derelict.
00:04:38.580
But in software development, legacy code is still running in production, and that’s one of the reasons why changing it can be so scary. A support burden is one of the defining characteristics of legacy code. Your users depend on this code's behavior, and they’re going to complain when that behavior is unexpected. It's easy to introduce new regressions here because legacy code is often unfamiliar, so we don't understand how it works or if it's fulfilling its intended purpose.
00:05:24.240
We might not know what that purpose was, and whenever we have to change legacy code, we often don't know if we broke something until it blows up in our face in production. Finally, legacy code tends to maximize the cost of change because it's so highly coupled—both internally to itself and externally to its environment.
00:05:56.100
So, it becomes hard to change anything here without potentially affecting everything here. This all adds up to a simple definition—really more of a heuristic—for legacy code: legacy code is any code deployed to production without tests.
00:06:07.800
It doesn't matter whether that was 10 years ago or 10 days ago. Now, I'm not the first person to define it this way. I'm not that brave; I blatantly stole it from Michael C. Feathers' book 'Working Effectively with Legacy Code'. This book was first published in 2004, but a lot of the advice in here is timeless and was a formative experience for me earlier in my career.
00:06:55.199
So, the author takes this definition further than I would. He says code without tests is bad code. Yikes! I mean, I would never say that about your code, sight unseen. But he goes on to clarify: it doesn't matter what the code looks like; bad code is code that we can't change safely, and testing can help.
00:07:41.340
By this definition, you might have deployed some legacy code kind of recently and might be thinking, 'Not my code!' Or, if you're more like me, you're thinking, 'Not my code! Not again!' But once it's in production, untested code quickly acquires many of the same characteristics of legacy code, and this usually happens for reasons completely beyond our control as developers. The one thing we can control is our tests.
00:08:35.280
So let's look at how the cost of new code tends to grow when there are no tests. Maybe our company has a whole go-to-market process for new features. All of these marketing activities are going to increase user engagement, right? But they also increase our support burden. The more users interact with our code, the more edge cases are going to be exposed, which will then require support fixes. And as we make those fixes, the chances that we introduce regressions will go up with the risk of the unknown.
00:09:14.040
At first, the code is very familiar — we just wrote it. Then we start working on something else and we dump that mental context, and one day, we're looking at the 'git blame' for some particularly gnarly code, and we see our own name there. It’s a surprise! This process takes about six months max for me, but even when we still understand the code, there's an increasing cost of change.
00:10:05.940
Let’s step through a common scenario that many of us will encounter or have encountered. This is not a story from my current job, but in a way, it’s kind of the story of every job. Suppose we deploy a new feature after a product manager approves it on staging.
00:10:31.800
This is going to be a few days before the marketing launch because we want to get some early user feedback. We haven't written any tests yet; we know we're going to be iterating on this again, so we're going to wait for things to stabilize. That early feedback leads to code changes we thought it might, and there’s a time crunch to get it done before the launch.
00:11:08.100
So, we don’t have time for testing right now. We'll definitely get to it once the launch is out there. Except that’s when our largest customer starts complaining really loudly. They're unhappy that this new feature does not support their extremely specialized use case.
00:11:51.300
So now, instead of writing tests, we’re spending time hacking in some conditional logic to handle an extremely specialized use case. As we deploy, we cross our fingers and hope we didn't break anything. We broke something, and it was something important. Now this is a production incident, and we need to deploy a fix immediately to restore service.
00:12:40.680
So, we're going to have to delay writing tests once more. All right; everything's finally stable. No one's complaining. It's time to sit down and backfill some test coverage. No, it's not! Now the PM wants to extend this feature with new functionality, and they expect it’s going to be easy because our turnaround has been so impressive up until now.
00:13:11.520
But now we've also approved all of this technical debt, and so all of our changes going forward are going to be very expensive. In the beginning, we started to climb this cost curve because of external factors outside the code. By this point, the code itself is beginning to impede our ability to change it.
00:14:19.500
This curve I keep showing you has a name. It's named after Benjamin Gompertz, an actuary in London who, in 1825, proposed a model for human mortality as a function of age. Eventually, people realized that this class of functions is even more useful for modeling organic growth. The Gompertz growth model shows up in a lot of different disciplines, especially biology and finance—many different things tend to grow and change this way.
00:15:11.040
It makes sense that the risk of maintaining legacy code also fits this model—it grows organically because we created it organically, and then we subject it to our own constraints.
00:15:52.560
Since this model is so widely used, there's been lots of research into optimizing it. In particular, it gives us a really good idea of when we should apply different testing techniques. One possibility is that we could optimize the inputs.
00:16:13.199
Changing the input values for any of these parameters is going to change the model. For example, as I reduce the value of the B parameter, we still approach the same maximum, but I can change how quickly that happens. You probably heard about flattening the curve earlier in the pandemic, and that's because the Gompertz model shows up in epidemiology as well.
00:16:58.740
This is essentially modeling the effect of writing our tests first. It's very effective; it’s great if you can swing it. But legacy code already exists in production without tests by definition, so these inputs are fixed. What else can we do?
00:17:32.880
This is one possibility. This downward zigzag model shows what happens when we iterate on our test coverage. Every time we write tests, the risk of this code will decrease at about the same rate as the original curve was increasing right there. But then the risk starts growing again as the rest of the system continues to change.
00:18:06.600
So if we're diligent about writing more tests every time we touch this area of code, eventually the risk is going to drop to the point where it doesn't feel like legacy code anymore. This is the ideal. Each Gompertz function has an inflection point, and above this line, the growth rate starts to slow down. The closer we are to this threshold, the more effective adding tests will be.
00:18:55.500
This also happens to be the point where most developers start to realize that there's a growing problem with some technical debt in an area of the code. So, they might want to keep an eye on that. Here’s a different model. We have a similar zigzag, but this one doesn’t drop below a certain amount. In this case, we started adding tests later, which means each round of testing is a little bit less effective than in the first model.
00:19:48.960
Because we're seeing less benefit, we're less motivated to iterate as often. The result is that we’re maintaining equilibrium: we’re investing effort, but the code’s not getting any better. There's another threshold here, which is the tipping point where the technical debt became impossible to ignore.
00:20:25.320
So the team starts following the same good scout rule: we're just going to add some tests and leave the code a little bit better every time we touch it. But we're not seeing the same results anymore.
00:21:22.560
Once we recognize that we’re in this model, we've got two choices. We can either test a lot more aggressively; it's still possible to refactor this code into submission, but it’s going to take a lot more intentional effort and planning. We can't just do it along and along as we do the rest of our work.
00:21:52.440
Or we can accept that this code has an ongoing risk, so we’ll write tests every time we need to make changes, but now our goal is just to maintain the status quo. We're not trying to rehabilitate this code, and that's totally a legitimate option depending on what the code is doing and what the priority is relative to the rest of your work.
00:22:25.080
Finally, this upward zigzag model shows what happens when we wait too long to add tests. I've done this a couple of times in my career. At first, it seems like, 'Oh, testing will solve everything!' But it doesn't. Not always.
00:22:56.040
So here we see very little reward and we're trying to avoid touching the code as much as possible because it's so risky. That risk just keeps marching upwards. If you find yourself in this scenario, a rewrite might actually be cheaper than refactoring in place. Not all code is worth saving— I usually try really hard to avoid rewrites.
00:23:34.680
The rest of this talk is going to focus on taking code from the danger zone, where Kenny Loggins lived in the 80s, and moving it down to the comfort zone, where Kenny Loggins lives now. This is not Kenny Loggins; this was actually the first stock photo that came up when I searched for 'soft pants' because we're in the comfort zone.
00:24:22.320
Let’s say we’ve got some wildly dangerous legacy code in front of us—some Kenny Loggins kind of legacy code—and we want to get it into a test harness. Where do we start? How do we test the stuff that matters?
00:25:01.920
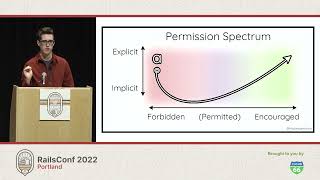
Well, that's actually pretty easy. The only thing that matters is application behavior; it's the only thing that your users care about at the end of the day. This isn't any kind of formal process like behavior-driven development; there's really just one rule to follow here: the test should pass as long as application behavior remains unchanged.
00:25:40.680
Focusing on behavior, as opposed to just inputs and outputs, will naturally influence how we structure our tests and the assertions that we choose to write. There’s a model that I use to help me with all of this; it's called the seam model. If you’re not familiar with this hand tool here, it’s a seam ripper, and it’s usually the first thing you reach for when you want to fix a mistake.
00:26:23.760
In software, the behavioral seam model is based on that same Michael Feathers book I told you about, and it has a couple of key concepts. A seam is a place where we can change behavior without changing code in that place. This is going to be a logical boundary, and this is where we're going to write all of our assertions.
00:27:23.640
Once we find that seam, we need to find the enabling points. An enabling point is a place where we decide to use one behavior or another. This will inform how we set up our test harness. Let’s walk through a few examples.
00:28:18.840
At the application level, users can directly observe behaviors along the seams, and we exercise these behaviors with integration tests. This is the features board in Aha Romance; it's a view for product managers to organize features into releases. You don't have to know anything about how any of this works; you can see there’s a lot going on here. This page was slow to load, and it was my job to make it faster. It also happens to be the most visited page in the entire application.
00:29:20.160
So there was a significant support burden involved, and I wanted to give myself a safety net for refactoring, but I didn't even know where to begin. There’s so much happening. I went looking for smaller seams in this picture, and if we zoom in a little, each colored rectangle here is a feature card. The rendering of each feature card is an application seam unto itself.
00:30:15.720
So there’s a set of behaviors here that will determine the card's final appearance, and there's an enabling point wherever we modify the underlying data. If I update the status of this feature, then the background color of the card should change. If I assign it to another user, then the little avatar should change, and so on.
00:31:13.080
Seams can also exist at the subsystem level; we use functional tests to exercise behavior here. I concentrate on testing seams at this level the most because I do a lot of back-end development.
00:31:23.820
One of my recent projects involved replacing part of the back end for our internal analytics system. We collect analytics data from all over the app in a bunch of different contexts, and they all get sent to this analytics tracker service, which will then enqueue a background job for each event on Rescue using Redis.
00:32:07.560
The job logic that's executed by the workers is not important. All you need to know is that we had encountered a scalability problem with rescuing Redis in this area of the system. So, we decided we'd start asynchronously producing events to a Kafka topic instead.
00:32:43.920
Now, this could be an incredibly risky change. This analytics tracker is used in hundreds of places all over the app, and now we’re risking potentially destabilizing all of them. We decided to run both systems in parallel for a while and then gradually cut over to Kafka, allowing us to roll back easily in case we encountered any unforeseen issues.
00:33:19.320
To control this cutover, we used a feature flag. Feature flags are stored in the database, and they have their own little administrative UI for managing them. There are a lot of subsystem seams in this picture: feature flags are their own little subsystem, Rescue and Redis are a subsystem, and the Kafka producer and the broker form another subsystem.
00:34:17.880
But for my tests, I concentrated on this seam around the analytics tracker and all of the application code that it uses in order to manage background processing. Let’s look at the arrows that cross this seam. Anything that points towards the inside is an enabling point. The feature flag model is where we decide whether we're going to send the data to either Redis or Kafka.
00:35:00.000
All the incoming messages to the analytics tracker are also enabling points, and any decisions we make here will change the shape of the event payload. The places where arrows point outside the seam are where we write assertions about behavior. This is where we're going to ask: Did we send the expected payload to the correct remote system? That's the behavior we really care about testing here.
00:35:56.640
Finally, there are object seams. Object seams are exercised by unit tests, and we can draw seams around the public interface of any object. I tried really hard to find a meaningful example of legacy code that would fit on a slide, but it was so not worth it. Basically, anything you've ever read about unit testing is addressing object seams, and so I'm not going to cover them in detail — other people have done that better.
00:36:44.520
Sandy Metz is one of my favorite authors on this topic. I notice this book has come up like a dozen times during this conference: 'Practical Object-Oriented Design in Ruby' (POODR) has an amazing chapter on testing that covers these kinds of object-level boundaries.
00:37:38.520
We've talked about legacy code. What about legacy tests? Legacy tests break every time you change anything. If you add a fixture, the tests break. You change the name of an unrelated CSS class, the tests break. Sometimes, you just look at it funny, and a test breaks.
00:38:06.720
So how do we prevent this from happening? For answers, I look to Sandy Metz’s book. She says, 'From a practical point of view, changeability is the only design metric that matters. Code that's easy to change is well-designed.' And it's true: everything you've ever learned about designing code was in service of changeability.
00:38:57.300
If you never have to change the code, it doesn’t matter what it looks like; it could be a fugly monstrosity as long as it continues to run in production. But code usually has to change eventually. She goes on to say, 'Efficient tests prove that altered code continues to behave correctly without raising overall costs.' This is key.
00:39:46.260
A well-designed test is a test that’s easy to change, and efficient tests only need to change when the behavior changes. Together, this describes high-value testing. High-value tests prevent the most regressions and have the lowest maintenance costs over time.
00:40:30.360
Tests that fail when there aren’t behavioral changes are low-value tests. Often, when people complain that testing is not really worth the effort, they really mean that maintaining a suite of low-value tests is not worth the effort — and they’re right.
00:41:10.620
So, what is test value? It's a combination of three factors. When we're testing legacy code, our primary motivation is preventing regressions. There are lots of other reasons to write tests, but this adds positive test value, and it’s dynamic, so the test can continue catching more bugs over time.
00:42:09.540
Then, there's the initial cost of getting legacy code into a test harness. This value is fixed; we only have to invest this once. Finally, there's an ongoing maintenance cost to keep the test passing, which will continue to grow over time.
00:43:02.760
What's our unit of measurement? It's time. Bugs prevented is the time that we would have otherwise spent fixing them in production. The initial cost is the time required to understand the code, to identify seams and enabling points, and to create the test harness.
00:43:55.560
Then, the maintenance cost is the time required to change the test code to keep it passing. There's one thing that’s not on here, and that is the time it takes to actually execute the tests. When we're testing legacy code, the cost of changing code is always greater than the cost of executing the tests.
00:44:35.940
Once you get to the point where that's no longer true and you’re really worried about how slow your tests are, congratulations! You don't have legacy code anymore. That’s when you can start to focus on speeding up your test suite. Until then, this is the rule you need to keep in mind.
00:45:32.520
In other words, to prevent regressions, the test must fail when the application behavior changes. To reduce maintenance costs, the tests should pass as long as the behavior remains the same. This also tells us when we can delete a test: if it's easier to fix regressions than to fix the test, the test is really not worth the effort.
00:46:06.870
So how do we write high-value tests? Well, focusing on behavior will get you about 90% of the way there, but it also helps to know a few pro tips.
00:46:43.620
First of all, integration tests test seams at the application level. Sometimes they get a bad rap because they tend to be slow, and testing asynchronous JavaScript is just really difficult. However, they can also be the highest value test in your suite by far, because they catch the most meaningful regressions.
00:47:24.690
The downside is that there is usually a large initial cost. It's much more expensive to set up the test harness because there's more code we need to understand, and there's usually a more complex set of test data that we need to set up. The maintenance costs will depend mostly on our design decisions.
00:48:03.780
If we focus on behavior and keep our tests loosely coupled, then they’ll be more resilient, and we’re going to hold the maintenance costs down. Creating the test harness, as I mentioned, is expensive, and it's going to be one of the hardest parts of any integration test. This initial cost is just going to keep getting worse the longer you try to put it off.
00:49:04.530
One way we can help ourselves and our team is to ensure that for any code we write, we set up at least enough of a test harness that it’s possible to execute a simple happy path integration test, even if you don’t fill in any of the other test coverage. This is going to make it so much easier for the next person who touches that code.
00:49:53.220
To reduce maintenance costs, we need to reduce coupling. One place where tests can become coupled to each other is in shared test data in fixtures or factories. We can get into this frustrating situation where we're just trying to change one attribute on one record, and then five dozen tests start failing somewhere else.
00:50:30.840
Our change to the test data should always be additive in order to avoid this. You can add new records, you can add new attributes to existing records; anything else should be isolated inside a transactional test where it won't affect the rest of your shared test data.
00:51:15.390
But even if we follow that rule, tests can still become coupled through count assertions. When I write assertions, I like it to be a static literal, like this string: expect page to have content for requirements. This keeps the test code really simple; it decouples it from the implementation.
00:51:51.120
I don't have to know anything about how this is implemented in order to write this assertion. This works great except when I'm asserting something that displays a record count. If I use a literal for the expected value here, this test could break every time someone adds a requirements fixture record, even though the behavior didn't actually change.
00:52:38.760
So I always pull my record counts from the data layer instead. It’s a simple thing, but it saves a lot of tedium in terms of ongoing maintenance costs. Abstracting away selectors: most integration testing frameworks allow us to interact with the browser by passing in a CSS selector or XPath selector to a finder, then we get a DOM node, we can inspect it, and we trigger events on it.
00:53:40.140
This is convenient, but it also tends to tightly couple our test code to our implementation. We start writing assertions about the structure of the DOM or the HTML output instead of writing assertions about the application behavior. One way to avoid this is to use any high-level DSL that your testing framework might provide. Capybara provides built-in helpers like 'click on', 'fill in', that read like English descriptions of user behavior.
00:54:33.780
We can use these helpers if we're testing an interface designed for accessibility; they make certain assumptions about what they're going to find on the page, and most legacy code does not fit those assumptions.
00:55:18.600
But we still have the power of abstraction. Here’s an assertion with a moderately complex selector in it; it’s kind of long and dense. It wraps around to a second line, and we have to compare it against the rendered page to even understand what it’s trying to assert.
00:56:08.680
It’s looking for a card field with a flag icon identified by a tooltip 'International expansion' — whatever that means. This assertion describes the output, but what behavior are we really trying to assert here? We can extract this into a more descriptively named method, resulting in: expect page to have goal icon 'International expansion.'
00:57:02.860
Thus, it’s making an assertion that we’ve got this icon representing a goal record that has a particular name. It's much easier to understand, and it also means that we can reuse this method across other tests that might also interact with this UI component. The next time we have to change the underlying implementation, updating the test isn’t nearly as painful.
00:57:44.640
Basically, we want to make our main test logic read like a human language description of the behavior. Now, we’ve got functional tests, which exercise subsystems — units of code working together without going through the full stack.
00:58:18.360
Rails controller tests are often functional tests; tests for service objects are usually functional tests. In terms of test value, functional tests catch a lot of regressions — not quite as many as integration tests. They're cheaper to set up than integration tests because the test harness is usually more focused, but the maintenance costs over time tend to be higher, especially if your tests require mocks or stubs.
00:59:08.880
This is because you've now committed to keeping those updated. Functional tests are especially good for a couple of different situations. One is when you want to exhaustively test behavior that has a lot of edge cases, like error handling or user permission checking.
01:00:07.260
The test harness for an integration test is quickly going to become unwieldy for this purpose, and functional tests are perfect for this kind of assertion. The other time is when you need to stub or mock any external resources. Integration tests don’t always make that easy, and it can be more convenient to write a functional test, which will let you expose more enabling points.
01:00:50.520
Then there are unit tests. A lot of the resources that discuss testing in general are actually talking about unit testing. In particular, both of the books that I recommended today cover unit testing. There's just one problem with unit tests, which becomes apparent in this genre of memes I’ll call 'Too Unit Tests, Zero Integration Tests.'
01:01:45.720
You have these two doors that are both working flawlessly, and then there’s the premature ejector. That's unfortunate, but it's still better than a vortex of microbes every time you wash your hands.
01:02:33.960
There are Dyson hand dryers in the bathrooms here. I think about this every time. My personal favorite is, 'All right, wait for it. Works for me.' Finally, there’s this whole subgenre of corner cases encountered in real life.
01:03:00.960
These are all funny because they ring true. Unit tests are great, but they have one huge weakness: they are just not very good at preventing regressions, and that protection tends to fade over time. Meanwhile, the maintenance costs will also increase.
01:03:49.140
Unit tests are coupled to our implementation at a lower level, and so often they have to change even when the higher-level application behavior that the users care about is the same. So, value doesn’t mean no value. Unit tests are really cheap to set up, and at first, they do catch some regressions, providing a very low-cost way to validate your design as you write new code.
01:04:40.260
That’s why I write unit tests every day! I know I said this talk was for people who dislike testing, but I lied: I write tests first. But long-term, the cost of unit tests can slowly come to dominate the benefits.
01:05:30.660
The most important thing is to only keep unit tests that are useful to you right now. It is never going to get more useful than it is right now. Since it's ephemeral, you don’t have to keep it around just because it might be useful to someone else in the future.
01:06:12.120
As long as you have higher-value test coverage that covers this code, don’t feel bad about deleting old tests. The last thing is you can find literally decades of solid advice about unit testing. It's important to know that you can also apply many of these same techniques to higher-level tests.
01:06:56.640
I learned about the seam model in relation to unit tests, but behavioral seams apply at every level of the application. So, what have we learned today?
01:07:52.560
We learned that legacy code tends to maximize costs, and it's usually for reasons completely beyond our control. Testing is something we can do to minimize costs. For more resilient tests, we should focus on behavior instead of inputs and outputs. We should write high-value tests for our most important code.
01:08:25.920
Finally, the tests should pass as long as application behavior remains unchanged. So, amount of time — but before you go, I just wanted to take a moment to thank my friend and colleague, Zach Schneider.
01:09:05.040
Zach was really passionate about creating quality software, but he was even more passionate about creating an inclusive community. He attended the first version of this talk when I gave it as a lunch and learn at work last year. Afterward, he pulled me aside and gently but emphatically encouraged me to take it to a wider audience.
01:09:50.640
Now, here we are at RailsConf! I know your conference is almost over, but as you go throughout the rest of your day, please keep in mind that you never know when something you say in passing might touch someone else. Be excellent to each other. Thank you!