00:00:12.179
I hope you all are enjoying the Star Trek convention! Thank you for the giggles. I actually arrived on Saturday night and am staying at the DoubleTree. I noticed there is a Halloween convention happening. Did anyone see it? I asked the reception about it, and apparently, they were celebrating Friday the 13th, which is kind of cool. But yeah, this is RailsConf, and we're here to talk about queuing theory.
00:00:49.620
This is my first live in-person talk on stage, so I'm super nervous. Wow, thank you! I'm Justin Bowen; I go by 'tons of fun' on GitHub and 'tons of fun 1' on Twitter. I'm a CTO consultant at Silicon Valley Software Group, where we assist early-stage to large enterprises with their scaling problems, whether those are technical or related to human scaling issues. I also serve as the Director of Engineering at Insigh Surgical AI, where we deliver real-time computer vision of surgical objects in operating rooms for patient safety. So it's pretty cool!
00:01:47.040
So, what does Star Trek have to do with queuing? Personally, Star Trek was a big inspiration for me. Watching LeVar Burton as Geordi La Forge and Chief O'Brien really inspired me to become a software engineer. Although I've been told not to say that unless I have an engineering degree, which I don't. But anyway, let's make it so and start talking about queuing.
00:02:28.440
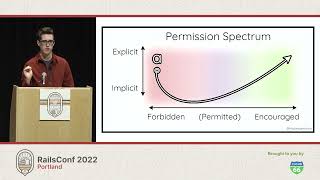
We're going to be talking about transporters. Chief O'Brien was the transporter operator for transporter room three on the Enterprise, his favorite transporter room. If you watch Deep Space Nine, he also liked transporter pad C. If you're familiar with the original series, you might know the phrase "Beam me up, Scotty." O'Brien is not Scotty, but he is Irish, not Scottish! The Q are an extra-dimensional being and society introduced to us in The Next Generation (TNG). At the beginning of the series, Q challenges Picard, making him question whether humans should explore the galaxy.
00:03:20.959
The Q can manipulate time and space and are referred to as the Q Continuum, which is the place they come from. We're going to discuss transporters and capacity planning. How do transporters relate to queues? The USS Enterprise in The Next Generation had a crew complement of about a thousand, while the original series' Constellation-class Enterprise had around 300. So, this is a Galaxy-class starship. The number of transporter rooms on a starship is determined by how many beam-outs they can perform in a specific time frame to evacuate the ship or station.
00:04:30.180
If we were Q, we could just snap our fingers, and everyone could be beamed to safety. In one episode, Q even beamed an entire colony off a planet in one go. He once launched the Enterprise to the other side of the galaxy—spoiler alert! I know it's been like 30 years. That's how they introduced the Borg. But as humans, we don't have the powers of the Q—we have to queue. Queuing essentially means waiting. Waiting in line is something we're all familiar with; we waited in line to get our badges here, and I waited in line at the airport. We'll be discussing queues, where the unit of work is the job or request, the servers (in this case, the transporters), and the service time—how long it takes to beam someone out.
00:05:53.419
A transporter, in this depiction, can transport out six people at a time, and the beam-out time is about five seconds. To get all of the crew members out in two minutes, that means we need to beam out 500 crew members per minute or about 8.3 crew members per second. If we need to beam out 8.3 crew members per second, how do we define the rate of transport and understand the offered traffic? This is where Little's Law comes into play. Little's Law states that, based on service time and the rate of traffic, we can determine the offered traffic.
00:07:16.680
In our case, with 8.3 beam outs per second, and a service time of five seconds, we end up with an offered traffic of 41.5. This is the time it takes to process the work multiplied by the average rate of arrival. If we have an offered traffic of 41.5 beam outs and a service time of five seconds, we'll need more than just one transporter to get everyone out safely and on time.
00:07:42.600
In this scenario, if we have 41.5 crew members to beam out per second, we need to consider that offered traffic and how we service it. Again, service time multiplied by the rate of jobs gives us the offered traffic. If we have one transporter on the Enterprise, it would take a long time to process through a thousand crew members. How do we determine how long that might take? We could scale up and simply add more transporters and see how it goes. But there are other tools we can utilize in the toolkit of queuing theory.
00:08:26.460
One interesting discovery I made during my reading was the USE method, originally put together by Brendan Gregg at Intel. USE stands for utilization—services used divided by services available—saturation, which refers to resource consumption being overloaded, and errors, which denote wasted resources. When processing jobs that only generate errors, that prevents other jobs from succeeding. We can describe utilization as the offered traffic divided by parallelism.
00:09:06.780
So, if we have an offered traffic of 41.5, what parallelism is required to beam off a thousand crew members? With a single transporter pad—not utilizing the full six pads—the utilization would be around one hundred thousand percent, leading to saturation. Since we are over a hundred percent, people must wait, and waiting is not ideal, especially during emergencies. One transporter room can handle six beam-outs at a time, taking five seconds, meaning we would still be at sixteen thousand percent utilization. It's an improvement, but we are still significantly over-saturated.
00:10:05.279
We want to reduce that utilization down to one hundred percent. Saturation occurs when utilization is at or near one hundred percent, meaning resources are overloaded. This issue leads to exponential delays, as the closer utilization approaches one hundred percent, the more the queuing latency will be affected.
00:10:23.740
Queuing latency refers to the time it takes to process the next job in the queue. As we've noted, it takes about five seconds to process an email. Queuing delay pertains to how long it takes to complete that last transport. If we're only using one transporter room, for example, it will take an estimated 833 seconds—or about 14 minutes—to process all crew members. This delay becomes an issue during emergencies, highlighting the need to scale up to avoid people stacking up and waiting.
00:11:08.339
Now, let's discuss parallelism versus concurrency. Parallelism occurs when two tasks can be completed simultaneously. In our transporter example, we've seen six people beamed out at a time in a five-second window. This represents a parallelism of six. In software terms, this translates to utilizing six cores simultaneously or six Ruby processes working together to process tasks. Parallelism results in higher throughput. On the other hand, concurrency does not always provide parallelism, which can be trickier to visualize.
00:12:10.440
Concurrency involves tasks starting and ending around the same time, meaning work is being done concurrently but not necessarily simultaneously. To clarify, let's use a different analogy rather than the previous discussions.
00:12:42.480
Vertical scaling can be understood as simply making a transporter larger or increasing the number of pads. This is akin to scaling a server to have more CPU cores. For instance, a small ship might have four transporters, while a massive ship could have eight or even sixty-four. You can provision larger instances on AWS, but it’s important to consider specific vertical scaling or horizontal scaling methods. One interesting concept is that of a scaling quantum, which signifies the amount of utilization you gain every time you scale horizontally, as discussed in Nate Berkopec’s book 'Speed Up Your Rails Apps'. A scaling quantum indicates the efficiency of increasing a resource while also considering overall cost.
00:14:00.600
Thus, if you're scaling a big ship, such as one with sixty-four transporters, you'd want adequate offered traffic to justify the addition. Overscaling can lead to wasted resources and high expenses, and while larger companies may not be as concerned with billable costs, startups often worry about expenses as they grow. For example, complex projects like computer vision may require an 8 GPU server with 96 cores, which will surely be deployed into hospitals. I just received one that is water-cooled, and I've never encountered anything like it before.
00:15:36.300
These GPUs outdo the RTX 3090s, being the Quadro A6000s—very expensive equipment! Ensuring that we don't underutilize these resources is crucial, as each GPU is over a hundred thousand dollars. You must consider horizontal scaling as you add ships or instances to handle more traffic. But each time new instances are scaled, it's crucial to monitor how many connections your database can handle to avoid overwhelming the database connection pool.
00:16:49.740
Stepping back from the Star Trek analogy, let's talk about the differences between parallelism and concurrency. In a chart with multiple processes, say thread one and thread two are in the same process while process one and two are separate Ruby application instances. Processes one and two would work simultaneously, reducing overall time. If thread one consumes all CPU power while thread two has to wait for CPU access, we will not see any added throughput from concurrency due to a shared lock.
00:18:00.000
This phenomenon relates to the Ruby virtual machine (VM) and the Global Interpreter Lock (GIL). The GIL allows only one set of instructions to execute at a time; while one thread is using the VM, other threads remain idle. The threads that aren't using the Ruby GIL are effectively waiting until they can gain access to process their tasks. Although networking tasks may operate without blocking the GIL, but only when they're not being executed on the VM. This means that threads can send requests and be freed from their lock, allowing the CPU to process other instructions.
00:19:55.200
You can obtain partial parallelism through concurrency; you may find that one thread might be waiting on a network request while another thread picks up the process. So, even if you can't handle all threads running simultaneously, you may still achieve some time savings. It's important to recognize how high levels of concurrency might affect your system, especially when considering increasing parallelism becomes easier. Just add more ships to your fleet or deploy additional servers. Every time you deploy server instances, you get a new application to work with.
00:21:38.500
However, keep in mind the memory footprint as each process loads the Rails application into memory. If you're vertically scaling while running multiple processes within a shared instance, ensure you have enough memory resources and that they don't overutilize the infrastructure. Similarly, while concurrency can optimize performance under the right conditions, it too isn't free. To realize the benefits of concurrency, you want to focus on waiting times and utilize infrastructure wisely.
00:23:35.979
For instance, while waiting on IO (like waiting for a web request, network response, or third-party API), you may want to dial up your concurrency options to optimize your throughput. Revisiting the concept of IO wait and understanding when to take advantage of concurrency can enhance your performance in application management.
00:25:13.800
It's imperative to grasp practical applications that I haven't covered thoroughly to help optimize application performance. As such, I urge everyone to benchmark and optimize your application performance regularly.
00:25:47.040
Now, about the queuing concept, we've addressed how distributed processing can be achieved with Sidekiq. Utilizing Redis as a centralized queue for background jobs helps make more efficient use of resources, especially when balancing job latency. If jobs with similar latencies are processed in synchronized queues, it balances job duration and allows threads to focus on effectively managing high-priority jobs without blocking progress on shorter-duration tasks.
00:27:59.880
Moreover, while a finer look at queuing might involve the Puma web server—such architecture inherently means that every process has its own request queue. This setup indicates users can benefit only from the threads that are running and that processes must consider the random nature of dynamic routes that can lead to queues building randomly.
00:29:36.360
In closing, it's essential to grasp why we queue up—it's not just for profit. Indeed, ensuring customer satisfaction and offering timely user experiences hinges heavily on minimizing wait times. Long wait times can lead to frustration and negative experiences, which we should proactively avoid. Remember to monitor your application, adjust your concurrency levels accordingly, and be considerate of the system footprint.
00:29:58.399
All good things must come to an end, and I appreciate you all for attending my talk. Lastly, I want to mention that my father, who passed away earlier this year, inspired me as well. When my talk was accepted, I was in the ICU, wrestling with the decision to cancel. Yet, thanks to support from family and friends, I am grateful for this opportunity. Thank you all for being here!